为什么要建设种苗供求网站雅思培训机构哪家好机构排名
读完本文,可以去力扣解决如下题目:
207.课程表(Medium)
210.课程表 II(Medium)

很多读者留言说要看「图」相关的算法,那就满足大家,结合算法题把图相关的技巧给大家过一遍。
数据结构相关的算法无非两点:遍历 + 访问。那么图的基本遍历方法也很简单,以前就讲过如何从多叉树的遍历框架扩展到图的遍历。
图这种数据结构还有一些比较特殊的算法,比如二分图判断,有环图无环图的判断,拓扑排序,以及最经典的最小生成树,单源最短路径问题,更难的就是类似网络流这样的问题。
不过以我的经验呢,像网络流这种问题,你又不是打竞赛的,除非自己特别有兴趣,否则就没必要学了;像最小生成树和最短路径问题,虽然从刷题的角度用到的不多,但它们属于经典算法,学有余力可以掌握一下;像拓扑排序这一类,属于比较基本且有用的算法,应该比较熟练地掌握。
那么本文就结合具体的算法题,来说说拓扑排序算法原理,因为拓扑排序的对象是有向无环图,所以顺带说一下如何判断图是否有环。
判断有向图是否存在环
先来看看力扣第 207 题「课程表」:

函数签名如下:
int[] findOrder(int numCourses, int[][] prerequisites);
题目应该不难理解,什么时候无法修完所有课程?当存在循环依赖的时候。
其实这种场景在现实生活中也十分常见,比如我们写代码 import 包也是一个例子,必须合理设计代码目录结构,否则会出现循环依赖,编译器会报错,所以编译器实际上也使用了类似算法来判断你的代码是否能够成功编译。
看到依赖问题,首先想到的就是把问题转化成「有向图」这种数据结构,只要图中存在环,那就说明存在循环依赖。
具体来说,我们首先可以把课程看成「有向图」中的节点,节点编号分别是0, 1, ..., numCourses-1,把课程之间的依赖关系看做节点之间的有向边。
比如说必须修完课程1才能去修课程3,那么就有一条有向边从节点1指向3。
所以我们可以根据题目输入的prerequisites数组生成一幅类似这样的图:
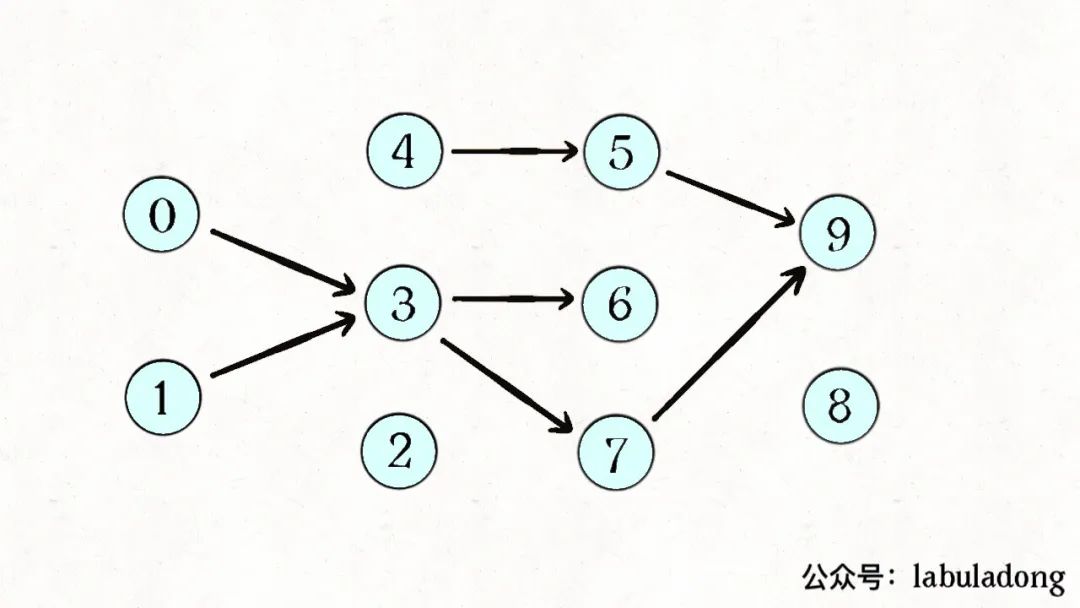
如果发现这幅有向图中存在环,那就说明课程之间存在循环依赖,肯定没办法全部上完;反之,如果没有环,那么肯定能上完全部课程。
好,那么想解决这个问题,首先我们要把题目的输入转化成一幅有向图,然后再判断图中是否存在环。
如何转换成图呢?前文 图论基础 写过图的两种存储形式,邻接矩阵和邻接表。
以我刷题的经验,常见的存储方式是使用邻接表,比如下面这种结构:
List<Integer>[] graph;
graph[s]是一个列表,存储着节点s所指向的节点。
所以我们首先可以写一个建图函数:
List<Integer>[] buildGraph(int numCourses, int[][] prerequisites) {// 图中共有 numCourses 个节点List<Integer>[] graph = new LinkedList[numCourses];for (int i = 0; i < numCourses; i++) {graph[i] = new LinkedList<>();}for (int[] edge : prerequisites) {int from = edge[1];int to = edge[0];// 修完课程 from 才能修课程 to// 在图中添加一条从 from 指向 to 的有向边graph[from].add(to);}return graph;
}
图建出来了,怎么判断图中有没有环呢?
先不要急,我们先来思考如何遍历这幅图,只要会遍历,就可以判断图中是否存在环了。
前文 图论基础 写了 DFS 算法遍历图的框架,无非就是从多叉树遍历框架扩展出来的,加了个visited数组罢了:
// 防止重复遍历同一个节点
boolean[] visited;
// 从节点 s 开始 BFS 遍历,将遍历过的节点标记为 true
void traverse(List<Integer>[] graph, int s) {if (visited[s]) {return;}/* 前序遍历代码位置 */// 将当前节点标记为已遍历visited[s] = true;for (int t : graph[s]) {traverse(graph, t);}/* 后序遍历代码位置 */
}
那么我们就可以直接套用这个遍历代码:
// 防止重复遍历同一个节点
boolean[] visited;boolean canFinish(int numCourses, int[][] prerequisites) {List<Integer>[] graph = buildGraph(numCourses, prerequisites);visited = new boolean[numCourses];for (int i = 0; i < numCourses; i++) {traverse(graph, i);}
}void traverse(List<Integer>[] graph, int s) {// 代码见上文
}
注意图中并不是所有节点都相连,所以要用一个 for 循环将所有节点都作为起点调用一次 DFS 搜索算法。
这样,就能遍历这幅图中的所有节点了,你打印一下visited数组,应该全是 true。
我曾经说过,图的遍历和遍历多叉树差不多,所以到这里你应该都能很容易理解。
那么如何判断这幅图中是否存在环呢?
你可以把递归函数看成一个在递归树上游走的指针,这里也是类似的:
你也可以把traverse看做在图中节点上游走的指针,只需要再添加一个布尔数组onPath记录当前traverse经过的路径:
boolean[] onPath;boolean hasCycle = false;
boolean[] visited;void traverse(List<Integer>[] graph, int s) {if (onPath[s]) {// 发现环!!!hasCycle = true;}if (visited[s]) {return;}// 将节点 s 标记为已遍历visited[s] = true;// 开始遍历节点 sonPath[s] = true;for (int t : graph[s]) {traverse(graph, t);}// 节点 s 遍历完成onPath[s] = false;
}
这里就有点回溯算法的味道了,在进入节点s的时候将onPath[s]标记为 true,离开时标记回 false,如果发现onPath[s]已经被标记,说明出现了环。
PS:参考贪吃蛇没绕过弯儿咬到自己的场景。
这样,就可以在遍历图的过程中顺便判断是否存在环了,完整代码如下:
// 记录一次 traverse 递归经过的节点
boolean[] onPath;
// 记录遍历过的节点,防止走回头路
boolean[] visited;
// 记录图中是否有环
boolean hasCycle = false;boolean canFinish(int numCourses, int[][] prerequisites) {List<Integer>[] graph = buildGraph(numCourses, prerequisites);visited = new boolean[numCourses];onPath = new boolean[numCourses];for (int i = 0; i < numCourses; i++) {// 遍历图中的所有节点traverse(graph, i);}// 只要没有循环依赖可以完成所有课程return !hasCycle;
}void traverse(List<Integer>[] graph, int s) {if (onPath[s]) {// 出现环hasCycle = true;}if (visited[s] || hasCycle) {// 如果已经找到了环,也不用再遍历了return;}// 前序遍历代码位置visited[s] = true;onPath[s] = true;for (int t : graph[s]) {traverse(graph, t);}// 后序遍历代码位置onPath[s] = false;
}List<Integer>[] buildGraph(int numCourses, int[][] prerequisites) {// 代码见前文
}
这道题就解决了,核心就是判断一幅有向图中是否存在环。
不过如果出题人继续恶心你,让你不仅要判断是否存在环,还要返回这个环具体有哪些节点,怎么办?
你可能说,onPath里面为 true 的索引,不就是组成环的节点编号吗?
不是的,假设下图中绿色的节点是递归的路径,它们在onPath中的值都是 true,但显然成环的节点只是其中的一部分:
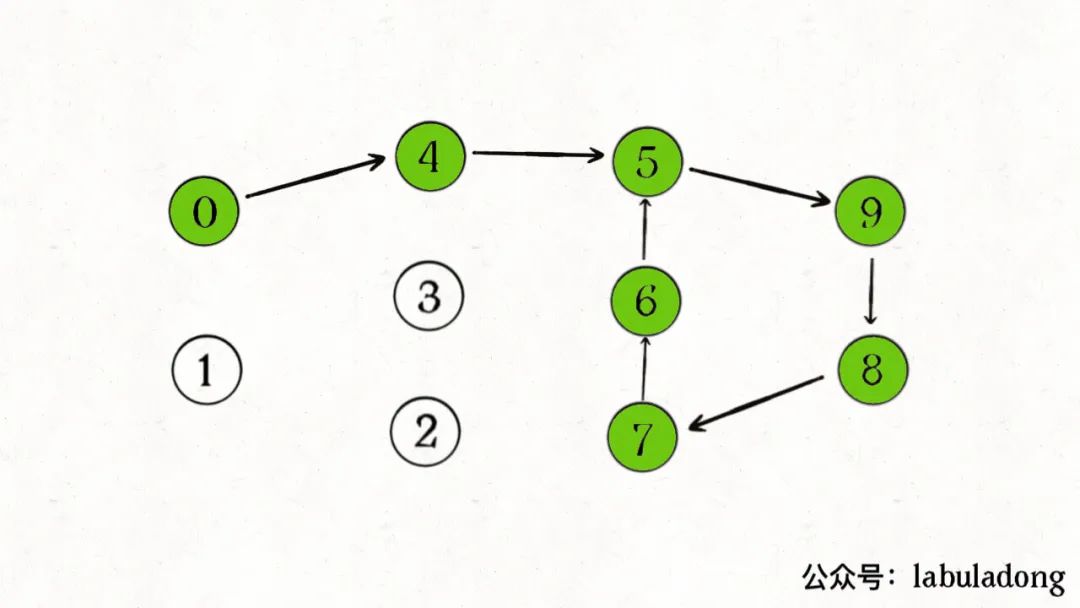
这个问题留给大家思考,我会在公众号留言区置顶正确的答案。
那么接下来,我们来再讲一个经典的图算法:拓扑排序。
拓扑排序
看下力扣第 210 题「课程表 II」:

这道题就是上道题的进阶版,不是仅仅让你判断是否可以完成所有课程,而是进一步让你返回一个合理的上课顺序,保证开始修每个课程时,前置的课程都已经修完。
函数签名如下:
int[] findOrder(int numCourses, int[][] prerequisites);
这里我先说一下拓扑排序(Topological Sorting)这个名词,网上搜出来的定义很数学,这里干脆用百度百科的一幅图来让你直观地感受下:
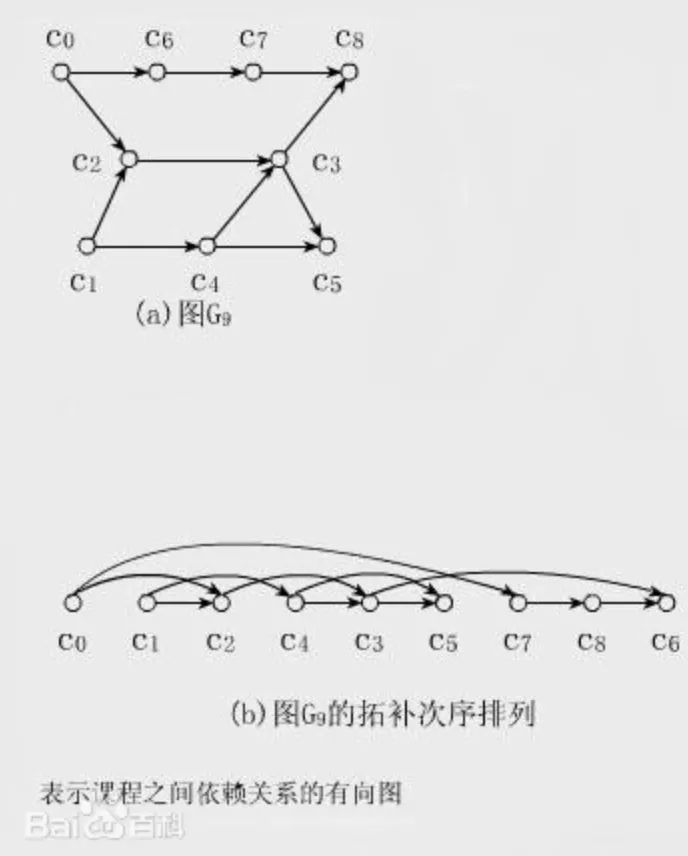
直观地说就是,让你把一幅图「拉平」,而且这个「拉平」的图里面,所有箭头方向都是一致的,比如上图所有箭头都是朝右的。
很显然,如果一幅有向图中存在环,是无法进行拓扑排序的,因为肯定做不到所有箭头方向一致;反过来,如果一幅图是「有向无环图」,那么一定可以进行拓扑排序。
但是我们这道题和拓扑排序有什么关系呢?
其实也不难看出来,如果把课程抽象成节点,课程之间的依赖关系抽象成有向边,那么这幅图的拓扑排序结果就是上课顺序。
首先,我们先判断一下题目输入的课程依赖是否成环,成环的话是无法进行拓扑排序的,所以我们可以复用上一道题的主函数:
public int[] findOrder(int numCourses, int[][] prerequisites) {if (!canFinish(numCourses, prerequisites)) {// 不可能完成所有课程return new int[]{};}// ...
}
PS:简单起见,canFinish 直接复用了之前实现的函数,但实际上可以把环检测的逻辑和拓扑排序的逻辑结合起来,同时在 traverse 函数里完成,这个可以留给大家自己去实现。
那么关键问题来了,如何进行拓扑排序?是不是又要秀什么高大上的技巧了?
其实特别简单,将后序遍历的结果进行反转,就是拓扑排序的结果。
直接看解法代码:
boolean[] visited;
// 记录后序遍历结果
List<Integer> postorder = new ArrayList<>();int[] findOrder(int numCourses, int[][] prerequisites) {// 先保证图中无环if (!canFinish(numCourses, prerequisites)) {return new int[]{};}// 建图List<Integer>[] graph = buildGraph(numCourses, prerequisites);// 进行 DFS 遍历visited = new boolean[numCourses];for (int i = 0; i < numCourses; i++) {traverse(graph, i);}// 将后序遍历结果反转,转化成 int[] 类型Collections.reverse(postorder);int[] res = new int[numCourses];for (int i = 0; i < numCourses; i++) {res[i] = postorder.get(i);}return res;
}void traverse(List<Integer>[] graph, int s) {if (visited[s]) {return;}visited[s] = true;for (int t : graph[s]) {traverse(graph, t);}// 后序遍历位置postorder.add(s);
}// 参考上一题的解法
boolean canFinish(int numCourses, int[][] prerequisites);// 参考前文代码
List<Integer>[] buildGraph(int numCourses, int[][] prerequisites);
代码虽然看起来多,但是逻辑应该是很清楚的,只要图中无环,那么我们就调用traverse函数对图进行 BFS 遍历,记录后序遍历结果,最后把后序遍历结果反转,作为最终的答案。
那么为什么后序遍历的反转结果就是拓扑排序呢?
我这里也避免数学证明,用一个直观地例子来解释,我们就说二叉树,这是我们说过很多次的二叉树遍历框架:
void traverse(TreeNode root) {// 前序遍历代码位置traverse(root.left)// 中序遍历代码位置traverse(root.right)// 后序遍历代码位置
}
二叉树的后序遍历是什么时候?遍历完左右子树之后才会执行后序遍历位置的代码。换句话说,当左右子树的节点都被装到结果列表里面了,根节点才会被装进去。
后序遍历的这一特点很重要,之所以拓扑排序的基础是后序遍历,是因为一个任务必须在等到所有的依赖任务都完成之后才能开始开始执行。
你把每个任务理解成二叉树里面的节点,这个任务所依赖的任务理解成子节点,那你是不是应该先把所有子节点处理完再处理父节点?这是不是就是后序遍历?
下图是一个二叉树的后序遍历结果:
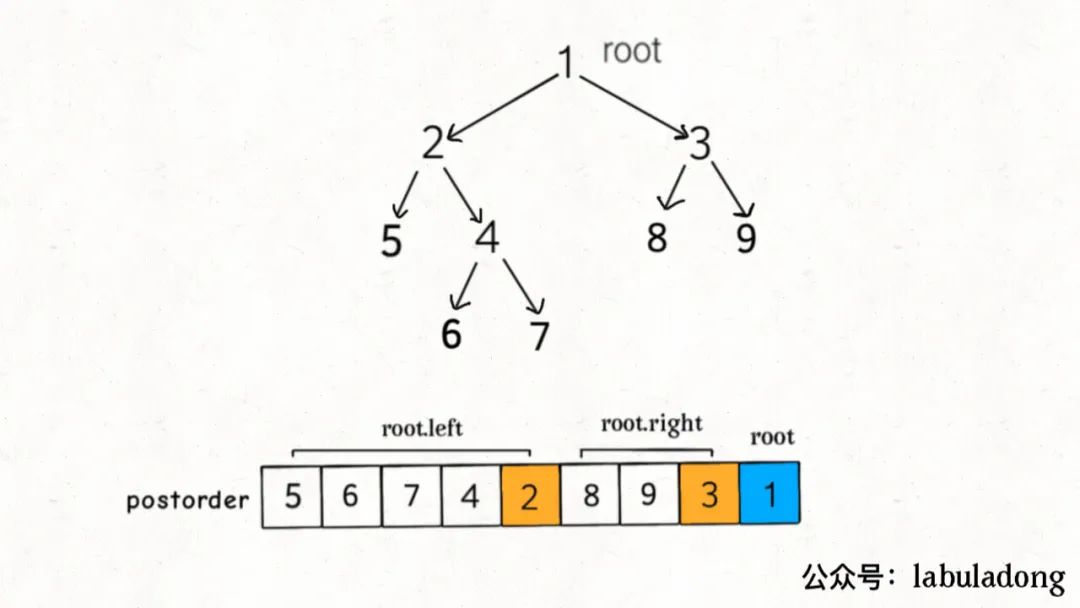
结合这个图说一说为什么还要把后序遍历结果反转,才是最终的拓扑排序结果。
我们说一个节点可以理解为一个任务,这个节点的子节点理解为这个任务的依赖,但你注意我们之前说的依赖关系的表示:如果做完A才能去做B,那么就有一条从A指向B的有向边,表示B依赖A。
那么,父节点依赖子节点,体现在二叉树里面应该是这样的:
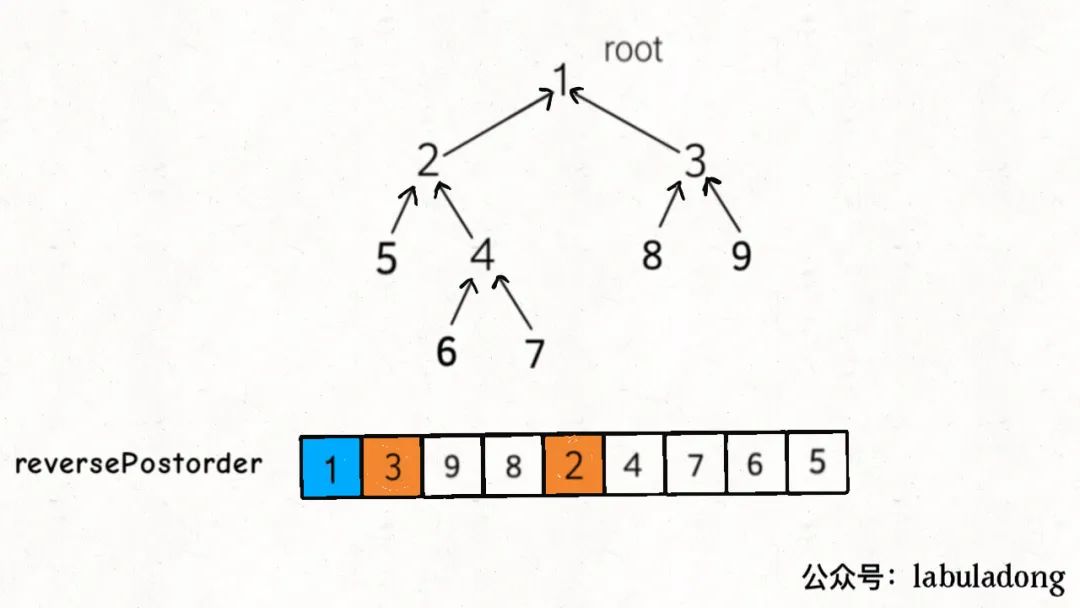
是不是和我们正常的二叉树指针指向反过来了?所以正常的后序遍历结果应该进行反转,才是拓扑排序的结果。
以上,我简单解释了一下为什么「拓扑排序的结果就是反转之后的后序遍历结果」,当然,我的解释虽然比较直观,但并没有严格的数学证明,有兴趣的读者可以自己查一下。
总之,你记住拓扑排序就是后序遍历反转之后的结果,且拓扑排序只能针对有向无环图,进行拓扑排序之前要进行环检测,这些知识点已经足够了。
本文就讲到这里,如果我的公众号对你有帮助,请推荐给有需要的朋友~