网站结构图怎么画上海网络seo优化公司
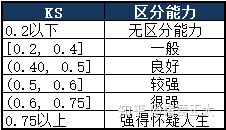
本篇内容来自《信用评分工具》一书的8.3KS统计量。
KS统计量全称为Kolmogorov-Smirnov统计量,基于经验累积分布函数,是一种非参数的统计检验方法,用于检验两个分布是否一致。对于两个分布,其计算公式如下:
其中
而在信用评分卡中的KS,借鉴的正是上式中的
KS不会为负值,因为违约组主要分布在低分区域,按照评分由低到高排序,违约组的累积概率会先于未违约组到1,因此二者累积概率差值的最大值不会小于0。
以上是对KS的理论上的解释,那么在业务上如何理解呢?在信用评分卡中,通常会选择一个分数作为阈值,信用评分不高于这个阈值的客户会被拒绝,但在被拒绝的客户中,难免会存在信用实际良好不存在违约的客户,那么我们会希望违约的客户尽量多地被拒绝,这个用tpr(也称为灵敏度或召回率)来衡量,即违约组的累积概率;被拒绝而未违约的客户尽量少地被拒绝,这个用fpr(也称为假阳性率)来衡量,即为违约组的累积概率。二者公式如下:
其中,tp即被拒绝客户中实际违约的客户数,p为整体违约客户总数;fp为被拒绝客户中实际未违约客户数,n为整体未违约客户总数。我们希望tpr尽可能大,而fpr尽可能小,而KS的公式为:
那么自然而然KS越大,说明我在尽量减少误伤优秀客户的情况下,排除了尽可能多的坏客户。
KS的计算步骤一般如下:
1、将所有客户按照信用评分升序排列(如果是违约概率则为降序排列);
2、计算每一个分数下(或者将分数进行十等分,等频或者等距,计算每一分数段下)违约客户数和未违约客户数;
3、按照排序分别计算每一分数下(或分数段下)累计违约客户数与整体违约客户总数的比值tpr,累计未违约客户数与整体未违约客户总数的比值fpr;
4、用tpr减fpr即得到每个分数或分数段对应的KS。
python代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('seaborn-white')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
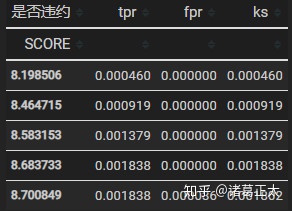
data = pd.read_excel('score.xlsx', index = False, header = 0)def KS(score_df, score, y, path):'''计算KS统计表和KS图形score_df 分布图y 是非违约字段的名称score 信用评分字段的名称path 输出路径返回:KS图形,KS统计表,表中字段包含分数(由小到大排列),累计违约占比,累计未违约占比,KS值'''score_df = score_df.sort_values(by = score, ascending = True)total_bad = score_df[y].sum()total_good = score_df.shape[0] - total_badscore_df = pd.crosstab(index = score_df[score], columns = score_df[y]).fillna(0) #计算每个分数对应的违约客户数和未违约客户数score_df['tpr'] = score_df[1].cumsum() / total_bad #计算tprscore_df['fpr'] = score_df[0].cumsum() / total_good #计算fprscore_df['ks'] = score_df.tpr - score_df.fpr #计算ksmax_ks = score_df.ks.max() #取最大ksmax_ks_score = score_df[score_df.ks == max_ks].index.values[0] #取最大KS对应的分数score_df.tpr.plot(label = 'tpr', c = 'red')score_df.fpr.plot(label = 'fpr', c = 'green')score_df.ks.plot(label = 'ks', c = 'black')plt.text(max_ks_score, max_ks, s = f'{max_ks_score:.2f}, {max_ks:.4f}')plt.legend()plt.savefig(path)plt.show()return score_df.loc[:, ['tpr', 'fpr', 'ks']]ks_df = KS(data, 'SCORE', '是否违约', 'KS.jpg')
ks_df.head()图形输出如下:
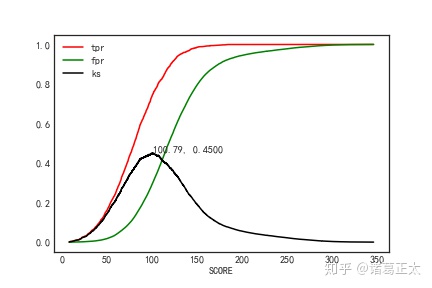
从上图中可以得到,当选取100.79作为阈值时,KS最大为0.45。那么我们是不是就选择KS最大值所对应的分数作为实际评分卡中的阈值呢?KS更多的是评估模型的区分能力,在具体选择阈值中要结合实际业务需要,综合tp、fp、tn和fn的占比(参考第八章评价测度之混淆矩阵),考量违约率和产品的预计盈利等情况。