网站建设属于移动互联网/南宁百度首页优化
1.欠拟合,过拟合和模型的容量
1.1基本概念
机器学习的目标是使算法在“先前未观测到的新输入上”表现良好,这种能力成为泛化。通常我们希望算法在测试集上具有小的泛化误差。这个泛化误差体现在测试集上的测试误差。
前提:我们的假设是每个数据集中的样本都是相互独立的,并且测试集和训练集是同分布的。
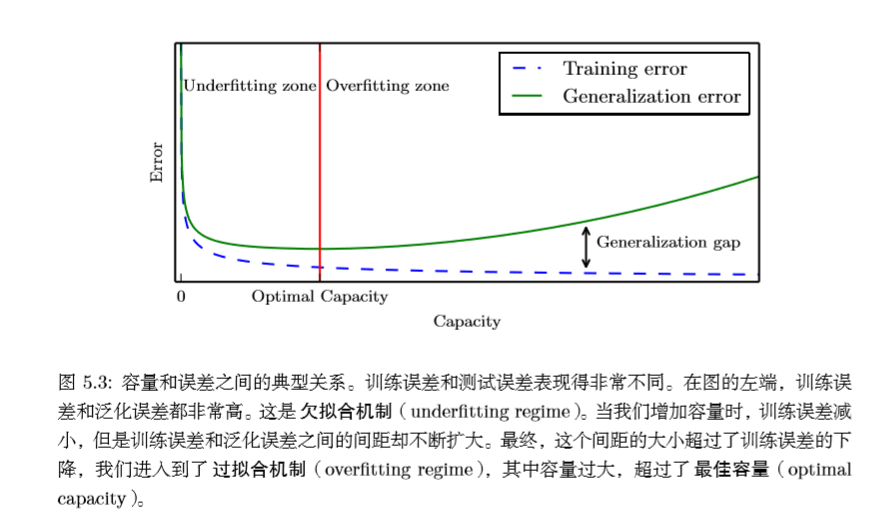
机器学习算法中,我们的处理过程为:
(1)降低训练误差;
(2)缩小训练误差和测试误差的差距;
欠拟合:模型没有获得足够低的训练误差;
过拟合:训练误差和测试误差的差距太大。
模型的容量:指其拟合各种函数的能力。容量低的模型很难拟合训练集;容量高的模型可能会过拟合,因为记住了不适用于测试集的训练集性质。
“奥卡姆剃刀”:在同样能够解释已知观测现象的假设中,选择最简单的那个。
偏差:偏差度量了偏离真实函数或者参数的误差期望。
方差:方差度量了数据上任意特定采样可能导致的估计期望的偏差。

增加容量会增大方差,降低偏差。
1.2解决欠拟合的方法
个人认为,(1)可以增大模型容量,模型复杂度。(2)增大训练的迭代次数,使之充分训练。
1.3解决过拟合的方法
1.数据增强
2.参数范数惩罚正则化
对目标函数J添加一个参数范数惩罚项,限制模型的学习能力。神经网络中通常只对权重做惩罚而不对偏置做惩罚。因为每个偏置仅控制一个单变量,意味着它不会导致太大的方差。此外正则化偏置参数可能会导致明显的欠拟合。
(1)L2参数正则化
(公式自己查或者看笔记)
L2正则化之后,参数在显著减小目标函数的方向上的分量保留完好,在无助于目标函数减小的方向上的分量会衰减掉。
(2)L1参数正则化
相比L2正则化,L1正则化会产生更加稀疏的解,即最优解中的一些参数为0.
3.提前终止(训练)
4.参数共享
参数惩罚是正则化参数使其彼此接近的一种方式,参数共享则强迫某些参数相等。
CNN中使用,显著降低了模型的参数量。
5.Bagging和其他集成方法
机器学习中常用,模型平均策略。
6.dropout
训练的集成包括所有从基础网络除去非输出单元后形成的子网络。即在训练过程中随机性低屏蔽一些神经元,相当于训练了多个子网络,在使用时再将它们结合成为完整的网络。
(1)取平均的作用: 先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
7.神经网络中使用BN层