编程需要下载什么软件/关键词优化公司哪家好
腾讯课堂 | Python网络爬虫与文本分析(戳一戳)~~
一、概述
其实Excel合并这个需求,应该是一个极为普遍的需求了。今天我们就利用Python完成“Excel合并(拆分)” 操作,具体如下:
- ① 将多个Excel表,合并到一个Excel中(每个Excel中只有一个sheet表);
- ② 将多个Excel表,合并到一个Excel中(每个Excel中不只一个sheet表);
- ③ 将一个Excel表中的多个sheet表合并,并保存到同一个excel;
- ④ 将一个Excel表,按某一列拆分成多张表;
二、知识点讲解
其实完成这些操作,涉及到了太多的知识点,因此在讲述上述这个知识点以前,我们要带大家复习一些常用的知识点。
- ① os模块常用知识点讲解;
- ② pandas模块常用知识点讲解;
- ③ xlsxwriter模块常用知识点讲解;
- ④ xlrd常用知识点讲解;
1. os模块知识点讲解
对于os模块,我们主要讲述os.walk()、os.path.join()等知识点。
1.1 os.walk()
对于这个知识点,我们需要说明以下几点:
- os.walk()的返回值是一个生成器(generator),我们需要循环遍历它,来获取其中的内容;
- 每次遍历,返回的都是一个三元组(path, dirs, files);
- path:返回的是当前正在遍历的这个文件夹的,本身路径地址;
- dirs:返回的是该文件夹中所有目录的名字(不包含子目录),有多少个都以“列表”返回;
- files:返回的是该文件夹中所有的文件(不包含子目录下的文件),有多少个都以“列表”返回;
如果说,有一个如图所示的文件夹。
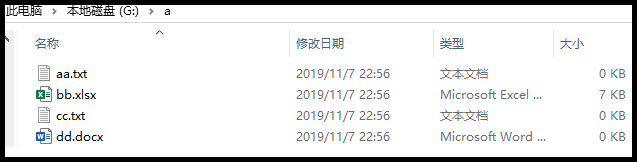
利用下方的代码,我们可以得到什么结果呢?
pwd = "G:\\a"
print(os.walk(pwd))
for i in os.walk(pwd):
print(i)
for path,dirs,files in os.walk(pwd):
print(files)```
结果如下:
0x0000029BB5AEAB88>
('G:\\a', [], ['aa.txt', 'bb.xlsx', 'cc.txt', 'dd.docx'])
['aa.txt', 'bb.xlsx', 'cc.txt', 'dd.docx']1.2 os.path.join()
这个函数,主要用于将多个路径组合后返回,超级简单,就不做过多阐述。
path1 = 'G:\\a'
path2 = 'aa.txt'
print(os.path.join(path1,path2))
结果如下:
G:\a\aa.txt
2. pandas模块知识点讲解
由于是需要利用Pandas进行Excel的合并,因此我们要学会,如何利用Pandas进行数据的纵向合并。
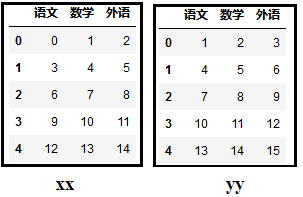
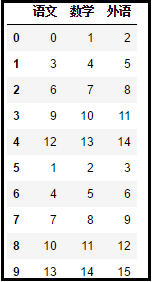
我们先创建2个数据框(DataFrame):
import numpy as np
xx = np.arange(15).reshape(5,3)
yy = np.arange(1,16).reshape(5,3)
xx = pd.DataFrame(xx,columns=["语文","数学","外语"])
yy = pd.DataFrame(yy,columns=["语文","数学","外语"])
print(xx)
print(yy)
效果如下:
接着,可以利用Pandas中的concat()函数,完成纵向拼接的操作。
- pd.concat(list)中【默认axis=0】默认的是数据的纵向合并;
- pd.concat(list)括号中传入的是一个列表;
- ignore_list=True表示忽略原有索引,重新生成一组新的索引;
- 或者直接可以写成z = pd.concat([xx,yy],ignore_list=True);
concat_list = []
concat_list.append(xx)
concat_list.append(yy)
z = pd.concat(concat_list,ignore_list=True)
print(z)
效果如下:
3. xlsxwriter模块知识点讲解
xlsxwriter模块一般是和xlrd模块搭配使用的, xlsxwriter:负责写入数据, xlrd:负责读取数据。接下来,我们分别对这两个库的常见用法,进行介绍。
1)如何创建一个“工作簿”?
import xlsxwriter
# 这一步相当于创建了一个新的"工作簿";
# "demo.xlsx"文件不存在,表示新建"工作簿";
# "demo.xlsx"文件存在,表示新建"工作簿"覆盖原有的"工作簿";
workbook = xlsxwriter.Workbook("demo.xlsx")
# close是将"工作簿"保存关闭,这一步必须有,否则创建的文件无法显示出来。
workbook.close()
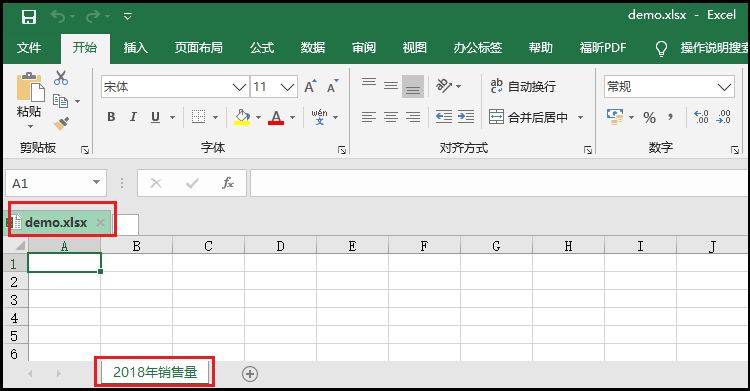
2)如何添加一个“Sheet工作表”
我们知道,一个Excel文件就是一个Excel工作簿,而每一个工作簿中,又有很多的“Sheet工作表”。接下来,我们如何用代码实现这个操作呢?
import xlsxwriter
workbook = xlsxwriter.Workbook("cc.xlsx")
worksheet = workbook.add_worksheet("2018年销售量")
workbook.close()
效果如下:
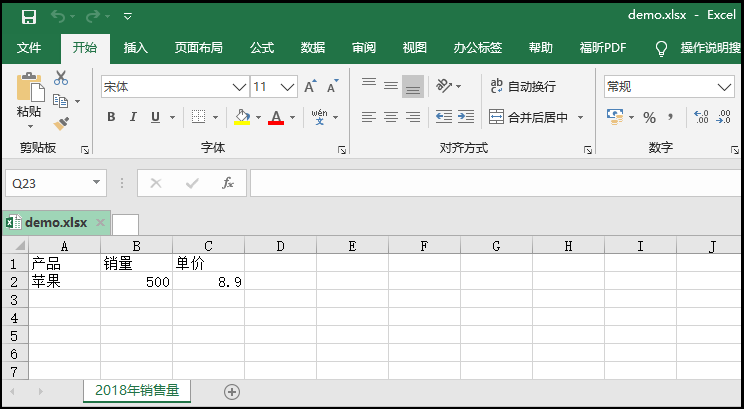
3)如何向表中插入数据呢?
import xlsxwriter
# 创建一个名为【demo.xlsx】工作簿;
workbook = xlsxwriter.Workbook("demo.xlsx")
# 创建一个名为【2018年销售量】工作表;
worksheet = workbook.add_worksheet("2018年销售量")
# 使用write_row方法,为【2018年销售量】工作表,添加一个表头;
headings = ['产品','销量',"单价"]
worksheet.write_row('A1',headings)
# 使用write方法,在【2018年销售量】工作表中插入一条数据;
# write语法格式:worksheet.write(行,列,数据)
data = ["苹果",500,8.9]
for i in range(len(headings)):
worksheet.write(1,i,data[i])
workbook.close()
效果如下:
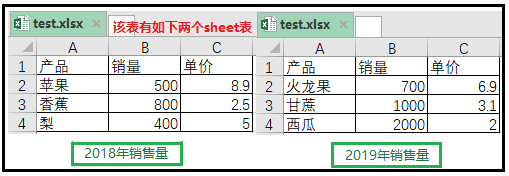
4. xlrd模块知识点讲解
这里有一个工作簿“test.xlsx”,该文件中有两个“Sheet工作表”,分别命名为“2018年销售量”、“2019年销售量”,如图所示。
1)如何打开一个“工作簿”?—>open_workbook()
# 这里所说的"打开"并不是实际意义上的打开,只是将该表加载到内存中打开。
# 我们并看不到"打开的这个效果"
import xlrd
file = r"G:\Jupyter\test.xlsx"
xlrd.open_workbook(file)
结果如下:
0x29bb8e4eda0>2)如何获取一个工作簿下,所有的“Sheet表”名?—>sheet_names()
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
fh.sheet_names()
结果如下:
['2018年销售量', '2019年销售量']
3)如何获取所有“Sheet表”的对象列表?—>sheets()
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
fh.sheets()
结果如下:
[0x29bb8f07a90>, 0x29bb8ef1390>]我们可以利用索引,获取每一个sheet表的对象,然后可以针对每一个对象,进行操作。
fh.sheets()[0]
0x29bb8f07a90>
fh.sheets()[1]0x29bb8ef1390>4)如何获取每个Sheet表的行列数?—>nrows和ncols属性
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
fh.sheets()
fh.sheets()[0].nrows # 结果是:4
fh.sheets()[0].ncols # 结果是:3
fh.sheets()[1].nrows # 结果是:4
fh.sheets()[1].ncols # 结果是:3
5)按行获取,每个Sheet表中的数据—>row_values()
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
sheet1 = fh.sheets()[0]
for row in range(fh.sheets()[0].nrows):
value = sheet1.row_values(row)
print(value)
效果如下:

三、案例讲述
1. 将多个Excel表,合并到一个Excel中(每个Excel中只有一个sheet表)
有四张表,图示中一目了然,就不做过多解释。
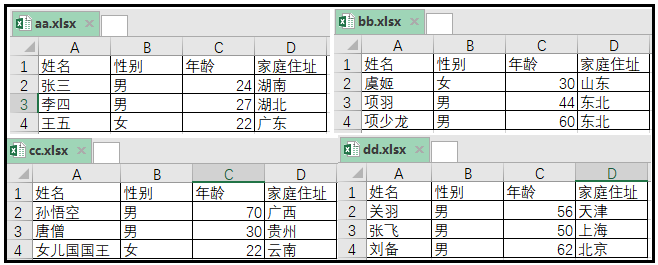
实现代码如下:
import pandas as pd
import os
pwd = "G:\\b"
df_list = []
for path,dirs,files in os.walk(pwd):
for file in files:
file_path = os.path.join(path,file)
df = pd.read_excel(file_path)
df_list.append(df)
result = pd.concat(df_list)
print(result)
result.to_excel('G:\\b\\result.xlsx',index=False)
结果如下:
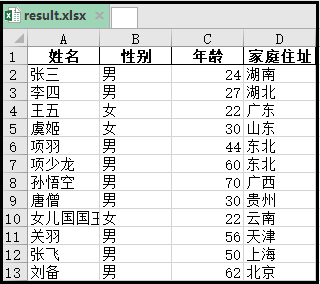
2. 将多个Excel表,合并到一个Excel中(每个Excel中不只一个sheet表)
有两个工作簿,如图所示。一个工作簿是pp.xlsx,一个工作簿是qq.xlsx。工作簿pp.xlsx下,有sheet1和sheet2两个工作表。工作簿qq.xlsx下,也有sheet1和sheet2两个工作表。
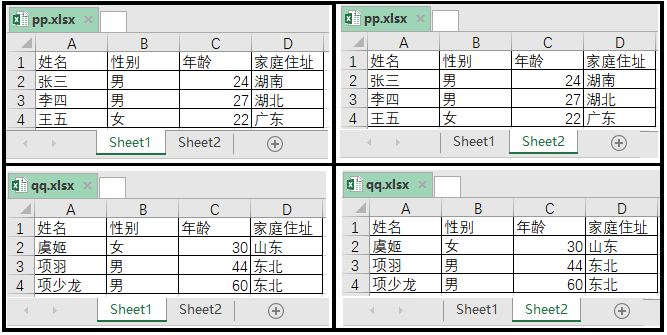
实现代码如下:
import xlrd
import xlsxwriter
import os
# 打开一个Excel文件,创建一个工作簿对象
def open_xlsx(file):
fh=xlrd.open_workbook(file)
return fh
# 获取sheet表的个数
def get_sheet_num(fh):
x = len(fh.sheets())
return x
# 读取文件内容并返回行内容
def get_file_content(file,shnum):
fh=open_xlsx(file)
table=fh.sheets()[shnum]
num=table.nrows
for row in range(num):
rdata=table.row_values(row)
datavalue.append(rdata)
return datavalue
def get_allxls(pwd):
allxls = []
for path,dirs,files in os.walk(pwd):
for file in files:
allxls.append(os.path.join(path,file))
return allxls
# 存储所有读取的结果
datavalue = []
pwd = "G:\\d"
for fl in get_allxls(pwd):
fh = open_xlsx(fl)
x = get_sheet_num(fh)
for shnum in range(x):
print("正在读取文件:"+str(fl)+"的第"+str(shnum)+"个sheet表的内容...")
rvalue = get_file_content(fl,shnum)
# 定义最终合并后生成的新文件
endfile = "G:\\d\\concat.xlsx"
wb1=xlsxwriter.Workbook(endfile)
# 创建一个sheet工作对象
ws=wb1.add_worksheet()
for a in range(len(rvalue)):
for b in range(len(rvalue[a])):
c=rvalue[a][b]
ws.write(a,b,c)
wb1.close()
print("文件合并完成")
效果如下:
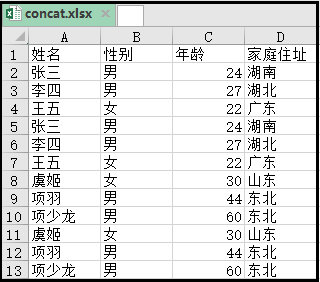
3. 将一个Excel表中的多个sheet表合并,并保存到同一个excel
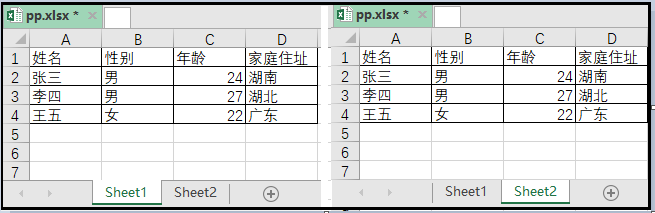
实现代码如下:
import xlrd
import pandas as pd
from pandas import DataFrame
from openpyxl import load_workbook
excel_name = r"D:\pp.xlsx"
wb = xlrd.open_workbook(excel_name)
sheets = wb.sheet_names()
alldata = DataFrame()
for i in range(len(sheets)):
df = pd.read_excel(excel_name, sheet_name=i, index=False, encoding='utf8')
alldata = alldata.append(df)
writer = pd.ExcelWriter(r"C:\Users\Administrator\Desktop\score.xlsx",engine='openpyxl')
book = load_workbook(writer.path)
writer.book = book
# 必须要有上面这两行,假如没有这两行,则会删去其余的sheet表,只保留最终合并的sheet表
alldata.to_excel(excel_writer=writer,sheet_name="ALLDATA")
writer.save()
writer.close()
效果如下:
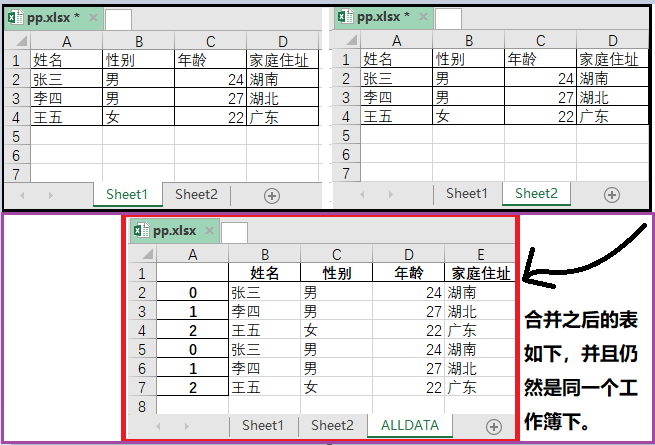
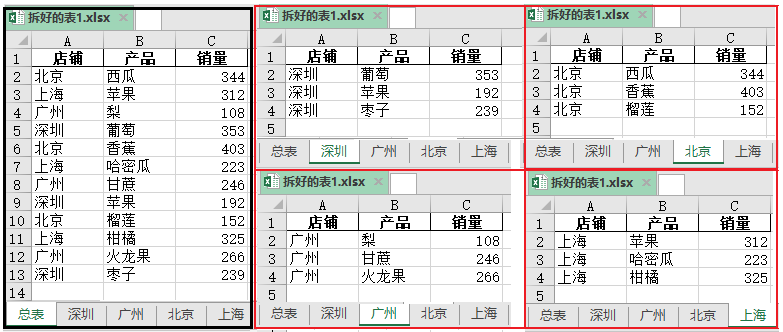
4. 将一个Excel表,按某一列拆分成多张表
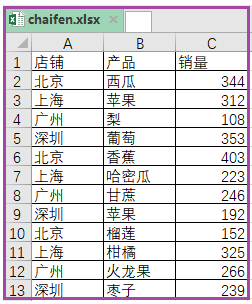 实现代码如下:
实现代码如下:
import pandas as pd
import xlsxwriter
data=pd.read_excel(r"C:\Users\Administrator\Desktop\chaifen.xlsx",encoding='gbk')
area_list=list(set(data['店铺']))
writer=pd.ExcelWriter(r"C:\Users\Administrator\Desktop\拆好的表1.xlsx",engine='xlsxwriter')
data.to_excel(writer,sheet_name="总表",index=False)
for j in area_list:
df=data[data['店铺']==j]
df.to_excel(writer,sheet_name=j,index=False)
writer.save() #一定要加上这句代码,“拆好的表”才会显示出来
效果如下:
近期文章
Python网络爬虫与文本数据分析bsite库 | 采集B站视频信息、评论数据rpy2库 | 在jupyter中调用R语言代码tidytext | 耳目一新的R-style文本分析库reticulate包 | 在Rmarkdown中调用Python代码plydata库 | 数据操作管道操作符>>plotnine: Python版的ggplot2作图库七夕礼物 | 全网最火的钉子绕线图制作教程读完本文你就了解什么是文本分析文本分析在经管领域中的应用概述 综述:文本分析在市场营销研究中的应用plotnine: Python版的ggplot2作图库小案例: Pandas的apply方法 stylecloud:简洁易用的词云库 用Python绘制近20年地方财政收入变迁史视频 Wow~70G上市公司定期报告数据集漂亮~pandas可以无缝衔接Bokeh YelpDaset: 酒店管理类数据集10+G “分享”和“在看”是更好的支持!