上海市建设合同信息表网站/免费发帖的平台有哪些
参考论文 《The Variational Approximation for Bayesian Inference》
令观测值为x\mathrm{x}x,代估参数值为 θ\thetaθ, EM算法所想要最大化的目标函数,最大似然函数可写为:
lnp(x;θ)=F(q,θ)+KL(q∥p)(1)\ln p(\mathbf{x} ; \boldsymbol{\theta})=F(q, \boldsymbol{\theta})+K L(q \| p) \tag{1}lnp(x;θ)=F(q,θ)+KL(q∥p)(1)
- p(x;θ)p(\mathrm{x} ; \boldsymbol{\theta})p(x;θ)强调θ\boldsymbol{\theta}θ是一个参数,例如似然函数便是以之为变量的函数。另一方面,p(x∣θ)p(\mathbf{x} \mid \boldsymbol{\theta})p(x∣θ)则强调θ\boldsymbol{\theta}θ是一个随机变量。
- F(q,θ)=∫q(z)ln(p(x,z;θ)q(z))dzF(q, \boldsymbol{\theta})=\int q(\mathbf{z}) \ln \left(\frac{p(\mathbf{x}, \mathbf{z} ; \boldsymbol{\theta})}{q(\mathbf{z})}\right) d \mathbf{z}F(q,θ)=∫q(z)ln(q(z)p(x,z;θ))dz, KL(q∥p)=−∫q(z)ln(p(z∣x;θ)q(z))dz\mathrm{KL}(q \| p)=-\int q(\mathrm{z}) \ln \left(\frac{p(\mathrm{z} \mid \mathrm{x} ; \boldsymbol{\theta})}{q(\mathrm{z})}\right) d \mathrm{z}KL(q∥p)=−∫q(z)ln(q(z)p(z∣x;θ))dz. 因此(1)式的成立就简单地遵循了p(A)=p(A,B)−p(B∣A)p(A) = p(A,B) - p(B|A)p(A)=p(A,B)−p(B∣A)这一条件概率规则。其中,KL也就是著名的KL散度 (q(z)q(z)q(z)与p(z∣x;θ)p(\mathrm{z} \mid \mathrm{x} ; \boldsymbol{\theta})p(z∣x;θ)之间)。
- 此处,z\mathbf{z}z是所谓的隐变量,也可以理解为用于求解最大似然问题的人工辅助变量。q(z)q(\mathbf{z})q(z)是任意的概率密度函数。 对于EM算法,z\mathbf{z}z和q(z)q(\mathbf{z})q(z)往往有对应的物理意义。但这里我们并不care,只从纯数学的角度理解。
关于KL散度的介绍推介看这篇 传送门,其中,通过Jensen’s不等式可以证明KL散度非负,即KL(q∥p)≥0\mathrm{KL}(q \| p) \geq 0KL(q∥p)≥0,因此:
lnp(x;θ)≥F(q,θ)(2)\ln p(\mathbf{x} ; \boldsymbol{\theta}) \geq F(q, \boldsymbol{\theta}) \tag{2} lnp(x;θ)≥F(q,θ)(2)
也就是说,(2)找到了最大似然函数的一个下界。因此,以EM算法为代表的许多贝叶斯推断都是在最大化该下界, 也即 F(q,θ)F(q, \boldsymbol{\theta})F(q,θ)。
具体而言, EM算法是一个两步法对下界F(q,θ)F(q, \boldsymbol{\theta})F(q,θ)最大化, 从而最大化似然函数:
- E-step:首先将θ\boldsymbol{\theta}θ固定为θOLD\boldsymbol{\theta}^{\mathrm{OLD}}θOLD,优化qqq来最大化F(q,θ)F(q, \boldsymbol{\theta})F(q,θ)。注意到,给定θ\boldsymbol{\theta}θ时lnp(x;θ)\ln p(\mathbf{x} ; \boldsymbol{\theta})lnp(x;θ)就确定了,因此根据(1), 最大化F(q,θ)F(q, \boldsymbol{\theta})F(q,θ)等价于最小化KL(q∥p)K L(q \| p)KL(q∥p), 而厚泽非负。 当且仅当q(z)=p(z∣x;θOLD)q(\mathbf{z})=p\left(\mathbf{z} \mid \mathbf{x} ; \boldsymbol{\theta}^{\mathrm{OLD}}\right)q(z)=p(z∣x;θOLD),取到最小值000。此时,F(q,θOLD)F(q, \boldsymbol{\theta}^{\mathrm{OLD}})F(q,θOLD) = lnp(x;θOLD)\ln p(\mathbf{x} ; \boldsymbol{\theta}^{\mathrm{OLD}})lnp(x;θOLD)为最大值。
- M-step: 将qqq固定, 优化θ\boldsymbol{\theta}θ来最大化F(q,θ)F(q, \boldsymbol{\theta})F(q,θ)。假定得到的最优解为θNEW\boldsymbol{\theta}^{\mathrm{NEW}}θNEW,那么对于固定的qqq,显然KL散度不再为000。也就是说,θNEW\boldsymbol{\theta}^{\mathrm{NEW}}θNEW不仅最大化了F(q,θ)F(q, \boldsymbol{\theta})F(q,θ),也让我们的目标lnp(x;θ)\ln p(\mathbf{x} ; \boldsymbol{\theta})lnp(x;θ)得到了更大的提升。 注意到,由于在E-step中有q(z)=p(z∣x;θOLD)q(\mathbf{z})=p\left(\mathbf{z} \mid \mathbf{x} ; \boldsymbol{\theta}^{\mathrm{OLD}}\right)q(z)=p(z∣x;θOLD), 因此在M-step中的优化为:
F(q,θ)=∫p(z∣x;θOLD)lnp(x,z;θ)dz−∫p(z∣x;θOLD)lnp(z∣x;θOLD)dz\begin{aligned} F(q, \boldsymbol{\theta})=& \int p\left(\mathbf{z} \mid \mathbf{x} ; \boldsymbol{\theta}^{\mathrm{OLD}}\right) \ln p(\mathbf{x}, \mathbf{z} ; \boldsymbol{\theta}) d \mathbf{z} \\ &-\int p\left(\mathbf{z} \mid \mathbf{x} ; \boldsymbol{\theta}^{\mathrm{OLD}}\right) \ln p\left(\mathbf{z} \mid \mathbf{x} ; \boldsymbol{\theta}^{\mathrm{OLD}}\right) d \mathbf{z} \end{aligned} F(q,θ)=∫p(z∣x;θOLD)lnp(x,z;θ)dz−∫p(z∣x;θOLD)lnp(z∣x;θOLD)dz
而后一项是与θ\boldsymbol{\theta}θ无关的常数项。 因此记:
Q(θ,θOLD)=∫p(z∣x;θOLD)lnp(x,z;θ)dzQ\left(\boldsymbol{\theta}, \boldsymbol{\theta}^{\mathrm{OLD}}\right)=\int p\left(\mathbf{z} \mid \mathbf{x} ; \boldsymbol{\theta}^{\mathrm{OLD}}\right) \ln p(\mathbf{x}, \mathbf{z} ; \boldsymbol{\theta}) d \mathbf{z} Q(θ,θOLD)=∫p(z∣x;θOLD)lnp(x,z;θ)dz
EM算法就可以被总结为:
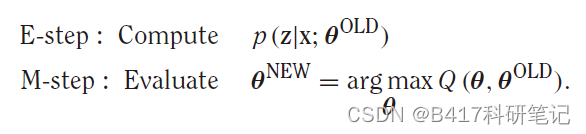
推荐大家可以看下两个实例,再结合数学公式深入理解EM算法。 https://zhuanlan.zhihu.com/p/36331115
我个人觉得一个最好的例子就是K-means算法。 E步骤相当于给定质心的情况下,对数据进行聚类。M步骤相当于分类结束的情况下,根据每类的数据对质心进行更新。 隐函数zzz就代表类别,变量θ\boldsymbol{\theta}θ包括了每类的质心参数。
EM算法的核心在于, 原始的最大似然算法需求p(x;θ)p(\mathrm{x} ; \boldsymbol{\theta})p(x;θ)的信息, 而EM算法中需求的是p(z∣x;θ)p(\mathbf{z} \mid \mathbf{x} ; \boldsymbol{\theta})p(z∣x;θ)的信息,后者在许多时候可能比前者容易获得。但在一些场景中却并不如此,也导致无法使用EM算法。此时, 变分贝叶斯方法是一种更好的算法。