东莞做网站注意事项网站宣传推广文案
使用两种多线程模式消费数据
KafkaProducer是线程安全的,然而 KafkaConsumer却是非线程安全的。 Kafka Consumer中定义了一个 acquire(方法,用来检测当前是否只有一个线程在操作,若有其他线程正在操作则会抛出 Concurrentmodifcationexception异常:
java.util.ConcurrentModificationException: KafkaConsumer is not safe for multi-threaded access.
KafkaConsumer非线程安全并不意味着我们在消费消息的时候只能以单线程的方式执行。如果生产者发送消息的速度大于消费者处理消息的速度,那么就会有越来越多的消息得不到及时的消费,造成了一定的延迟。除此之外,由于Kafka中消息保留机制的作用,有些消息有可能在被消费之前就被清理了,从而造成消息的丢失。我们可以通过多线程的方式来实现消息消费,多线程的目的就是为了提高整体的消费能力。多线程的实现方式有多种,第一种也是最常见的方式:线程封闭,即为每个线程实例化一个KafkaConsumer对象,如图3-10所示。
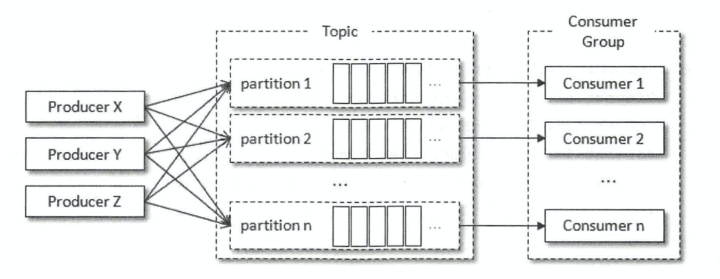
第一种多线程消费实现方式
一个线程对应一个KafkaConsumer实例,我们可以称之为消费线程。一个消费线程可以消费一个或多个分区中的消息,所有的消费线程都隶属于同一个消费组。这种实现方式的并发度受限于分区的实际个数,当消费线程的个数大于分区数时,就有部分消费线程一直处于空闲的状态。
package com.rain.demo;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.lang.reflect.Array;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;/*** @Author: wcy* @Date: 2020/5/31*/
public class FirstMultiConsumerThreadDemo {public static final String brokerList = "nas-cluster1:9092";public static final String topic = "test.topic";public static final String groupId = "group.demo";public static Properties initConfig(){Properties properties = new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);properties.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);properties.put("key.deserializer", StringDeserializer.class.getName());properties.put("value.deserializer",StringDeserializer.class.getName());return properties;}public static void main(String[] args) {Properties props = initConfig();int consumerThreadNum = 4;for (int i = 0; i < consumerThreadNum; i++) {new KafkaConsumerThread(props,topic).start();}}public static class KafkaConsumerThread extends Thread{private KafkaConsumer<String,String> kafkaConsumer;public KafkaConsumerThread(Properties props, String topic) {this.kafkaConsumer = new KafkaConsumer<>(props);this.kafkaConsumer.subscribe(Arrays.asList(topic));}@Overridepublic void run() {try {while (true){ConsumerRecords<String,String> records = kafkaConsumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String,String> record : records){//实现处理逻辑System.out.println(record.value());}}}catch (Exception e){e.printStackTrace();}finally {kafkaConsumer.close();}}}
}内部类 Kafka Consumer Thread代表消费线程,其内部包裹着一个独立的 Kafka Consumer实例。通过外部类的 maino方法来启动多个消费线程,消费线程的数量由 consumer Threadnum变量指定。一般一个主题的分区数事先可以知晓,可以将 consumer Threadnum设置成不大于分区数的值,如果不知道主题的分区数,那么也可以通过 Kafka Consumer类的 partitionsforo方法来间接获取,进而再设置合理的 consumer Threadnum值。 上面这种多线程的实现方式和开启多个消费进程的方式没有本质上的区别,它的优点是每个线程可以按顺序消费各个分区中的消息。缺点也很明显,每个消费线程都要维护一个独立的TCP连接,如果分区数和 consumer Threadnum的值都很大,那么会造成不小的系统开销。
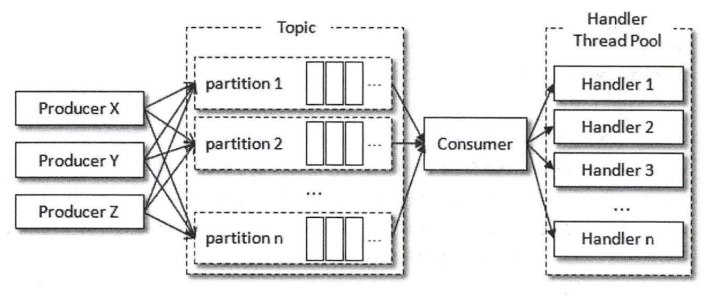
第二种基于数据处理的多线程消费实现
如果处理数据的地方对消息的处理非常迅速,那么pollo拉取的频次也会更高,进而整体消费的性能也会提升;相反,如果在这里对消息的处理缓慢,比如进行一个事务性操作,或者等待一个RPC的同步响应,那么poll(拉取的频次也会随之下降,进而造成整体消费性能的下降。一般而言, pol()拉取消息的速度是相当快的,而整体消费的瓶颈也正是在处理消息这一块,如果我们通过一定的方式来改进这一部分,那么我们就能带动整体消费性能的提升,因此将处理消息模块改成多线程的实现方式。
package com.rain.demo;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;/*** @Author: wcy* @Date: 2020/5/31*/
public class SecondMultiConsumerThreadDemo {public static final String brokerList = "nas-cluster1:9092";public static final String topic = "test.topic";public static final String groupId = "group.demo";public static Properties initConfig(){Properties properties = new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);properties.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);properties.put("key.deserializer", StringDeserializer.class.getName());properties.put("value.deserializer",StringDeserializer.class.getName());return properties;}public static void main(String[] args) {Properties properties = initConfig();KafkaConsumerThread consumerThread = new KafkaConsumerThread(properties,topic,Runtime.getRuntime().availableProcessors());consumerThread.start();}public static class KafkaConsumerThread extends Thread{private KafkaConsumer<String,String> kafkaConsumer;private ExecutorService executorService;private int threadNumber;public KafkaConsumerThread(Properties properties, String topic, int availableProcessors) {kafkaConsumer = new KafkaConsumer<String, String>(properties);kafkaConsumer.subscribe(Collections.singletonList(topic));this.threadNumber = availableProcessors;executorService = new ThreadPoolExecutor(threadNumber,threadNumber,0L, TimeUnit.MILLISECONDS,new ArrayBlockingQueue<>(1000),new ThreadPoolExecutor.CallerRunsPolicy());}@Overridepublic void run() {try {while (true){ConsumerRecords<String,String> records = kafkaConsumer.poll(Duration.ofMillis(100));if (!records.isEmpty()){executorService.submit(new RecordsHandler(records));}}}catch (Exception e){e.printStackTrace();}finally {kafkaConsumer.close();}}}public static class RecordsHandler extends Thread{public final ConsumerRecords<String,String> records;public RecordsHandler(ConsumerRecords<String, String> records) {this.records = records;}@Overridepublic void run() {for (ConsumerRecord<String,String> record : records){//实现处理逻辑System.out.println(record.value());}}}
}代码中 Recordhandler类是用来处理消息的,而 Kafka Thread类对应的是一个消费线程,里面通过线程池的方式来调用 Recordhandler处理一批批的消息。注意Kafka Consumer Thread类中 Threadpoolexecutor里的最后一个参数设置的是 Callerrunspolicyo, 这样可以防止线程池的总体消费能力跟不上polO拉取的能力,从而导致异常现象的发生。第三种实现方式还可以横向扩展,通过开启多个 Kafka Consumerthread实例来进一步提升整体的消费能力。