北京公司请做网站工资/南宁关键词优化软件
1.按以下要求配置集群
设置文件副本数为3,datanode每隔2秒向namenode心跳一次,namenode每隔10秒钟检查datanode的状态,每隔3分钟删除多余副本,每隔10分钟合并fsimage与edits,每隔2分钟检查是否满足合并条件。
- #zkServer.sh start 三个节点 hadoop01~03
- #start-dfs.sh 任意一个节点 hadoop01
- #start-yarn.sh 两个节点 01,02
- #mr-jobhistory-daemon.sh start historyserver hadoop03节点
- vi /usr/apps/hadoop/hadoop-2.6.4/etc/hadoop/hdfs-site.xml
修改并增加以下部分 用来设置文件副本数为3,datanode每隔2秒向namenode心跳一次,namenode每隔10秒钟检查datanode的状态
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name> 2.x
<value>1000</value> 毫秒
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>2</value> 秒
</property>
namenode每隔10秒钟检查datanode的状态,每隔3分钟删除多余副本,每隔10分钟合并fsimage与edits,每隔2分钟检查是否满足合并条件
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>6000</value>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>18000</value>
</property>
小贴士:
- 如果ssh连接工具出现中文乱码 可以手动修改编码方式为utf-8
- r:read;w:write;x:execute,权限x对于文件忽略,对于文件表示是否允许访问其内容
安全模式
- 查看namenode处于哪个状态 hdfs dfsadmin -safemode get
- 进入安全模式(hadoop启动的时候在安全模式) hdfs dfsadmin -safemode enter
- 离开安全模式 hdfs dfsadmin -safemode leave raplication表示默认拷贝几份文件
-
安全模式的相关属性都在文件conf/hdfs-site.xml中指定,有如下几个:
dfs.replication.min 指定数据块要达到的最小副本数,默认为1
dfs.safemode.extension 指定系统退出安全模式时需要的延迟时间,默认为30(秒)
dfs.safemode.threshold.pct 指定退出条件,需要达到最小副本数的数据块比例
2.元数据管理
导出最新的fsimage文件为xml格式,并存储到/home/hadoop/image目录下,导出最新的写操作edits文件,存储到/home/hadoop/edits目录下。
小贴士:导出edits.xml时一定要快 因为生成新的比较快
- 启动服务器 cd /usr/apps/hadoop/hdpdata/dfs/name/current/
- 先创建目录 mkdir /home/hadoop/image mkdir /home/hadoop/edits
- 找到数字最大的fsimage_00000000000000000xxxx
- hdfs oiv -p XML -i /usr/apps/hadoop/hdpdata/dfs/name/current/fsimage_0000000000000001839 -o /home/hadoop/image/fsimage1.xml
- 查看内容hdfs dfs -ls -R webhdfs://127.0.0.1:5978/
- 查看edtis内容hdfs oev -i 数字最大的edtis文件 -o edits.xml
- hdfs oev -i /usr/apps/hadoop/hdpdata/dfs/name/current/edits_inprogress_0000000000000092735 -o edits.xml
3.按照下面要求使用Shell命令管理集群

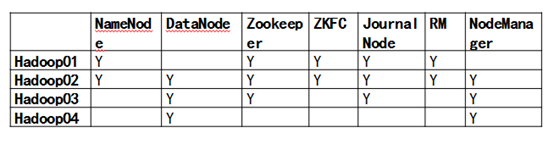
启动和结束zookeeper集群,启动和关闭hdfs,关闭和打开指定namenode,关闭和启动指定datanode,在HDFS中创建目录、上传文件、下载文件。
启动:
- #zkServer.sh start 三个节点hadoop01~03
- #start-dfs.sh 任意一个节点 hadoop01
- #start-yarn.sh 两个节点 01,02
关闭:
- #stop-hbase.sh
- #stop-yarn.sh
- #stop-dfs.sh
- zkServer.sh stop
创建目录:
hadoop fs -mkdir -p /aaa/bbb/ccc
文件上传:
hadoop fs -moveFromLocal /home/aa.txt /aaa/bbb/ccc
文件下载:
hadoop fs -moveToLocal /aaa/bbb/ccc/test /home/hadoop/text.txt
4.Java API管理文件
使用FileSystem API实现文件上传、下载、删除、创建目录和显示文件元数据操作;使用SequenceFile完成小文件管理。
Eclipse搭建hadoop开发环境
- (1) 将hadoop的hadoop2x-eclipse-plugin-2.6.0复制到Eclipse下的pludins目录下,然后打开eclipse -windows-perspective-new perspective-others选择Map/Reduce
- (2) 选择新建hadoop本地,host选填当前为active的namenode M/R port为9001,DFSport为9000 username为hadoop,选择完成
- (3) 右键单击计算机选择管理,选择本地用户和组,选择用户,选择administrater右键重命名为hadoop
- (4) eclipse 显示连接成功,显示集群目录
package pdsu.rjxy;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;public class ReadFile {public static void main(String[] args) throws IOException {// TODO Auto-generated method stub//创建上下文配置Configuration conf = new Configuration();FileSystem fs = FileSystem.get(conf);//Path path = new Path("/data/test.txt");//使用参数指定文件Path path = new Path(args[0]);if(fs.exists(path)){try{FSDataInputStream in = fs.open(path);IOUtils.copyBytes(in, System.out, 1024,false);}catch(Exception e){e.printStackTrace();}finally{IOUtils.closeStream(fs);}}else{System.out.println("File not exists.");}}}打包成jar文件
#hadoop jar my_cat.jar /data/test.txt