版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/a_drjiaoda/article/details/88290620
《一份详细的Kylin执行样例——基于kylin2.5.0》一文中,小厨介绍了如何使用kylin,今天开辟一个新路线,个人感觉随着时代的发展,数据实时分析会成为主力军,因为今天介绍一下Kafka+kylin,流式构建cube。kylin是从1.5版本开始,引入Streaming Table,目的是减少OLAP分析的延时,到目前的2.5.0版本 Streaming做的已经相当较成熟了。
主要方法:kylin通过已经创建好的虚拟表 Streaming Table,周期性地从kafka中读取数据,根据我们定义的Model和cube,将计算好的数据存入到Hbase,供用户查询。
我们的业务场景和上文中的一样,并且数据格式跟之前文章中提过的类似,依然是统计pv uv的值,只不过这里讲其都转换成了JSON格式,据说到目前,kylin流式构建只支持JSON的数据格式。{"access_time":1437494731879,"cookieId":"M211FDN88TXQHM9QEU","regionId":"G01","cityId":"G0102","site":"5143","os":"Android 7.0","pv":"9"}。
主要步骤:
在Kylin中建立新的Project;
Kylin中同步数据源(Load DataSource);
Kylin中建立数据模型(New Model);
定义New Cube
Build Cube;
查询Cube
注意:在 kylin v2.4.0 以前,Streaming Cube 不支持与 lookup 表进行 join;当定义数据模型时,只选择 fact 表,不选 lookup 表;这意味着你JSON含有哪些字段,之后你只能显示和操作哪些字段。举个例子,上面我们的"regionId":"G01"代表的是省会(安徽、陕西等),"cityId":"G0102"代表城市(合肥、西安),我们期望能通过关联其他两张表(region_tb1和city_tb1)来显示相关文字,但是在v2.4.0之前不可能做到,在其之后可以通过lookup表的方式来关联表之间的关系。
一、定义数据表
首先,我们将JSON格式的数据放入到Streaming DataSource的JSON框中,点击》图标,kylin会自动映射成表的字段,输入Table Name,这里需要注意的是,进入的字段可能映射的字段的类型不准确,比如我的pv它映射成了date,但是我后面的是要将其作为sum的,所以需要手动修改一下,省的后来还得回来重新创建表。这里面我们后来是要分钟级别的构建cube,因此我们要选到minute为止。之后配置你的Kafka集群的信息,包括topic name以及broker list,我这里name是web_pvuv_kylin_streaming_topic。
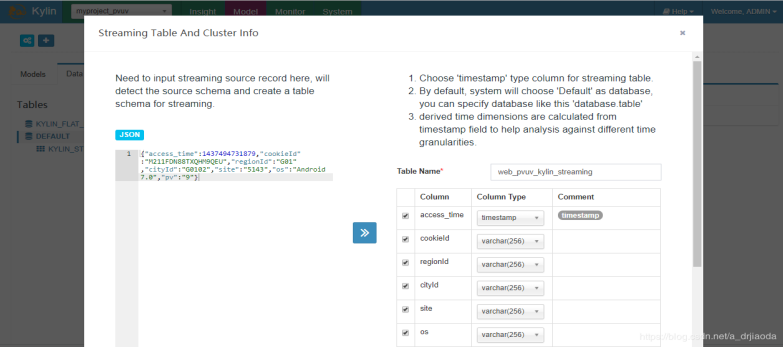
注意:Kylin允许用户挑选一些从业务时间戳上衍生出来的时间维度(Derived Time Dimension),具体来说有如下几种。
·minute_start:业务时间戳所在的分钟起始时间,类型为Timestamp(yyyy-MM-dd HH:mm:ss)。
·hour_start:业务时间戳所在的小时起始时间,类型为Timestamp(yyyy-MM-dd HH:mm:ss)。
·day_start:业务时间戳所在的天起始时间,类型为Date(yyyy-MMdd)。
·week_start:业务时间戳所在的周起始时间,类型为Date(yyyy-MMdd)。
·month_start:业务时间戳所在的月起始时间,类型为Date(yyyy-MMdd)。
·quarter_start:业务时间戳所在的季度起始时间,类型为Date(yyyyMM-dd)。
·year_start:业务时间戳所在的年起始时间,类型为Date(yyyy-MMdd)。
这些衍生时间维度都是可选的,如果用户选择了这些衍生维度,那么在对应的时间粒度上进行聚合时就能够获得更好的查询性能,一般来说不推荐把原始的业务时间戳选择成一个单独的维度,因为该列的基数一般都是很大的。
知识点:经过测试发现,通过Streaming建造的表都是默认在DEFAULT数据库中,目前没找到办法改。回到model中,我们看DataSource中刚刚创建的表如下:

二、创建Model
1、创建Model,选择new Model。输入名称为:web_pvuv_kylin_streaming_model。(和下图些许不同,但没啥影响)
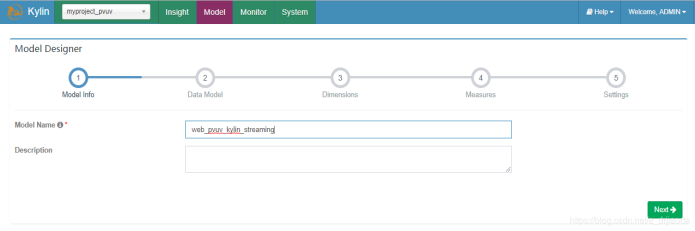
2、依然是选择事实表,并且添加lookup table,j建立事实表与衍生表之间的关系。
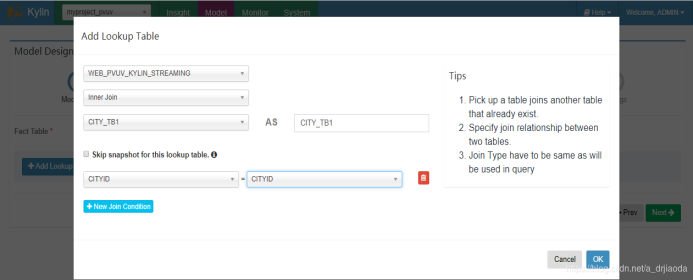
添加第二张lookup table
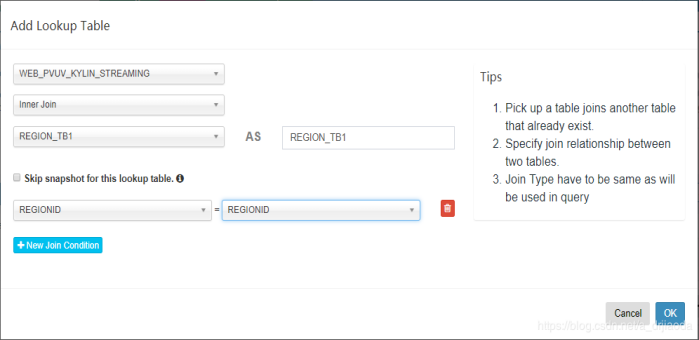
选择事实表和lookup 表之后,单击next
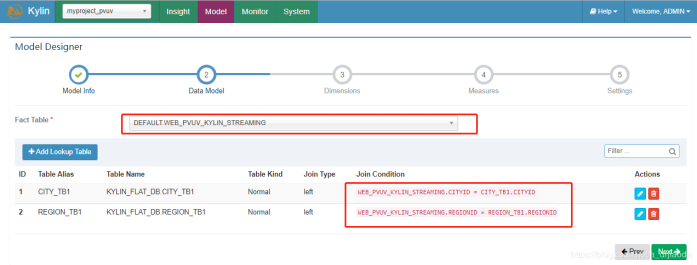
3、主要是选择各个表的维度,我们既可以选择普通的维度,又可以选择衍生的时间维度。注意,一般不推荐直接选择业务时间戳作为维度(也就是这里的access_time),因为业务时间戳的精度往往是精确到秒级甚至是毫秒级的,使用它作为一个维度失去了聚合的意义,也会让整个Cube的体积变得非常庞大
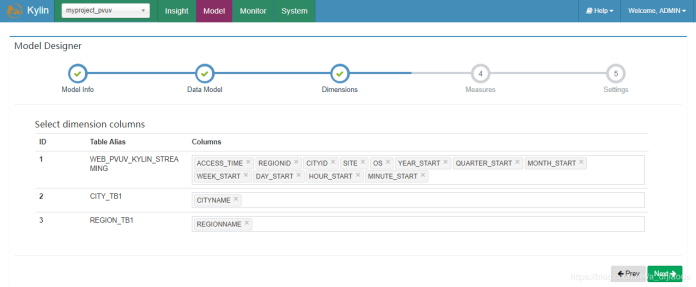
4、选择需要度量指标的字段,本例中使用cookid和PV
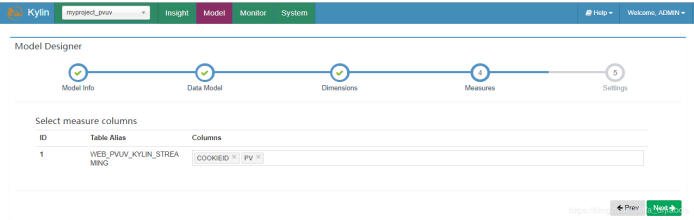
5、在创建Model对话框的第五步设置中,一般选择最小粒度的衍生时间维度作为分割时间列,在这里我们选MINUTE_START,它的数据格式为yyyy-MM-dd HH:mm:ss。有了分割时间列,就可以对Cube进行分钟级的流式构建了
至此,点击save保存,model:web_pvuv_kylin_streaming就创建完成了。
三、创建cube
1、点击 new cube,绑定刚刚创建的模型,输入Cube名称:web_pvuv_kylin_streaming_cube
2、不要使用access_time,因为它的粒度太细。注意:这里我们不选择access_time,否则创建的cube体积太大。
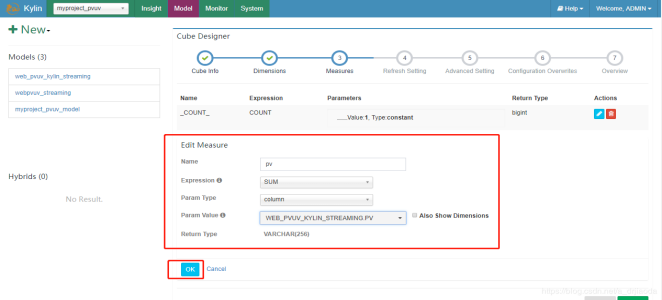
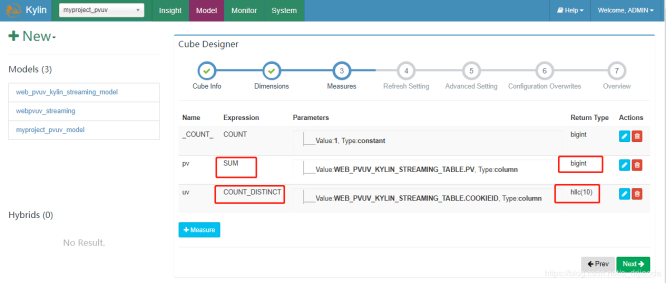
3、Measures为度量指标的设计。这里我们对pv进行sum汇总计算,对cookieid进行count distinct去重过滤统计个数。为了让大家更清楚,我们将添加的Measure的页面也截出来,这里面有很多聚合函数,Top,count、sum等等;
4、创建Cube的第四步是设置Cube的自动合并时间。因为流式构建需要频繁地构建较小的Segment,为了不对存储器造成过大的压力,同时也为了获取较好的查询性能,因此需要通过自动合并将已有的多个小Segment合并成一个较大的Segment。所以,这里将设置一个层级的自动合并时间:0.5小时、4小时、1天、7天、28天。此外,设置保留时间为30天。此外,我们设置分区时间是从2013年开始,因为我们的模拟数据是从13年开始。
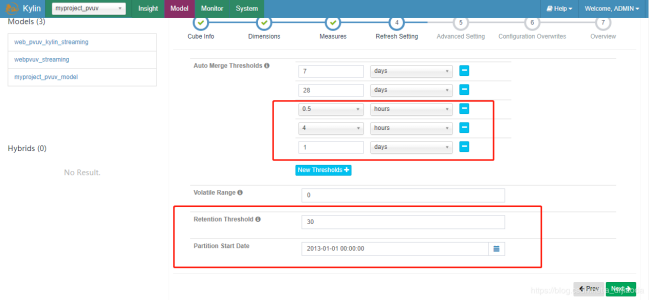
5、在Advanced Setting,Aggregation Groups设置中,可以把衍生时间维度设置为Hierarchy关系,
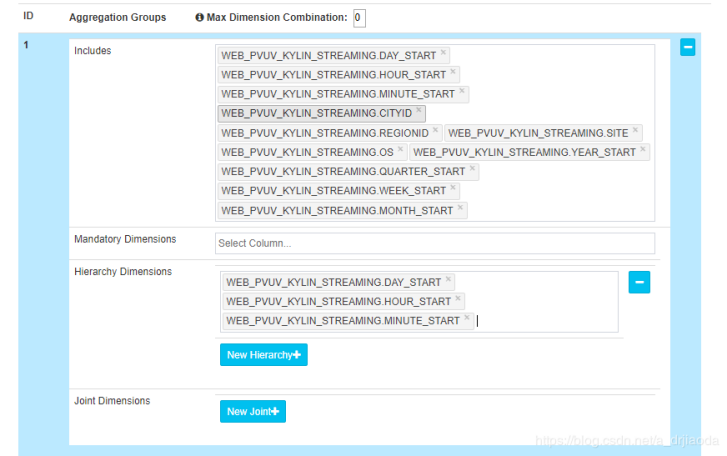
调整Rowkey,调整衍生时间维度,一般把上面时间衍生维度的行放在上面,拖拽即可,如下图:
单击下图中的save,即可成功创建cube。
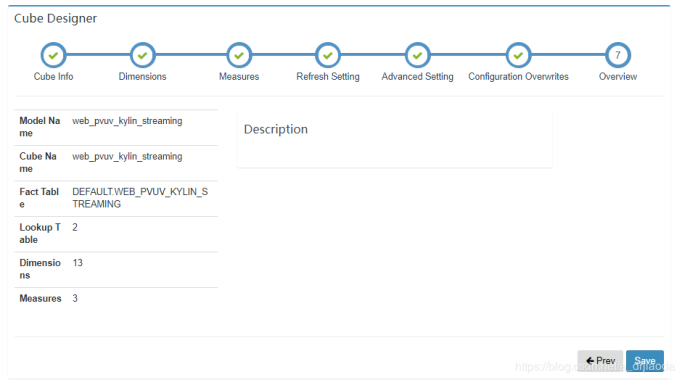
结束之后,我们可以在Model中查看到这个cube,并且它的状态时disable的,cube Size为0。
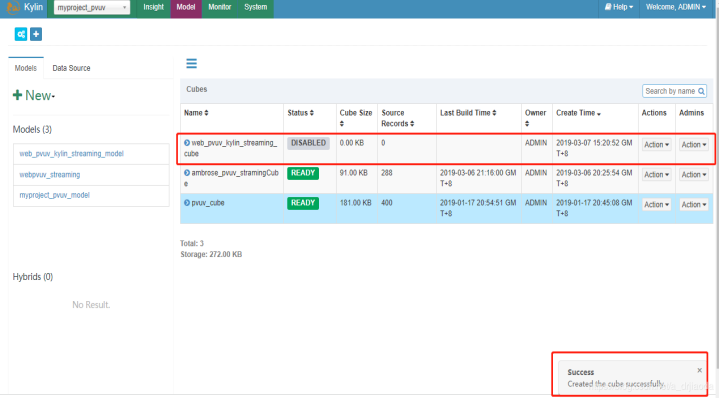
四、配置运行kafka
在kafka创建topic之前,我们先看看三台虚机都要启动哪些进程,如下图所示:
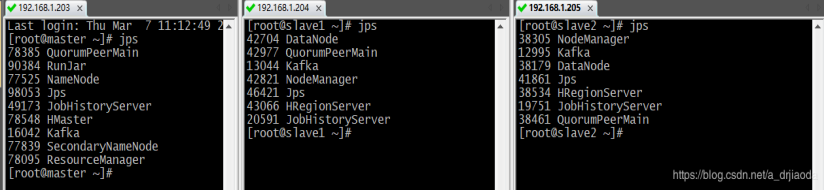
1、在kakfa创建Topic:web_pvuv_kylin_streaming_topic。使用以下命令,确保已经配置了kafka的环境变量:
kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181 --replication-factor 3 --partitions 3 --topic web_pvuv_kylin_streaming_topic

五、首次Build cube + simple Kylin test
创建好topic之后,我们先去试一下刚刚的web_pvuv_kylin_streaming_cube是否能够build。
【注意:】这里在提一句,v2.5.0版本的kylin支持在web界面产生build操作,有些低版本的kylin不直接GUI方式build,只能通过在kylin的bin目录下使用命令来手动去build cube。之后为了保证流处理方式,每隔几分钟自动去创建build cube,实质上也就是linux在隔几分钟去执行 build cube的命令,下文我们会提到。
显然,在topic创建好立即执行build 操作会报错,这是由于Kylin 会记录每一个 build 的 offsets;当收到一个 build 请求,它将会从上一个结束的位置开始,然后从 Kafka 获取最新的 offsets。第一次没有数据时,没有offset则会报错。
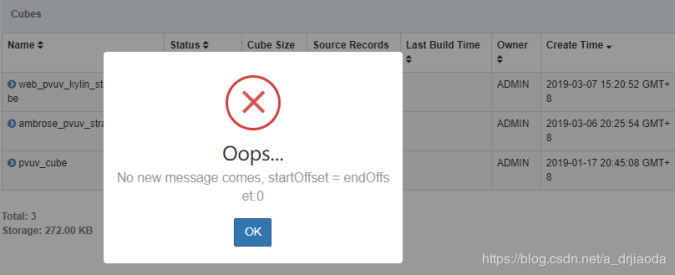
我们使用eclipse多做kafka producer像该topic中发送数据,先发五条(这里我的计数是从0开始),立即停止,验证第一build时能否正确拿数据。停止之后,我们去kylin的web界面中build cube(这一步不贴图了)。

我们使用kafka -console-consumer.sh在cli中查看是否是五条,如下,验证通过。

此时回到kylin的web界面,在monitor上界面上可以看到上述的cube在经历23步之后已经build完成,历时7.9mins,大家可能回想为什么仅仅四条数据而已,为什么会花费这么多时间,其实这个只是第一次build的时候时间长,需要建表等一系列操作,我们在测试时发现,之后再build的时候时间会缩小一些。
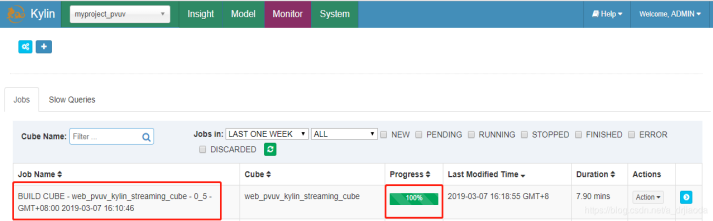
从下图Model可以看出,建立的cube已经是READY状态,正好是五条数据。
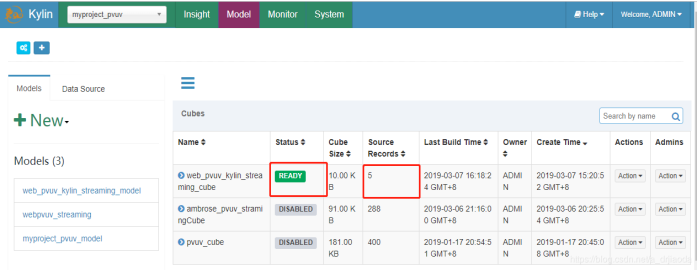
那我先来做个简单的测试,从这五条数中查询一些信息,当然大家会想才5条数据而已,查询起来这很简单,但是这只是测试用例。下面我们会让kafka消息队列中产生大量的数据,再进行测试。从下图可以看出,我们查出来的数据是正确的,而且速度也非常快,可以提交给上级业务部门进行使用啦。
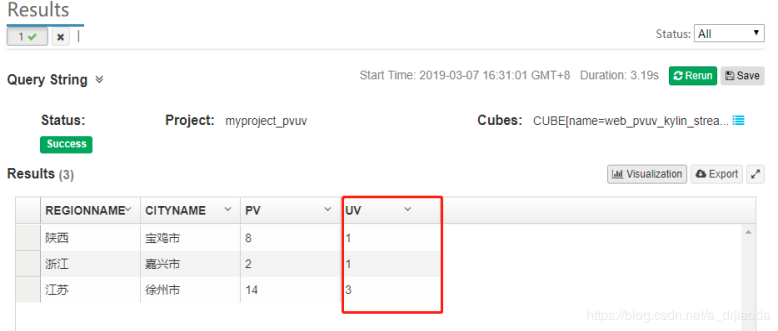
六、终极Test
简单测试之后,我们现在来让kafka+kylin自动跑起来。
要求:@1、使用Kakfa程序向topic中每秒发送10条数据,即每分钟600条数据;@2、cube每隔5分钟自动创建一次。
步骤:
1、写kakfa Producer程序,发送Json数据。有兴趣的同学,可以查看我的另外一篇博客《kafka之Producer实现》,分享使我快乐,如果觉得有帮助,点个赞吧。哈哈
2、使用 crontab -e 命令,输入以下:(单击三下可复制)
*/5 * * * * echo $(date) >> /usr/kylin/streamingBuild.txt; curl -X PUT --user ADMIN:KYLIN -H "Content-Type: application/json;charset=utf-8" -d '{ "sourceOffsetStart": 0, "sourceOffsetEnd": 9223372036854775807, "buildType": "BUILD"}' http://192.168.1.203:7070/kylin/api/cubes/web_pvuv_kylin_streaming_cube/build2
下图就是通过自动构建的命令,自动build cube,可以看出,是正在建立cube。

七、流式构建原理
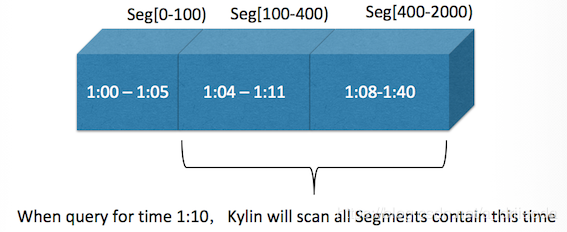
流式构建需要达到分钟级的数据更新频率,Kylin的做法是每隔一段时间(INTERVAL)就启动一次微构建,用于处理最新的一批数据。这种做法的理念有一些类似于Spark Streaming,它们也是将流数据视作一种特殊的微批次来处理的。由于分布式网络存在延迟等因素,消息可能存在延迟,因此不能为某一时刻刚刚过去的那几分钟立刻构建微批次。
举例来说,如果在每个微构建中要处理5分钟的增量数据,假设消息队列中的消息最多可能有10分钟的延迟(对应于“Margin”),那么就不能在1:00的时候立刻尝试去构建0:55到1:00这5分钟的数据,因为这部分数据的消息最迟可能在1:10分才会到齐,否则构建出来的Segment就存在很大的遗漏数据的风险。此时,需要像增量构建中提到的“数据持续更新”的情形一样,对过往的Segment进行刷新操作。但是目前流式构建并不支持Segment刷新操作,所以,最早只能在1:10开始构建0:55到1:00这部分的数据。这中间的延迟我们称之为DELAY,它等于每个微构建批次的时间(INTERVAL)加上消息最长可能延迟的时间(MARGIN)。
————————————————
版权声明:本文为CSDN博主「夏天小厨」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/a_drjiaoda/article/details/88290620