阿里巴巴国际站入驻通州区网站快速排名方案
原文链接:https://tbgraph.wordpress.com/2017/10/28/neo4j-marvel-social-graph-analysis/译者言:原文篇副较长,为了方便阅读,这里先原文拆成上下两篇。本文是下篇,主要介绍聚类系数,连通分量,加权连通分量几种分析方法,总体而言还都是比较基础的分析方法。好,闲话少说,书接在Neo4j中对漫威社交网络进行初步分析-上篇。
三角形个数/聚类系数
在图论中,聚类系数是用来描述图中结点聚集程度的系数。在现实的网络中,尤其是在特定社交网络中,由于相对高密度连接关系,结点总是趋向于建立一组严密的组织关系。这种可能性往往比两个结点之间随机建立了一个连接的平均概率更大。这种相互关系可以利用聚类系数进行量化表示(理论依据参看文章结尾[1][2]引用)。
聚类系数分为整体与局部两种。整体聚类系数可以给出一个图中结点整体的聚集程度的评估,而局部聚类系数则可以测量图中每一个结点附近的聚集程度。
CALL algo.triangleCount('Hero', 'KNOWS',
{write:true, writeProperty:'triangles',
clusteringCoefficientProperty:'coefficient'})
YIELD nodeCount, triangleCount, averageClusteringCoefficient;
运行这个算法,将会在每个Hero结点增加两个属性:局部三条形个数(triangles)和聚类系数(coefficient)。同时会返回整个图的总三角形个数和平均聚类系数。关于这个算法的更多信息请看文档(https://neo4j.com/docs/graph-algorithms/current/algorithms/triangle-counting-clustering-coefficient/)
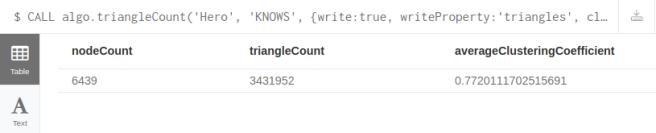
从上图可以看到,平均聚类系数达到0.77,已经非常高了。如果是1的话,就代表整个图就是一个完整的类群,那样的话,图中每个人都是知道彼此的。而聚类系数如此之高也并不奇怪,因为我们图是连通的,只是大部分关系都弱连接而已。
连通分量
图的连通性测试是每个图算法最重要的一个预处理步骤,这就要求这种测试要简单且快速。即使看上去一个图是连通的,但在执行算法之间也要进行一下连通性测试。因为当算法在非连通图上运行时,可能会有细微的且难以发现的错误出现。
连通分量还有一些具体用处,如我们在分析一个社交网络时,可以帮助我们发现图中存在的所有孤立的群组。 关于更多信息请查阅文档(https://neo4j.com/docs/graph-algorithms/current/algorithms/connected-components/)
CALL algo.unionFind.stream('Hero', 'KNOWS', {})
YIELD nodeId,setId
WITH setId,count(*) as communitySize
// filter our single node communities
WHERE communitySize > 1
RETURN setId,communitySize
ORDER BY communitySize DESC LIMIT 20
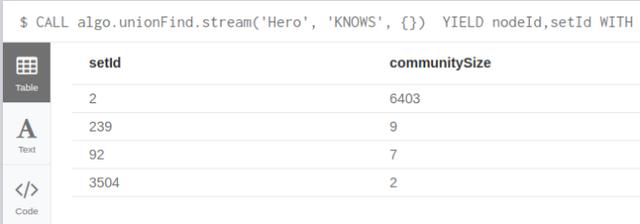
上面语句运行时,可以看出,整个图有22个群组成,且最大的群覆盖了整个图的99.5%。另外,还有18个单成员群,以及3个小群:分别有9个、7个、2个成员。
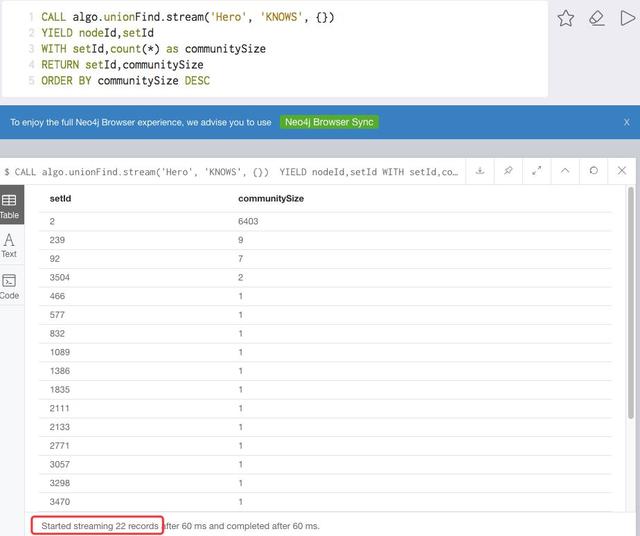
译者言:看上面的语句和图以及描述可能不太好理解,上面的语句把所有单成员群都屏蔽了。但是运行下面的语句就可以容易理解:
CALL algo.unionFind.stream('Hero', 'KNOWS', {})
YIELD nodeId,setId
WITH setId,count(*) as communitySize
RETURN setId,communitySize
ORDER BY communitySize DESC
这里把所有群都列出来了,包括单成员群。
接下来我们看看这些小群里都有谁
CALL algo.unionFind.stream('Hero', 'KNOWS', {})
YIELD nodeId,setId
WITH setId,collect(nodeId) as membersId,count(*) as communitySize
// skip the largest component
ORDER BY communitySize DESC SKIP 1 LIMIT 20
MATCH (h:Hero) WHERE id(h) in membersId
RETURN setId,collect(h.name) as members
ORDER BY length(members) DESC
我们通过返回的结点ID找到结点,再通过结点去获取英雄的名称。

有18位英雄从没有和其他英雄一起出现过,他们是RED WOLF II, RUNE, DEATHCHARGE 等。第二大群有9位英雄,看上去他们是ASHER的家人和朋友。
译者言:非常抱歉,真的不知道这几位英雄怎么称呼了。
加权连通分量
现在我们想要把两个英雄标记为同事,但是只在一部漫画中出现,不能称之为同事,要在至少十部漫画中一块出现才算同事。要实现这个逻辑,这时就需要使用加权连通分量算法。
在algo.unionFind.stream方法的第三个参数中,有两个选项可能用来定义权重和阈值。如果关系上weight值足够高,大于阈值时,此时两英雄之间的关系就会保留,代表这两英雄是有联系的,是同事,否则,这个关系就会被抛弃,这两英雄也就没有联系,不是同事。
在我们的示例中,要求两英雄至少在10部漫画中一起出现过才代表他们之前有联系,可以被标记为同事。
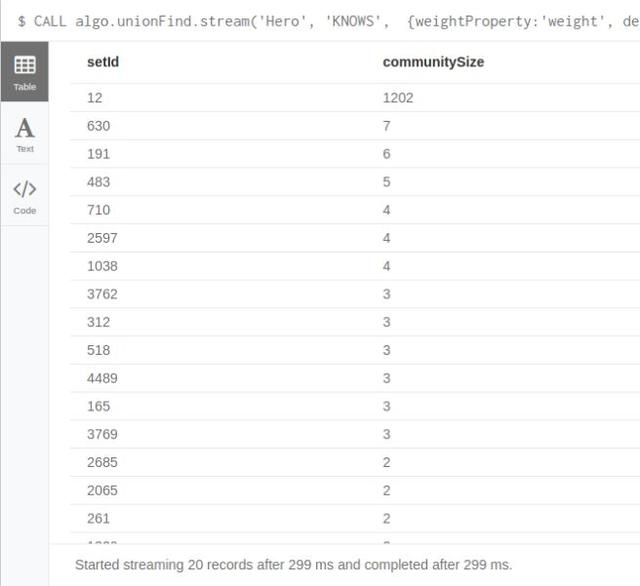
CALL algo.unionFind.stream('Hero', 'KNOWS',
{weightProperty:'weight', threshold:10.0})
YIELD nodeId,setId
RETURN setId,count(*) as communitySize
ORDER BY communitySize DESC LIMIT 20;
注意 weightProperty 和 threshold.
译者言:上述语句有可能运行失败,那是因为使用的版本不支持并行计算,可以使用如下语句:
CALL algo.unionFind.stream('Hero', 'KNOWS',
{weightProperty:'weight', threshold:10.0,concurrency:1})
YIELD nodeId,setId
RETURN setId,count(*) as communitySize
ORDER BY communitySize DESC LIMIT 20;
如我们所料,最大一个群的英雄覆盖率由之间的99.5%下降到18.6%。另外,通过调整阈值,我们可以发现一些潜在的英雄团队,包括他们之间更多的互动,以及更久远的历史等。
我们可以自行设置不同的阈值看看会怎样。
另外,不仅群的人数有意思,群成员也很有趣。我们来看看这些群成员,先跳过第一大群,因为在浏览器里显示1200个名字可不太明智。
CALL algo.unionFind.stream('Hero', 'KNOWS',
{weightProperty:'weight', defaultValue:0.0, threshold:10.0})
YIELD nodeId,setId
WITH setId,collect(nodeId) as membersId,count(*) as communitySize
// skip the largest component
ORDER BY communitySize DESC SKIP 1 LIMIT 20
MATCH (h:Hero) WHERE id(h) in membersId
RETURN setId,collect(h.name) as members
ORDER BY length(members) DESC

第二大群已经显示出来,他们的名字看起来很酷,如Bodybag、China Doll 和 Scatter Brain。但是很抱歉,我对这个领域所知甚少,无法给出任何评价。
译者言:我也不知道这第二大群都是些什么英雄,就直接贴出来吧。
结论
本文比较长,但是我想在漫威英雄社交网络上分析的远不至这些,所以,我会至少再写一篇文章来介绍如何使用Cypher来进行中心性判断,以及使用Louvain和标签传播算法来进行群组识别。
好,希望今天这些对你有用。
引用
[1] https://en.wikipedia.org/wiki/Clustering_coefficient