荆州做网站/营销培训视频课程免费

IoTDB应用
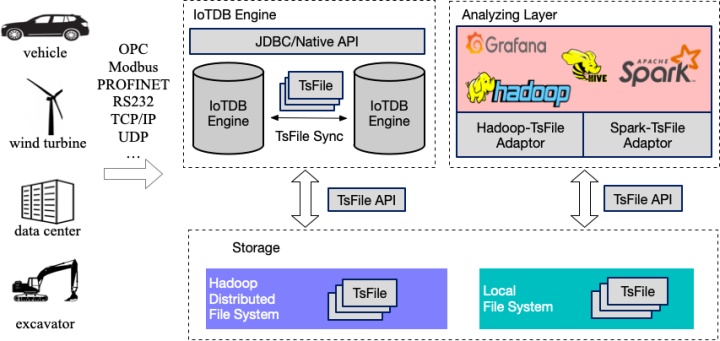
灰色部分是IotDB的组件,数据可以通过JDBC/Native API 写入IoTDB,多个IoTDB之间的数据通过TsFile Sync来实现同步,例如边缘站点收集数据生成并TsFile后,可以定期将TsFile同步到云上的IoTDB。IotDB Egine通过TsFile的API讲数据写成TsFile的格式,支持的存储方式有本地存储和HDFS。TsFile支持hadoop、Hive、Spark直接进行大数据分析。可以看到IoTDB的核心部分就是TsFile,承载了IoTDB多个实例间的数据同步和数据分析。
IoTDB的架构
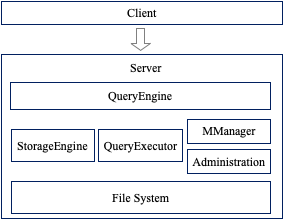
IoTDB使用客户端服务器的架构,客户端向服务端发起读或写的请求,服务端将请求转发到相应的模块,例如写入请求转发到StorageEgnine, 读请求转发到QueryEngine,其他还有schema manager 和Administration模块。
TsFile
TsFile是IOTDB的核心部分,下面介绍文件的格式和读写流程
文件格式
下面是TsFile的结构图
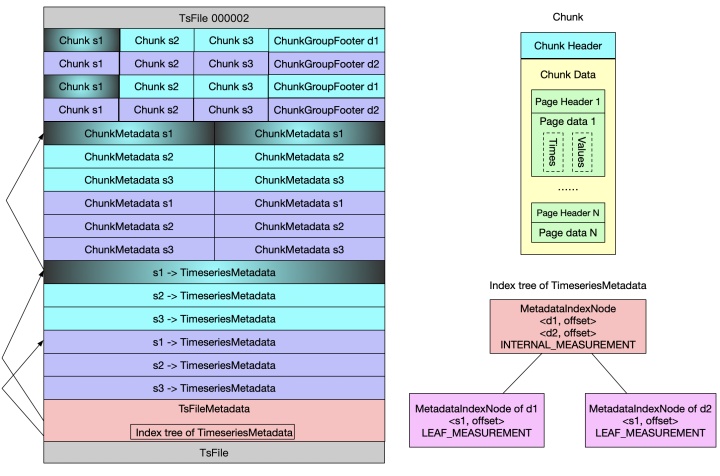
上图的文件包含了两个设备d1、d2。每个设备包含了三个measurements:s1、s2、s3。一共有6条时间线。每条时间线包含2个chunk。
MetaData
一个TsFile中包含了三个部分metadata
- ChunkMetaData 记录了时间线的Chunk的起始地址,数据类型,统计信息和指标名
- TimeSeriesMetaData 记录了ChunkMetaData 列表的起始地址,ChunkMetaData的数量,指标名,统计信息,数据类型。
- 第三部分是TsFileMetaData,是一个二叉树结构,记录了设备和measurements的结构
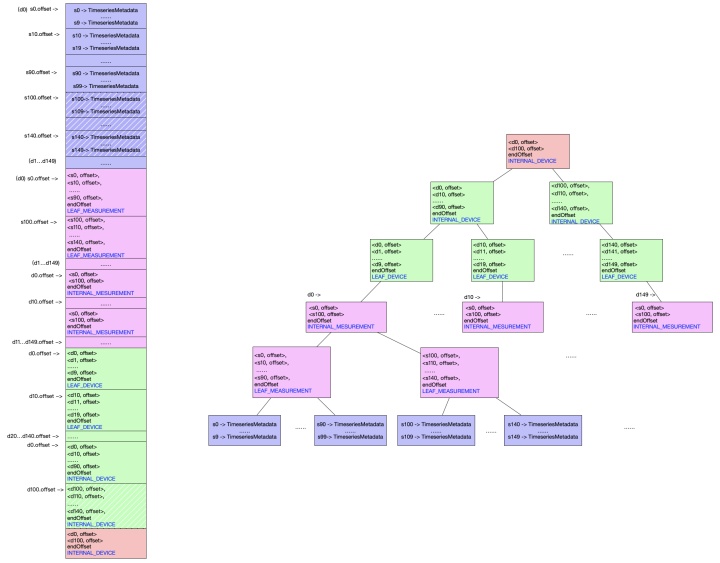
如上图所示,设备分为INERNAL_DEVICE,LEAF_DEVICE,指标也分为INTERNAL_MEASEUMENT,LEAF_MEASEUMENT。这些层级关系方便表达现实世界中设别的层级关系,也便于快速查询。
DATA
数据部分存储了大量的ChunkGroup,每一个ChunkGroup表示一个设备的数据。每个ChunkGroup中包含多个chunk和一个footer。
chunk存储一个指标一段时间的数据,chunk中包含了ChunkHeader和若干page。chunkHeader中记录了指标名、数据大小、压缩类型、编码类型、page数量。一个chunk中的数据是按照时间升序排序的。
page存储chunk中的数据,包含一个pageheader和编码过的时序数据。page header记录压缩前的数据和压缩后的数据(如果有),和统计数据。
ChunkGroupFooter 记录了设备名,数据大小和chunk的数量。
写过程
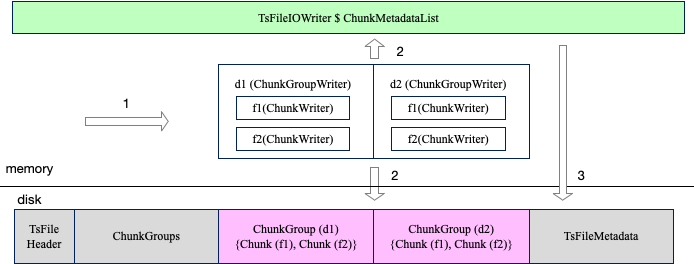
读过程分为三个步骤
1.写内存缓冲区
TsFile有两个写数据接口
// 写一个设备一个时间点的多个指标
TsFileWriter.write(TSRecord record)
// 写一个设别多个时间点的多个指标
TsFileWriter.write(Tablet tablet)当写数据接口被调用后,数据会被分配到设备对应的ChunkGroupWriter,设备对应的指标数据会分配到指标对应的ChunkWriter。ChunkWriter负责对数据进行编码(例如gorilla)及生成page。
2. 持久化ChunkGroup
当内存中的数据大小达到一定大小时,会调用TsFileWriter.flushAllChunkGroups()方法将内存中的所有设备的所有数据存储到磁盘上的TsFile。
3. 关闭文件
基于内存中的元数据信息,会生成TsFileMetadata并且追加到文件的末尾。
读过程
读过程比较复杂,参考 https://iotdb.apache.org/zh/SystemDesign/TsFile/Read.html