网站设计与制作简单吗高级seo课程

1. 机器学习简介
1.1 什么是机器学习
机器学习,是人工智能(AI)的一部分。是研究如何让计算机从数据中学习某种规律的科学。
- 计算机程序根据给定的数据,去优化某一个评价指标
- 自动的从数据中发现规律
- 使用规律预测未来(未知)的事务,事件等
个人简单的总结成公式为:
历史数据 + 计算机成功 = 算法模型
未来数据 + 算法模型 = 预测未来事件
1.2 机器学习分类
监督式学习
需要给每个样品打标签,训练数据包含输入和预期的输出。
- 分类
标签都是离散值
- 回归
标签都是连续值
非监督式学习
不需要标签,训练数据只有输入,没有预期的输出。
- 聚类
是指把对象分成不同的子集,使得属于同一个子集的对象都有一些相同的属性。
分类的实例应用:
- 垃圾邮件/短信检测
- 自动车牌号识别
- 人脸识别
- 手写字符识别
- 语音识别
- 医疗图片的病症诊断
回归的实例应用:
- 自动为二手车估价
- 预测股票价格
- 预测未来气温
- 自动驾驶
聚类的实例应用:
- 客户分类(市场研究)
- 用户分组(社交网络)
- 图像分割
- 推荐系统
- 消除歧义(自然语言处理)
1.3 机器学习基本流程
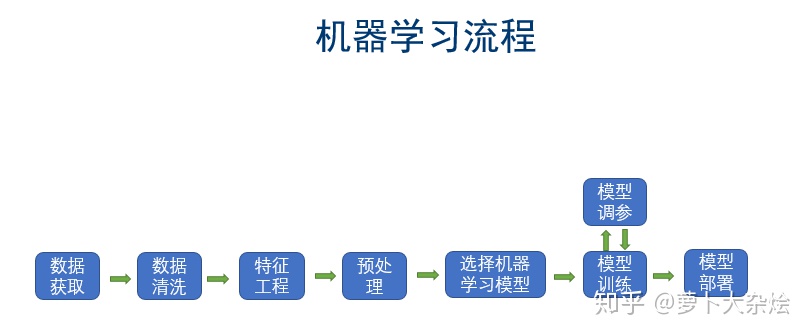
- 收集数据
到一些大数据网站或者自己公司软件收集到的数据。
2. 数据清洗
对得到的数据,做一些检查,查看是否有明显错误数据,空数据等。
3. 特征工程
把数据做一些变换,使得数据能够被程序识别,一般是向量化,提取特征。
4. 数据预处理
把数据处理成容易被程序识别的形式,如归一化,标准化等。
5. 选择算法模型
需要选择合适的算法模型
6. 训练调参
是一个迭代的过程,不断训练,来达到模型的最优。
7. 模型部署
在线部署。
1.4 数据预处理
- 特征提取
- 处理缺失数据
- 数据定标
- 数据转换
1. 特征提取
在一个真实的对象中,提取出我们关心的特征。比如物体的形状,体积等。文字的出现位置等。
2. 缺失数据处理
对于数据集中的缺失值,需要根据相关信息,来处理缺失数据。使用均值、中间值,或者众数、相似数等方式来填充缺失值,当然如果缺失值过高,直接丢弃也是可以的。
3. 数据定标
归一化和标准化
归一化:把数据归一化为0到1之间
标准化:把数据标准化为正态分布数据
4. 数据转换
独热编码:
把数据变换为0或1的值
1.5 实战-读取数据和可视化
# 导入相关库
import pandas as pd
import numpy as np
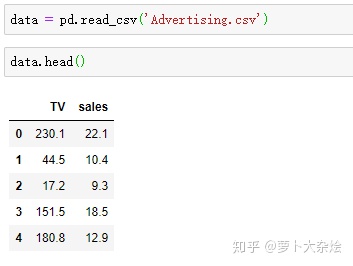
import matplotlib.pyplot as plt使用 pandas 读取 csv 文件
data = pd.read_csv('Advertising.csv')
data.head()output
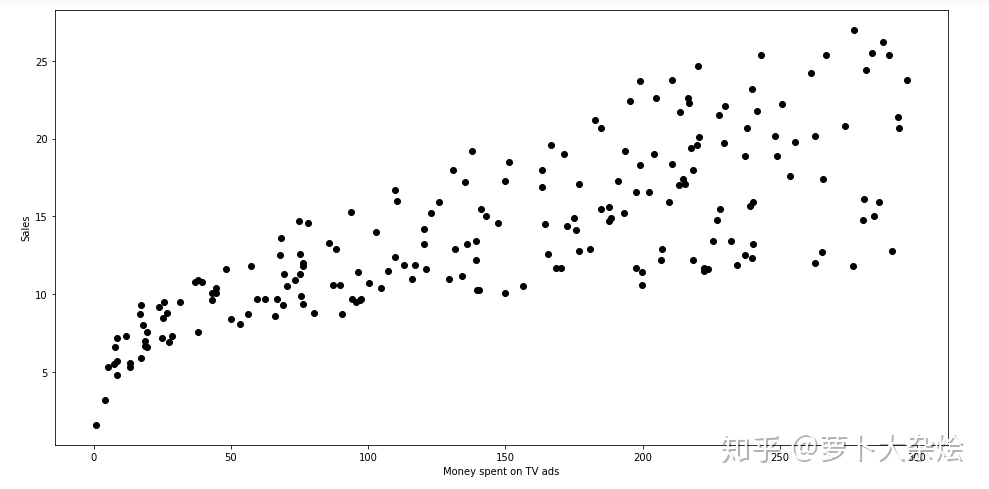
使用图表来展示数据,这样能够更加直观的查看数据分布等信息
plt.figure(figsize=(16, 8))
plt.scatter(data['TV'], data['sales'], c ='black')
plt.xlabel("Money spent on TV ads")
plt.ylabel("Sales")
plt.show()output
海拔高度与温度的预测练习
h_data = pd.read_csv('height.csv')
h_data
plt.figure()
plt.scatter(h_data['height'], h_data['temperature'])
plt.xlabel('height')
plt.ylabel('temperature')
plt.show()
h_X = h_data['height'].values.reshape(-1, 1)
h_y = h_data['temperature'].values.reshape(-1, 1)
h_reg = LinearRegression()
h_reg.fit(h_X, h_y)
print("线性模型为: Y = {:.5}X + {:.5} ".format(h_reg.coef_[0][0], h_reg.intercept_[0]))
h_height = h_reg.predict([[8000]])
h_height[0][0]2. “Hello world”级别算法-KNN
2.1 什么是 KNN 算法
做 K 最近邻算法,如果样本总共分为 N 类,如果一个未知分类点,距离某一类的距离最近,则该点属于该类。
K 一般取值为奇数值,代表选取 K 个点的距离。
kNN 算法的核心思想是如果一个样本在特征空间中的 k 个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。--来自百度百科
2.2 距离的计算
欧式距离的计算:
二维平面上两点 a(x1,y1) 与 b(x2,y2) 间的欧氏距离:
三维空间两点 a(x1,y1,z1)与b(x2,y2,z2) 间的欧氏距离:
两个 n 维向量 a(x11,x12,…,x1n) 与 b(x21,x22,…,x2n) 间的欧氏距离:
2.3 手写 KNN 算法
计算欧式距离
def euc_dis(instance1, instance2):dist = np.sqrt(sum((instance1 - instance2)**2))return distdist 的计算就是,求两个向量差的平方和,再取平方根。
我们可以使用 numpy 库自带的公式来验证下
import numpy as npdef euc_dis(instance1, instance2):dist = np.sqrt(sum((instance1 - instance2)**2))return distvec1 = np.array([2, 3])
vec2 = np.array([5, 6])
euc_dis(vec1, vec2)np.linalg.norm(vec1 - vec2)最后的结果都是 4.242640687119285
实现 KNN 算法
def knn_classify(X, y, testdata, k):distances = [euc_dis(x, testdata) for x in X]kneighbors = np.argsort(distances)[:k]count = Counter(y[kneighbors])return count.most_common()[0][0]argsort 函数返回的是数组值从小到大的索引值,most_common 函数用来实现 Top n 功能。
来看下这两个函数的具体实例
argsort
test_data1 = np.array([2, 1, 5, 0])
np.argsort(test_data1)output
array([3, 1, 0, 2], dtype=int32)返回的数组依次为最小值0的索引位置3,依次类推
most_common
from collections import Counter
test_data2 = Counter("abcdabcab")
test_data2.most_common(2)output
[('a', 3), ('b', 3)]返回出现次数最多的 top n
使用手写的 KNN 算法做预测
# 导入iris数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2003)
# 预测结果。
predictions = [knn_classify(X_train, y_train, data, 3) for data in X_test]
print(predictions)
correct = np.count_nonzero((predictions==y_test)==True)
print(correct)
print ("Accuracy is: %.3f" %(correct/len(X_test)))2.4 K 值的选择(调参)
2.4.1 决策边界
可以将决策边界一侧的所有点分类为属于一个类,而将另一侧的所有点分类为属于另一个类。决策边界选择的好坏,直接影响着模型预测的准确程度。
总结:决策边界过于粗糙,会导致欠拟合,而过于精细,就会有过拟合的风险。
KNN 算法中的决策边界,就是确定 K 的值,到底选取 K 为几才是最优的解。
2.4.2 交叉验证
为了确定 K 的值,可以采用交叉验证的方式。
首先,当我们拿到一组数据之后,先把数据拆分为训练集和测试集,训练集用于训练模型,测试集用于测试模型的准确率。

测试集不可用于训练!测试集不可用于训练!测试集不可用于训练!(重要的事情吼三遍)
然后,再把训练集拆分成训练集和验证集。这里的验证集,是用来给交叉验证时使用的.

比如,如果我们想做5轮交叉验证,那么就分别把最原始的训练集分成5中情况,如图:

接着,分别取 K=1,K=3,K=5 等情况在上述5种数据集中分别训练验证,得出准确率最高的 K 值,此时,我们就通过交叉验证的方式,找到了在该数据集下的最优 K 值。
最后,才会在测试集上做最后的测试,如果模型在测试集上达到了我们预期的准确率,则模型可用。