重庆工程建设招标网官方网站/长沙营销型网站建设
1、调试介绍
Linux 0.11-调试 Linux 最早期的代码-36
2、启动跟踪
BIOS 加载
电脑启动,CPU指向0xFFFFFFF0处,这里正好是系统ROM BIOS存放的地址。即开始执行BIOS指令。为了保持向下兼容,就会把与原PC兼容的BIOS代码和数据复制到低端1M末端的64K处。最后BIOS会把操作系统引导程序加载到内存0x7c00处。如下图:
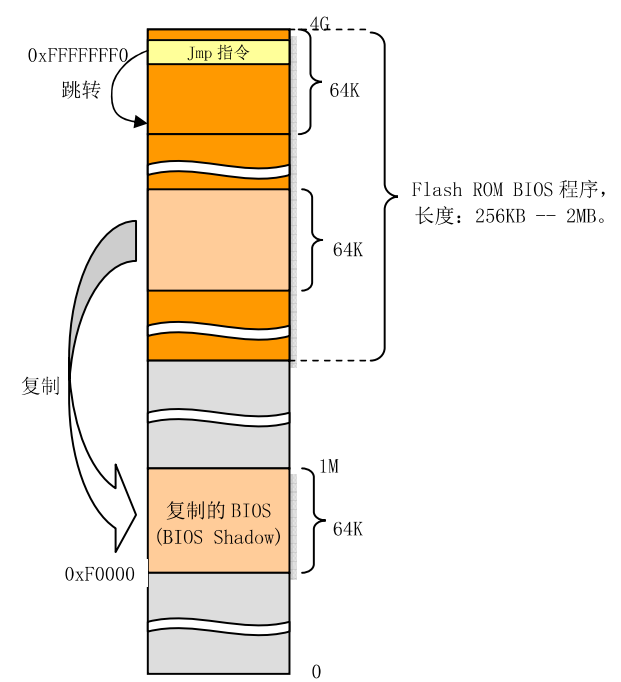
bootsect.s
bootsect.s 把自己移动到内存0x90000(576KB)处,并把启动设备中后2KB字节代码(setup.s)读入到内存0x90200处,并把内核其它部分(system模块)读入到0x10000(64KB)处。
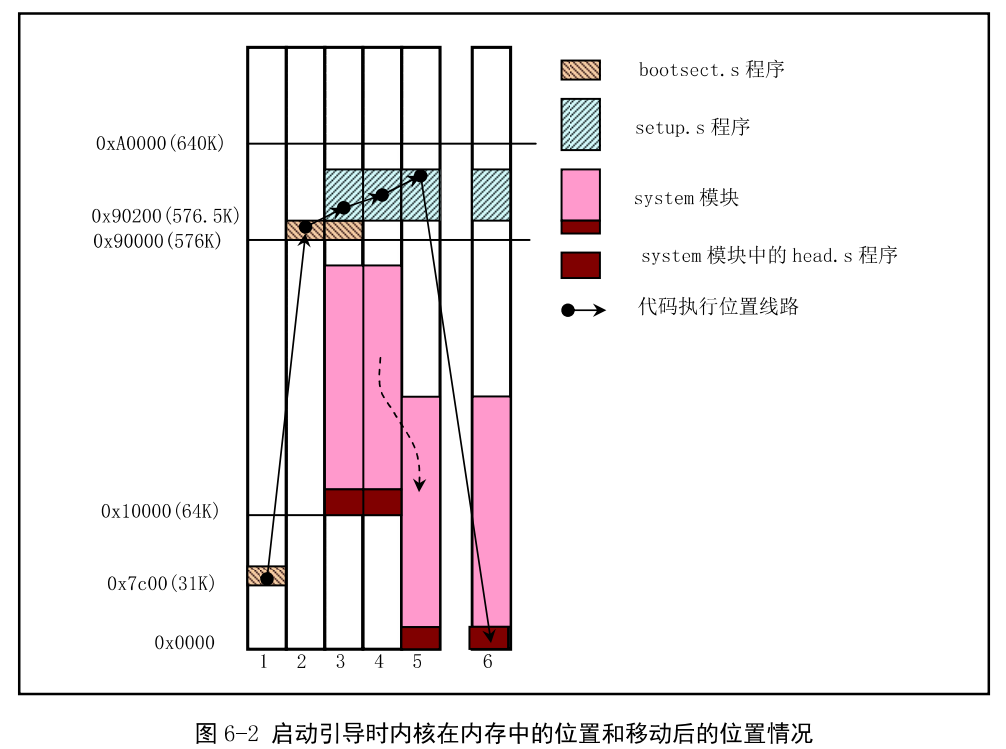
setup.s
setup.s把system模块移动到内存0处。最后会调用system模块。其内存如下:
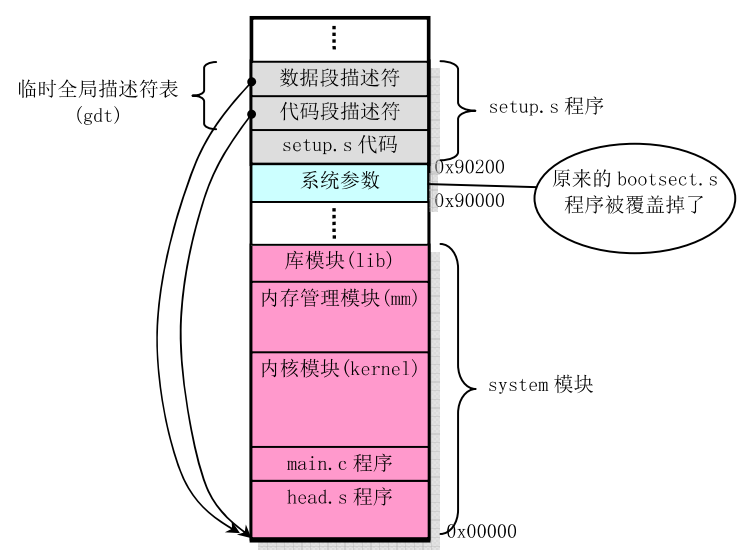
head.s
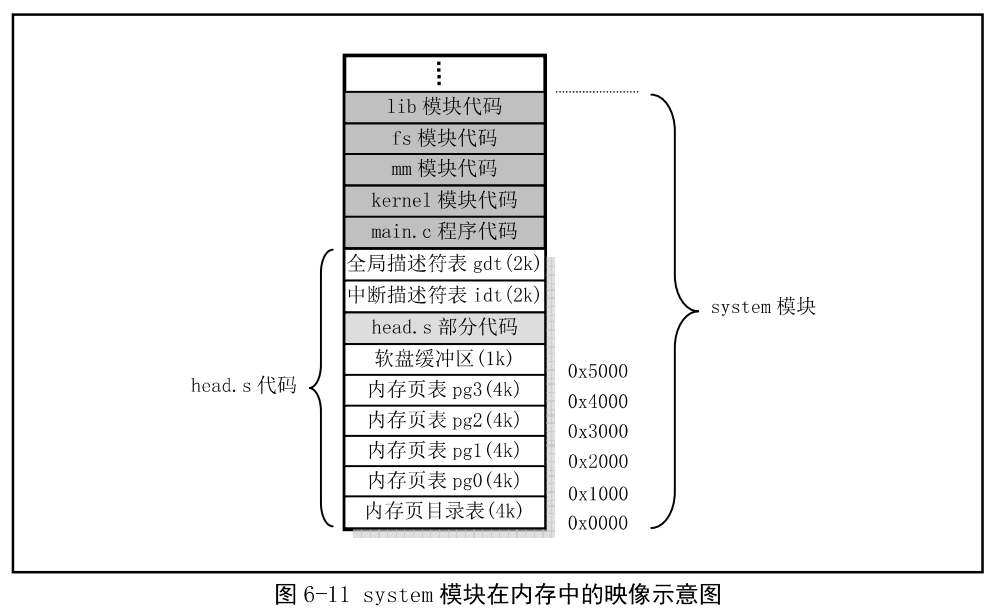
head.s位于system模块的开头处,setup.s把控制权交给head.s后,head.s程序执行结束后,其内存如下:
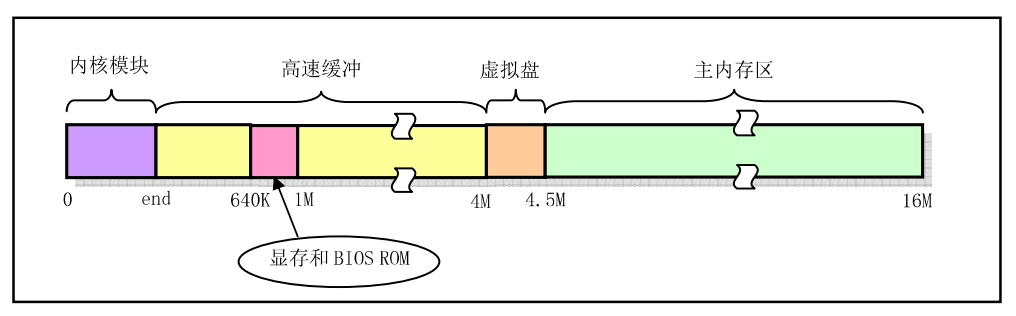
高速缓冲部分还要扣除被显存和ROM BIOS占用的部分,其用于磁盘等块设备临时存放数据的地方,在buffer_init函数中初始化。主内存区由内存管理模块mm通过分页机制进行管理分配。
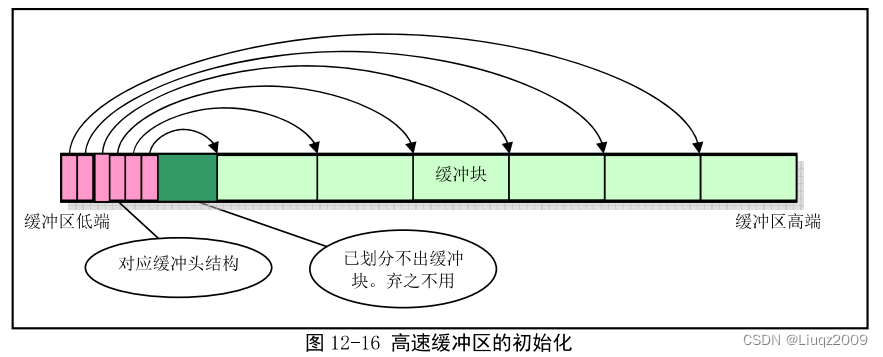
高速缓冲区初始化过程中,初始化程序从整个缓冲区的两端开始,分别同时设置缓冲块头结构和划分出对应的缓冲区块(1K)。缓冲区的高端被划分成一个个1K的缓冲块,低端则分别建立起对应各缓冲块的缓冲头结构buffer_head。该头结构用于描述对应缓冲块的属性,并且用于把所有缓冲头连接成链表。
struct buffer_head {char * b_data; /* 指向该缓冲块中数据区(1K字节)的指针 */unsigned long b_blocknr; /* 块号 */unsigned short b_dev; /* 数据源的块设备号 (0 = free) */unsigned char b_uptodate; /* 更新标志,表示数据是否已更新 */unsigned char b_dirt; /* 修改标志,0-未修改clean,1-已修改dirty */unsigned char b_count; /* 使用该块的用户个数 */unsigned char b_lock; /* 缓冲区是否被锁定。0 - ok, 1 -locked */struct task_struct * b_wait; /* 指向等待该缓冲区解锁的任务 */struct buffer_head * b_prev; /* hash 队列上前一块 */struct buffer_head * b_next; /* hash 队列上下一块 */struct buffer_head * b_prev_free; /* 空闲表上前一块 */struct buffer_head * b_next_free; /* 空闲表下前一块 */
};// fs/buffer.c
// end 为内核模块结束地址
struct buffer_head * start_buffer = (struct buffer_head *) &end;void buffer_init(long buffer_end)
{struct buffer_head * h = start_buffer;void * b;int i;// 640K ~ 1M 为显示区域和BIOS区域(1M末端处,大小为64K)if (buffer_end == 1<<20)b = (void *) (640*1024);elseb = (void *) buffer_end;while ( (b -= BLOCK_SIZE) >= ((void *) (h+1)) ) {h->b_dev = 0;h->b_dirt = 0;h->b_count = 0;h->b_lock = 0;h->b_uptodate = 0;h->b_wait = NULL;h->b_next = NULL;h->b_prev = NULL;h->b_data = (char *) b;h->b_prev_free = h-1;h->b_next_free = h+1;h++;NR_BUFFERS++;if (b == (void *) 0x100000)b = (void *) 0xA0000;}h--;free_list = start_buffer;free_list->b_prev_free = h;h->b_next_free = free_list;for (i=0;i<NR_HASH;i++)hash_table[i]=NULL;
} 初始化后的示意图:
内存管理初始化代码,mem_map进行管理内存是否有使用。每个字符管理4K大小内存。
// mm/memory.c
static unsigned char mem_map [ PAGING_PAGES ] = {0,};
void mem_init(long start_mem, long end_mem)
{int i;HIGH_MEMORY = end_mem;for (i=0 ; i<PAGING_PAGES ; i++)mem_map[i] = USED;i = MAP_NR(start_mem);end_mem -= start_mem;end_mem >>= 12;while (end_mem-->0)mem_map[i++]=0;
}
head.s最后会调用main.c中的main()函数。
main
void main(void) /* This really IS void, no error here. */
{ /* The startup routine assumes (well, ...) this */
/** Interrupts are still disabled. Do necessary setups, then* enable them*/ROOT_DEV = ORIG_ROOT_DEV;drive_info = DRIVE_INFO;memory_end = (1<<20) + (EXT_MEM_K<<10);memory_end &= 0xfffff000;if (memory_end > 16*1024*1024)memory_end = 16*1024*1024;if (memory_end > 12*1024*1024) buffer_memory_end = 4*1024*1024;else if (memory_end > 6*1024*1024)buffer_memory_end = 2*1024*1024;elsebuffer_memory_end = 1*1024*1024;main_memory_start = buffer_memory_end;
#ifdef RAMDISKmain_memory_start += rd_init(main_memory_start, RAMDISK*1024);
#endifmem_init(main_memory_start,memory_end);trap_init();blk_dev_init();chr_dev_init();tty_init();time_init();sched_init();buffer_init(buffer_memory_end);hd_init();floppy_init();sti();move_to_user_mode();if (!fork()) { /* we count on this going ok */init();}
/** NOTE!! For any other task 'pause()' would mean we have to get a* signal to awaken, but task0 is the sole exception (see 'schedule()')* as task 0 gets activated at every idle moment (when no other tasks* can run). For task0 'pause()' just means we go check if some other* task can run, and if not we return here.*/for(;;) pause();
}3、fork
Linux 系统中创建新进程使用 fork()系统调用。所有进程都是通过复制进程0而得到的,都是进程0的子进程。在创建新进程的过程中,系统首先在任务数组中找出一个还没有被任何进程使用的空项(task[NR_TASKS])。
然后系统为新建进程在主内存区中申请一页内存(4K大小)来存放其任务数据结构信息,并复制当前进程任务数据结构中的所有内容作为新进程任务数据结构的模板。
随后对复制的任务数据结构进行修改。设置初始运行时间片为15个系统滴答数(150ms)。接着根据当前进程设置任务状态段TSS中各寄存器的值。新建进程内核态堆栈指针tss.esp0被设置成新进程任务数据结构所在内存页面的顶端,而堆栈段tss.ss0被设置成内核数据段选择符。tss.ldt被设置为局部表描述符在GDT中的索引值。
此后系统设置新任务的代码和数据段基址、限长,并复制当前进程内存分页管理的页表。注意,此时系统并不为新的进程分配实际的物理内存页面,而是让它共享其父进程的内存页面。只有当父进程或新进程中任意一个有写内存操作时,系统才会为执行写操作的进程分配相关的独立使用的内存页面。
随后,如果父进程中有文件是打开的,则应将对应文件的打开次数增加1.接着在GDT中设置新任务的TSS和LDT描述符项,其中基地址信息指向新进程任务结构中的tss和ldt。最后再将新任务设置成可运行状态并返回新进程号。
task_struct 结构体
struct tss_struct {long back_link; /* 16 high bits zero */long esp0;long ss0; /* 16 high bits zero */long esp1;long ss1; /* 16 high bits zero */long esp2;long ss2; /* 16 high bits zero */long cr3;long eip;long eflags;long eax,ecx,edx,ebx;long esp;long ebp;long esi;long edi;long es; /* 16 high bits zero */long cs; /* 16 high bits zero */long ss; /* 16 high bits zero */long ds; /* 16 high bits zero */long fs; /* 16 high bits zero */long gs; /* 16 high bits zero */long ldt; /* 16 high bits zero */long trace_bitmap; /* bits: trace 0, bitmap 16-31 */struct i387_struct i387;
};struct task_struct {
/* these are hardcoded - don't touch *//* 任务的运行状态(-1 不可运行,0 可运行(就绪), >0 已停止) */long state; /* -1 unrunnable, 0 runnable, >0 stopped *//* 任务运行时间计数(递减)(滴答数),运行时间片 */long counter;/* 运行优先数。任务开始运行时 counter = priority,越大运行越长 */long priority;/* 信号。是位图,每个比特位代表一种信号,信号值=位偏移值+1 */long signal;/* 信号执行属性结构,对应信号将要执行的操作和标志信息 */struct sigaction sigaction[32];/* 进程信号屏蔽码(对应信号位图) */long blocked; /* bitmap of masked signals */
/* various fields *//* 任务执行停止的退出码,其父进程会取 */int exit_code;/* 代码段地址 */unsigned long start_code;/* 代码长度(字节数) */unsinged long end_code;/* 代码长度 + 数据长度(字节数) */unsigned long end_data;/* 总长度(字节数) */unsigned long brk;/* 堆栈段地址 */unsigned long start_stack;/* 进程标识号(进程号) */long pid;/* 父进程号 */long father;/* 进程组号 */long pgrp;/* 会话号 */long session;/* 会话首领 */long leader;/* 用户标识号(用户 id) */unsigned short uid;/* 有效用户 id */unsigned short euid;/* 保存的用户 id */unsigned short suid;/* 组标识号(组 id) */unsigned short gid;/* 有效组 id */unsigned short egid;/* 保存的组 id */unsigned short sgid;/* 报警定时值(滴答数) */long alarm;/* 用户态运行时间(滴答数) */long utime;/* 系统态运行时间(滴答数) */long stime;/* 子进程用于态运行时间 */long cutime;/* 子集成系统态运行时间 */long cstime;/* 进程开始运行时刻 */long start_time;/* 标志:是否使用了协处理器 */unsigned short used_math;
/* file system info *//* 进程使用 tty 的子设备号。-1 表示没有使用 */int tty; /* -1 if no tty, so it must be signed *//* 文件创建属性屏蔽位 */unsigned short umask;/* 当前工作目录 i 节点结构 */struct m_inode * pwd;/* 根目录 i 节点结构 */struct m_inode * root;/* 执行文件 i 节点结构 */struct m_inode * executable;/* 执行时关闭文件句柄位图标志 */unsigned long close_on_exec;/* 进程使用的文件表结构 */struct file * filp[NR_OPEN];/* 本任务的局部表描述符。 0 空, 1 代码段 cs, 2 数据段和堆栈段 ds&ss */
/* ldt for this task 0 - zero 1 - cs 2 - ds&ss */struct desc_struct ldt[3];/* 本进程的任务状态段信息结构 */
/* tss for this task */struct tss_struct tss;
};fork() 函数在main.c中定义:
// init/main.c
static inline _syscall0(int,fork)// include/unistd.h
#define _syscall0(type,name) \type name(void) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \: "=a" (__res) \: "0" (__NR_##name)); \
if (__res >= 0) \return (type) __res; \
errno = -__res; \
return -1; \
}其展开后就是定义了fork函数为:
static inline int fork(void) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \: "=a" (__res) \: "0" (__NR_fork)); \
if (__res >= 0) \return (type) __res; \
errno = -__res; \
return -1; \
}// include/unistd.h
#define __NR_fork 2即调用参数为0的系统调用。系统调用通过0x80陷入。在kernel/sched.c的sched_init函数中设置了中断0x80的处理函数为system_call(其代码在kernel/system_call.s中。)。
// kernel/sched.c
void sched_init(void)
{// ...set_system_gate(0x80,&system_call);
}system_call
# kernel/system_call.s
.globl system_call,sys_fork,timer_interrupt,sys_execve
.globl hd_interrupt,floppy_interrupt,parallel_interrupt
.globl device_not_available, coprocessor_error.align 2
bad_sys_call:movl $-1,%eaxiret
.align 2
reschedule:pushl $ret_from_sys_calljmp schedule
.align 2
system_call:cmpl $nr_system_calls-1,%eaxja bad_sys_callpush %dspush %espush %fspushl %edxpushl %ecx # push %ebx,%ecx,%edx as parameterspushl %ebx # to the system callmovl $0x10,%edx # set up ds,es to kernel spacemov %dx,%dsmov %dx,%esmovl $0x17,%edx # fs points to local data spacemov %dx,%fscall *sys_call_table(,%eax,4) # 调用地址sys_call_table + 4 * %eaxpushl %eaxmovl current,%eaxcmpl $0,state(%eax) # statejne reschedulecmpl $0,counter(%eax) # counterje reschedule
ret_from_sys_call:movl current,%eax # task[0] cannot have signalscmpl task,%eaxje 3fcmpw $0x0f,CS(%esp) # was old code segment supervisor ?jne 3fcmpw $0x17,OLDSS(%esp) # was stack segment = 0x17 ?jne 3fmovl signal(%eax),%ebxmovl blocked(%eax),%ecxnotl %ecxandl %ebx,%ecxbsfl %ecx,%ecxje 3fbtrl %ecx,%ebxmovl %ebx,signal(%eax)incl %ecxpushl %ecxcall do_signalpopl %eax
3: popl %eaxpopl %ebxpopl %ecxpopl %edxpop %fspop %espop %dsiret其会调用sys_call_table中预定义的函数,此处即为sys_fork。
// include/linux/sys.h
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,
sys_unlink, sys_execve, sys_chdir, sys_time, sys_mknod, sys_chmod,
sys_chown, sys_break, sys_stat, sys_lseek, sys_getpid, sys_mount,
sys_umount, sys_setuid, sys_getuid, sys_stime, sys_ptrace, sys_alarm,
sys_fstat, sys_pause, sys_utime, sys_stty, sys_gtty, sys_access,
sys_nice, sys_ftime, sys_sync, sys_kill, sys_rename, sys_mkdir,
sys_rmdir, sys_dup, sys_pipe, sys_times, sys_prof, sys_brk, sys_setgid,
sys_getgid, sys_signal, sys_geteuid, sys_getegid, sys_acct, sys_phys,
sys_lock, sys_ioctl, sys_fcntl, sys_mpx, sys_setpgid, sys_ulimit,
sys_uname, sys_umask, sys_chroot, sys_ustat, sys_dup2, sys_getppid,
sys_getpgrp, sys_setsid, sys_sigaction, sys_sgetmask, sys_ssetmask,
sys_setreuid,sys_setregid, sys_iam, sys_whoami };sys_fork
sys_fork 在 system_call.s中定义。
# kernel/system_call.s
.align 2
sys_fork:call find_empty_processtestl %eax,%eaxjs 1fpush %gspushl %esipushl %edipushl %ebppushl %eaxcall copy_processaddl $20,%esp
1: retsys_fork 先调用find_empty_process函数找到空闲的进程(内核中定义了64个,NR_TASKS),其返回内部进程序列。然后调用copy_process函数
find_empty_process
为新进程取得不重复的进程号。函数返回在任务数组中的任务号。
// kernel/fork.c
int find_empty_process(void)
{int i;repeat:if ((++last_pid)<0) last_pid=1;for(i=0 ; i<NR_TASKS ; i++)if (task[i] && task[i]->pid == last_pid) goto repeat;for(i=1 ; i<NR_TASKS ; i++) // 任务0项,因为常驻,所以不使用if (!task[i])return i;return -EAGAIN;
}copy_process
用于创建并复制进程的代码段和数据段以及环境。在进程复制过程中,工作主要牵涉到进程数据结构中信息的设置。系统首先为新建进程在主内存区中申请一页内存来存放其任务数据结构信息,并复制当前进程任务数据结构中的所有内容作为新进程任务数据结构的模板。
// kernel/fork.c
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,long ebx,long ecx,long edx,long fs,long es,long ds,long eip,long cs,long eflags,long esp,long ss)
{struct task_struct *p;int i;struct file *f;p = (struct task_struct *) get_free_page();if (!p)return -EAGAIN;task[nr] = p;// NOTE!: the following statement now work with gcc 4.3.2 now, and you// must compile _THIS_ memcpy without no -O of gcc.#ifndef GCC4_3*p = *current; /* NOTE! this doesn't copy the supervisor stack */p->state = TASK_UNINTERRUPTIBLE;p->pid = last_pid;p->father = current->pid;p->counter = p->priority;p->signal = 0;p->alarm = 0;p->leader = 0; /* process leadership doesn't inherit */p->utime = p->stime = 0;p->cutime = p->cstime = 0;p->start_time = jiffies;p->tss.back_link = 0;p->tss.esp0 = PAGE_SIZE + (long) p;p->tss.ss0 = 0x10;p->tss.eip = eip;p->tss.eflags = eflags;p->tss.eax = 0;p->tss.ecx = ecx;p->tss.edx = edx;p->tss.ebx = ebx;p->tss.esp = esp;p->tss.ebp = ebp;p->tss.esi = esi;p->tss.edi = edi;p->tss.es = es & 0xffff;p->tss.cs = cs & 0xffff;p->tss.ss = ss & 0xffff;p->tss.ds = ds & 0xffff;p->tss.fs = fs & 0xffff;p->tss.gs = gs & 0xffff;p->tss.ldt = _LDT(nr);p->tss.trace_bitmap = 0x80000000;if (last_task_used_math == current)__asm__("clts ; fnsave %0"::"m" (p->tss.i387));if (copy_mem(nr,p)) {task[nr] = NULL;free_page((long) p);return -EAGAIN;}for (i=0; i<NR_OPEN;i++)if ((f=p->filp[i]))f->f_count++;if (current->pwd)current->pwd->i_count++;if (current->root)current->root->i_count++;if (current->executable)current->executable->i_count++;set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss));set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt));p->state = TASK_RUNNING; /* do this last, just in case */return last_pid;
}copy_mem
复制内存页表。参数nr是新任务号,p是新任务数据结构指针。该函数为新任务在线性地址空间中设置代码段和数据段基址、限长,并复制页表。由于Linux采用了写时复制技术,因此这里仅为新进程设置自己的页目录表项和页表项,而没有实际为新进程分配物理内存页面。此时新进程与其父进程共享所有内存页面。
int copy_mem(int nr,struct task_struct * p)
{unsigned long old_data_base,new_data_base,data_limit;unsigned long old_code_base,new_code_base,code_limit;code_limit=get_limit(0x0f);data_limit=get_limit(0x17);old_code_base = get_base(current->ldt[1]);old_data_base = get_base(current->ldt[2]);if (old_data_base != old_code_base)panic("We don't support separate I&D");if (data_limit < code_limit)panic("Bad data_limit");new_data_base = new_code_base = nr * 0x4000000;p->start_code = new_code_base;set_base(p->ldt[1],new_code_base);set_base(p->ldt[2],new_data_base);if (copy_page_tables(old_data_base,new_data_base,data_limit)) {printk("free_page_tables: from copy_mem\n");free_page_tables(new_data_base,data_limit);return -ENOMEM;}return 0;
}4、缺页处理
该文件包括页异常中断处理程序(中断 14),主要分两种情况处理。一是由于缺页引起的页异常中
断,通过调用 do_no_page(error_code, address)来处理;二是由页写保护引起的页异常,此时调用页写保护处理函数 do_wp_page(error_code, address)进行处理。其中的出错码(error_code)是由 CPU 自动产生并压入堆栈的,出现异常时访问的线性地址是从控制寄存器 CR2 中取得的。CR2 是专门用来存放页出错时的线性地址。
mm/page.s
.globl page_faultpage_fault:xchgl %eax,(%esp)pushl %ecxpushl %edxpush %dspush %espush %fsmovl $0x10,%edxmov %dx,%dsmov %dx,%esmov %dx,%fsmovl %cr2,%edxpushl %edxpushl %eaxtestl $1,%eaxjne 1fcall do_no_pagejmp 2f
1: call do_wp_page
2: addl $8,%esppop %fspop %espop %dspopl %edxpopl %ecxpopl %eaxiretdo_wp_page函数
mm/memory.c
void un_wp_page(unsigned long * table_entry)
{unsigned long old_page,new_page;old_page = 0xfffff000 & *table_entry;if (old_page >= LOW_MEM && mem_map[MAP_NR(old_page)]==1) {*table_entry |= 2;invalidate();return;}if (!(new_page=get_free_page()))oom();if (old_page >= LOW_MEM)mem_map[MAP_NR(old_page)]--;*table_entry = new_page | 7;invalidate();copy_page(old_page,new_page);
} /** This routine handles present pages, when users try to write* to a shared page. It is done by copying the page to a new address* and decrementing the shared-page counter for the old page.** If it's in code space we exit with a segment error.*/
void do_wp_page(unsigned long error_code,unsigned long address)
{
#if 0
/* we cannot do this yet: the estdio library writes to code space */
/* stupid, stupid. I really want the libc.a from GNU */if (CODE_SPACE(address))do_exit(SIGSEGV);
#endifun_wp_page((unsigned long *)(((address>>10) & 0xffc) + (0xfffff000 &*((unsigned long *) ((address>>20) &0xffc)))));}do_no_page函数
执行缺页处理。
// 是访问不存在页面处理函数。页异常中断处理过程中调用的函数。在 page.s 程序中被调用。
// 函数参数 error_code 和 address 是进程在访问页面时由 CPU 因缺页产生异常而自动生成。
// error_code 指出出错类型,参见本章开始处的"内存页面出错异常"一节;address 是产生
// 异常的页面线性地址。
// 该函数首先尝试与已加载的相同文件进行页面共享,或者只是由于进程动态申请内存页面而
// 只需映射一页物理内存页即可。若共享操作不成功,那么只能从相应文件中读入所缺的数据
// 页面到指定线性地址处。
void do_no_page(unsigned long error_code,unsigned long address)
{int nr[4];unsigned long tmp;unsigned long page;int block,i;// 首先取线性空间中指定地址 address 处页面地址。从而可算出指定线性地址在进程空间中
// 相对于进程基址的偏移长度值 tmp,即对应的逻辑地址。address &= 0xfffff000; // address 处缺页页面地址。tmp = address - current->start_code; // 缺页页面对应逻辑地址。
// 若当前进程的 executable 节点指针空,或者指定地址超出(代码 + 数据)长度,则申请
// 一页物理内存,并映射到指定的线性地址处。executable 是进程正在运行的执行文件的 i
// 节点结构。由于任务 0 和任务 1 的代码在内核中,因此任务 0、任务 1 以及任务 1 派生的
// 没有调用过 execve()的所有任务的 executable 都为 0。若该值为 0,或者参数指定的线性。
// 地址超出代码加数据长度,则表明进程在申请新的内存页面存放堆或栈中数据。因此直接
// 调用取空闲页面函数 get_empty_page() 为进程申请一页物理内存并映射到指定线性地址
// 处。进程任务结构字段 start_code 是线性地址空间中进程代码段地址,字段 end_data
// 是代码加数据长度。对于 Linux 0.11 内核,它的代码段和数据段起始基址相同。if (!current->executable || tmp >= current->end_data) {get_empty_page(address);return;}if (share_page(tmp))return;if (!(page = get_free_page()))oom();
/* remember that 1 block is used for header */block = 1 + tmp/BLOCK_SIZE;for (i=0 ; i<4 ; block++,i++)nr[i] = bmap(current->executable,block);bread_page(page,current->executable->i_dev,nr);i = tmp + 4096 - current->end_data;tmp = page + 4096;while (i-- > 0) {tmp--;*(char *)tmp = 0;}if (put_page(page,address))return;free_page(page);oom();
}
5、根文件系统读取
在init/main.c文件中有init函数,其开头有如下代码:
static inline _syscall1(int, setup, void *, BIOS)void init(void) {int pid, i;setup((void *)&drive_info);//...
}// 而_syscall1 在include/unistd.h中,定义为:
#define __NR_setup 0 /* used only by init, to get system going */#define _syscall1(type,name,atype,a) \
type name(atype a) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \: "=a" (__res) \: "0" (__NR_##name),"b" ((long)(a))); \
if (__res >= 0) \return (type) __res; \
errno = -__res; \
return -1; \
}static inline _syscall1(int, setup, void *, BIOS)定义了setup函数,其是一个系统调用宏,展开后为:
// __NR_##name 展开后为 __NR_setup, 而其又是一个宏定义,值为0
#define __NR_setup 0 /* used only by init, to get system going */// 展开后
static inline int setup(void* BIOS) {long __res; __asm__ volatile ("int $0x80" : "=a" (__res) : "0" (0),"b" ((long)(a))); if (__res >= 0) return (type) __res; errno = -__res; return -1;
}这是一个中断为0x80的软中断,其中断响应函数为kernel/system_call.s文件中的system_call函数。
system_call
.globl system_call,sys_fork,timer_interrupt,sys_execve
.globl hd_interrupt,floppy_interrupt,parallel_interrupt
.globl device_not_available, coprocessor_error.align 2
bad_sys_call:movl $-1,%eaxiret
.align 2
reschedule:pushl $ret_from_sys_calljmp schedule
.align 2
system_call:cmpl $nr_system_calls-1,%eaxja bad_sys_callpush %dspush %espush %fspushl %edxpushl %ecx # push %ebx,%ecx,%edx as parameterspushl %ebx # to the system callmovl $0x10,%edx # set up ds,es to kernel spacemov %dx,%dsmov %dx,%esmovl $0x17,%edx # fs points to local data spacemov %dx,%fscall *sys_call_table(,%eax,4)pushl %eaxmovl current,%eaxcmpl $0,state(%eax) # statejne reschedulecmpl $0,counter(%eax) # counterje reschedule
ret_from_sys_call:movl current,%eax # task[0] cannot have signalscmpl task,%eaxje 3fcmpw $0x0f,CS(%esp) # was old code segment supervisor ?jne 3fcmpw $0x17,OLDSS(%esp) # was stack segment = 0x17 ?jne 3fmovl signal(%eax),%ebxmovl blocked(%eax),%ecxnotl %ecxandl %ebx,%ecxbsfl %ecx,%ecxje 3fbtrl %ecx,%ebxmovl %ebx,signal(%eax)incl %ecxpushl %ecxcall do_signalpopl %eax
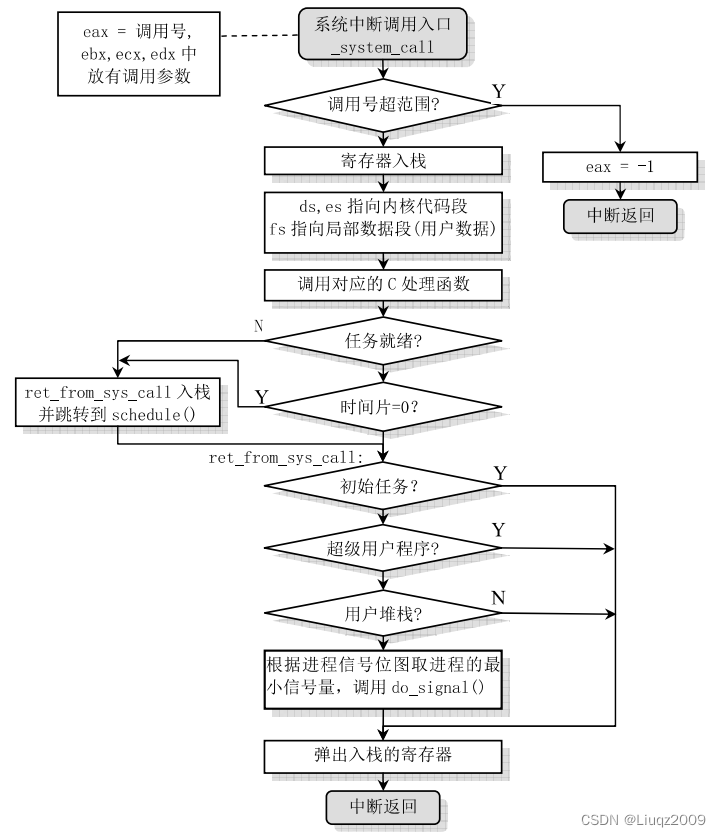
3: popl %eaxpopl %ebxpopl %ecxpopl %edxpop %fspop %espop %dsiret对于系统调用(int 0x80)的中断处理过程,可以把它看作是一个"接口"程序。实际上每个系统调用功能的处理过程基本上都是通过调用相应的 C 函数进行的。即所谓的"Bottom half"函数。
这个程序在刚进入时会首先检查 eax 中的功能号是否有效(在给定的范围内),然后保存一些会用到的寄存器到堆栈上。Linux 内核默认地巴段寄存器 ds,es 用于内核数据段,而 fs 用于用户数据段。接着通过一个地址跳转表(sys_call_table)调用相应系统调用的 C 函数。在 C 函数返回后,程序就把返回值压入堆栈保存起来。
接下来,该程序查看执行本次调用进程的状态。如果由于上面 C 函数的操作或其他情况而使进程的状态从执行态变成了其他状态,或者由于时间片已经用完(counter==0),则调用进程调度函数schedule()(jmp _schedule)。由于在执行"jmp _schedule"之前已经把返回地址 ret_from_sys_call 入栈,因此在执行完 schedule()后最终会返回到 ret_from_sys_call 处继续执行。
从 ret_from_sys_call 标号处开始的代码执行一些系统调用的后处理工作。主要判断当前进程是否是初始进程 0,如果是就直接退出此次系统调用,中断返回。否则再根据代码段描述符和所使用的堆栈来判断本次统调用的进程是否是一个普通进程,若不是则说明是内核进程(例如初始进程 1)或其他。则也立刻弹出堆栈内容退出系统调用中断。末端的一块代码用来处理调用系统调用进程的信号。若进程结构的信号位图表明该进程有接收到信号,则调用信号处理函数 do_signal()。
最后,该程序恢复保存的寄存器内容,退出此次中断处理过程并返回调用程序。若有信号时则程序会首先"返回"到相应信号处理函数中去执行,然后返回调用 system_call 的程序。
系统调用流程:
system_call函数会调用sys_call_table中定义的执行函数,而此处系统调用号为0,所以会调用sys_call_table[0],其为sys_setup函数。
sys_setup之一
sys_setup函数在kernel/blk_drv/hd.c文件中。其利用boot/setup.s程序提供的信息对系统中所含硬盘驱动器的参数进行了设置。然后读取硬盘分区表,并尝试把启动引导盘上的虚拟盘根文件系统映像文件复制到内存虚拟盘中,若成功则加载虚拟盘中的根文件系统,否则就继续执行普通根文件系统加载操作。
static struct hd_struct {long start_sect; // 分区在硬盘中的起始物理(绝对)扇区long nr_sects; // 分区中扇区总数
} hd[5*MAX_HD]={{0,0},};// 函数参数BIOS是由初始化程序 init/main.c 中 init 子程序设置为指向硬盘参数表结构的指针。
// 该硬盘参数表结构包含2个硬盘参数表的内容(共32字节),是从内存0x90080处复制而来。
int sys_setup(void * BIOS) {// ...for (i = NR_HD ; i < 2 ; i++) {hd[i*5].start_sect = 0;hd[i*5].nr_sects = 0;}// 前面省略的代码,确定了系统中所含的硬盘个数NR_HD(跟踪发现为1个)。现在我们来读取每个// 硬盘上第1个山区中的分区表信息,用来设置分区结构数组hd[]中硬盘各分区的信息。// 首先利用bread函数读取硬盘上第1个数据块(第1个参数为硬盘设备号,第2个参数为所需读取的块号),// 若读取成功,则数据会被存放在缓冲块bh的数据区中。// 然后根据硬盘第1个扇区最后两个字节是否为0xAA55来判断扇区中数据的有效性,若有效则取分区// 表信息(位于扇区偏移0x1BE处)。将分区表信息放入到hd[]中。最后释放bh缓冲区。for (drive=0 ; drive<NR_HD ; drive++) {if (!(bh = bread(0x300 + drive*5,0))) {printk("Unable to read partition table of drive %d\n\r",drive);panic("");}if (bh->b_data[510] != 0x55 || (unsigned char)bh->b_data[511] != 0xAA) {printk("Bad partition table on drive %d\n\r",drive);panic("");}p = 0x1BE + (void *)bh->b_data;for (i=1;i<5;i++,p++) {hd[i+5*drive].start_sect = p->start_sect;hd[i+5*drive].nr_sects = p->nr_sects;}brelse(bh);}if (NR_HD)printk("Partition table%s ok.\n\r",(NR_HD>1)?"s":"");rd_load(); // 尝试创建并加载虚拟盘mount_root(); // 安装根文件系统return (0);
}bread函数
bread函数位于fs/buffer.c中。
struct buffer_head * bread(int dev,int block)
{struct buffer_head * bh;if (!(bh=getblk(dev,block)))panic("bread: getblk returned NULL\n");if (bh->b_uptodate)return bh;ll_rw_block(READ,bh);// 注意此处会进入睡眠等待硬盘数据读取wait_on_buffer(bh);if (bh->b_uptodate)return bh;brelse(bh);return NULL;
}wait_on_buffer(bh); 进去睡眠等待读取硬盘缓冲区。
getblk函数用于获取一块空闲缓冲区块。其执行流程图如下:
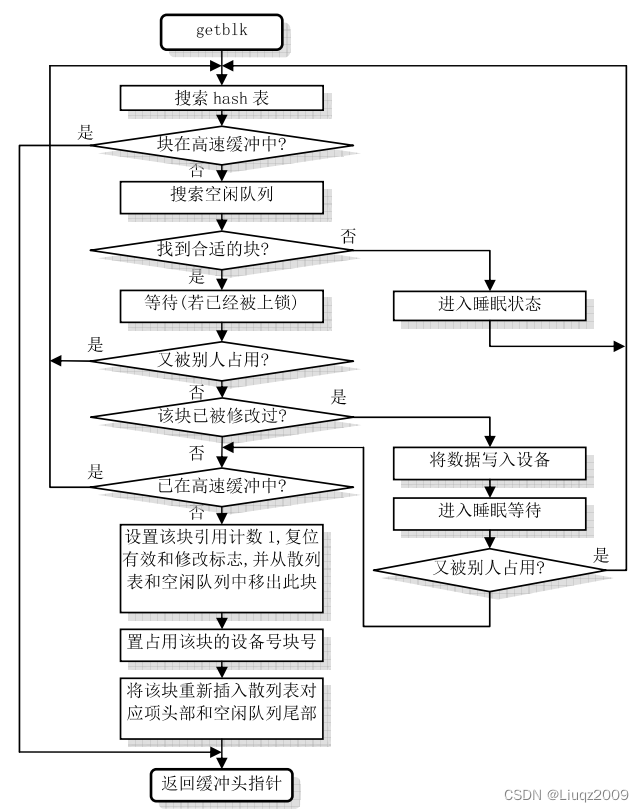
ll_rw_block
fs/buffer.c中struct buffer_head * bread(int dev,int block)函数会调用
kernel/blk_drv/ll_rw_blk.c中ll_rw_block函数。
ll_rw_block用来读写块设备中的数据。其为块设备创建块设备读写请求项,并插入到指定块设备请求队列中。实际的读写操作则是由设备的请求项处理函数request_fn()完成(硬盘为do_hd_request(),软盘为do_fd_request(),虚拟盘为do_rd_request())。
若ll_rw_block为一个块设备建立起一个请求项,并通过测试块设备的当前请求项指针为空而确定设备空闲时,就会设置该新建的请求项为当前请求项,并直接调用request_fn()对该请求项进行操作。否则就会使用电梯算法将新建的请求项插入到该设备的请求项链表中等待处理。而当request_fn()结束对一个请求项的处理,就会把该请求项从链表中删除。
由于request_fn()在每个请求项处理结束时,都有通过中断回调C函数(主要是read_intr和write_intr)再次调用request_fn()自身去处理链表中其余的请求项,因此,只要设备的请求项链表中有未处理的请求项存在,都会陆续地被处理,直到设备的请求项链表为空为止。
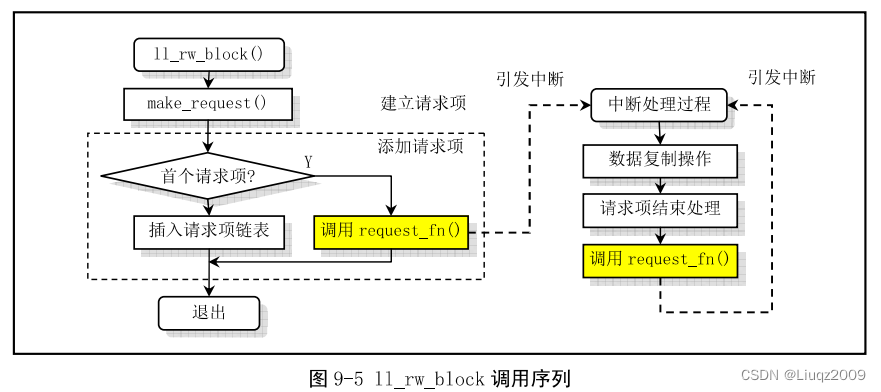
代码如下:
struct blk_dev_struct blk_dev[NR_BLK_DEV] = {{ NULL, NULL }, /* no_dev */{ NULL, NULL }, /* dev mem */{ NULL, NULL }, /* dev fd */{ NULL, NULL }, /* dev hd */{ NULL, NULL }, /* dev ttyx */{ NULL, NULL }, /* dev tty */{ NULL, NULL } /* dev lp */
};// 该函数把已经设置好的请求项req添加到指定设备的请求项链表中。如果该设备的当前请求项指针为空,
// 则可以设置req为当前请求项并立即调用设备请求项处理函数。否则就把req请求项插入到该请求项链表中
static void add_request(struct blk_dev_struct * dev, struct request * req)
{struct request * tmp;req->next = NULL;cli();if (req->bh)req->bh->b_dirt = 0;if (!(tmp = dev->current_request)) {// 当前没有请求,则直接调用请求函数,对于硬盘是 do_hd_request()dev->current_request = req;sti();(dev->request_fn)();return;}for ( ; tmp->next ; tmp=tmp->next)if ((IN_ORDER(tmp,req) || !IN_ORDER(tmp,tmp->next)) &&IN_ORDER(req,tmp->next))break;req->next=tmp->next;tmp->next=req;sti();
}// 创建请求项并插入请求队列中
// 参数major是主设备号,rw是指定命令,bh是存放数据的缓冲区头指针。
static void make_request(int major,int rw, struct buffer_head * bh)
{struct request * req;int rw_ahead;/* WRITEA/READA is special case - it is not really needed, so if the */
/* buffer is locked, we just forget about it, else it's a normal read */if ((rw_ahead = (rw == READA || rw == WRITEA))) {if (bh->b_lock)return;if (rw == READA)rw = READ;elserw = WRITE;}if (rw!=READ && rw!=WRITE)panic("Bad block dev command, must be R/W/RA/WA");// 在开始生成和添加相应的读写请求项前,我们再来看看此次是否有必要添加请求项。在两种情况下可以// 不必添加请求项。一是当命令是写,但缓冲区中的数据在读入之后并没有被修改过;二是当命令是读,// 但缓冲区中的数据已经是更新过的,即与块设备上的完全一样。lock_buffer(bh);if ((rw == WRITE && !bh->b_dirt) || (rw == READ && bh->b_uptodate)) {unlock_buffer(bh);return;}
repeat:
/* 我们不能让队列中全部是写请求项:读操作是优先的。请求队列的后三分之一空间仅* 用于读请求项。* 从后往前搜索一个空闲的请求项。request->dev为-1表示空闲。*/if (rw == READ)req = request+NR_REQUEST;elsereq = request+((NR_REQUEST*2)/3);
/* find an empty request */while (--req >= request)if (req->dev<0)break;
/* if none found, sleep on new requests: check for rw_ahead */if (req < request) {if (rw_ahead) {unlock_buffer(bh);return;}sleep_on(&wait_for_request);goto repeat;}
/* fill up the request-info, and add it to the queue */req->dev = bh->b_dev; // 设备号req->cmd = rw; // 命令(READ/WRITE)req->errors=0; // 操作时产生的错误次数req->sector = bh->b_blocknr<<1; // 起始扇区。块号转换成扇区号(1块=2扇区)req->nr_sectors = 2; // 本请求项需要读写的扇区数req->buffer = bh->b_data; // 请求项缓冲区指针指向需读写的数据缓冲区req->waiting = NULL; // 任务等待操作执行完成的地方req->bh = bh; // 缓冲块头指针req->next = NULL; // 指向下一请求项add_request(major+blk_dev,req); // 将请求项加入队列中,相当 (blk_dev[major], req)
}void ll_rw_block(int rw, struct buffer_head * bh)
{unsigned int major;if ((major=MAJOR(bh->b_dev)) >= NR_BLK_DEV ||!(blk_dev[major].request_fn)) {printk("Trying to read nonexistent block-device\n\r");return;}make_request(major,rw,bh);
}do_hd_request
kernel/blk_drv/hd.c
void do_hd_request(void)
{int i,r = 0;unsigned int block,dev;unsigned int sec,head,cyl;unsigned int nsect;INIT_REQUEST;dev = MINOR(CURRENT->dev);block = CURRENT->sector;if (dev >= 5*NR_HD || block+2 > hd[dev].nr_sects) {end_request(0);goto repeat;}block += hd[dev].start_sect;dev /= 5;__asm__("divl %4":"=a" (block),"=d" (sec):"0" (block),"1" (0),"r" (hd_info[dev].sect));__asm__("divl %4":"=a" (cyl),"=d" (head):"0" (block),"1" (0),"r" (hd_info[dev].head));sec++;nsect = CURRENT->nr_sectors;if (reset) {reset = 0;recalibrate = 1;reset_hd(CURRENT_DEV);return;}if (recalibrate) {recalibrate = 0;hd_out(dev,hd_info[CURRENT_DEV].sect,0,0,0,WIN_RESTORE,&recal_intr);return;} if (CURRENT->cmd == WRITE) {hd_out(dev,nsect,sec,head,cyl,WIN_WRITE,&write_intr);for(i=0 ; i<3000 && !(r=inb_p(HD_STATUS)&DRQ_STAT) ; i++)/* nothing */ ;if (!r) {bad_rw_intr();goto repeat;}port_write(HD_DATA,CURRENT->buffer,256);} else if (CURRENT->cmd == READ) {hd_out(dev,nsect,sec,head,cyl,WIN_READ,&read_intr);} elsepanic("unknown hd-command");
}
hd_out
static void hd_out(unsigned int drive,unsigned int nsect,unsigned int sect,unsigned int head,unsigned int cyl,unsigned int cmd,void (*intr_addr)(void))
{register int port asm("dx");if (drive>1 || head>15)panic("Trying to write bad sector");if (!controller_ready())panic("HD controller not ready");do_hd = intr_addr;outb_p(hd_info[drive].ctl,HD_CMD);port=HD_DATA;outb_p(hd_info[drive].wpcom>>2,++port);outb_p(nsect,++port);outb_p(sect,++port);outb_p(cyl,++port);outb_p(cyl>>8,++port);outb_p(0xA0|(drive<<4)|head,++port);outb(cmd,++port);
}
注意,此处的中断设置是在kernel/blk_drv/hd.c文件中hd_init函数中设置的:
void hd_init(void)
{blk_dev[MAJOR_NR].request_fn = DEVICE_REQUEST;// 设置硬盘的中断处理函数set_intr_gate(0x2E,&hd_interrupt);outb_p(inb_p(0x21)&0xfb,0x21);outb(inb_p(0xA1)&0xbf,0xA1);
}hd_interrupt函数在kernel/system_call.s中221行定义。
hd_interrupt
kernel/system_call.s
hd_interrupt:pushl %eaxpushl %ecxpushl %edxpush %dspush %espush %fsmovl $0x10,%eaxmov %ax,%dsmov %ax,%esmovl $0x17,%eaxmov %ax,%fsmovb $0x20,%aloutb %al,$0xA0 # EOI to interrupt controller #1jmp 1f # give port chance to breathe
1: jmp 1f
1: xorl %edx,%edxxchgl do_hd,%edxtestl %edx,%edxjne 1fmovl $unexpected_hd_interrupt,%edx
1: outb %al,$0x20call *%edx # 调用hd指向的函数pop %fspop %espop %dspopl %edxpopl %ecxpopl %eaxiretint 46(int 0x2E)硬盘中断处理程序,响应硬件中断请求IRQ14。当请求的硬盘操作完成或出错就会发出此中断信息。然后去变量do_hd中的函数指针放入edx,然后调用响应的函数(read_intr,write_intr,unexpected_hd_interrupt)。
read_intr
static void read_intr(void)
{if (win_result()) {bad_rw_intr();do_hd_request();return;}port_read(HD_DATA,CURRENT->buffer,256);CURRENT->errors = 0;CURRENT->buffer += 512;CURRENT->sector++;if (--CURRENT->nr_sectors) {do_hd = &read_intr;return;}end_request(1);do_hd_request();
}read_intr函数首先调用win_result函数,读取控制器的状态寄存器,以判断是否有错误发生。使用port_read函数从控制器缓冲区把一个扇区的数据复制到请求项指定的缓冲区中。然后根据当前请求项中指明的欲读扇区总数,判断是否已经读取了所有的数据。若还有数据要读,则退出,以等待下一个中断的到来。若数据已经全部获得,则调用end_request函数来处理当前请求项的结束事宜:唤醒等待当前请求项完成的进程、唤醒等待空闲请求项的进程(若有的话)、设置当前请求项所指缓冲区数据已更新标志、释放当前请求项(从块设备链表中删除该项)。最后继续调用do_hd_request函数,以继续处理硬盘设备的其他请求项。
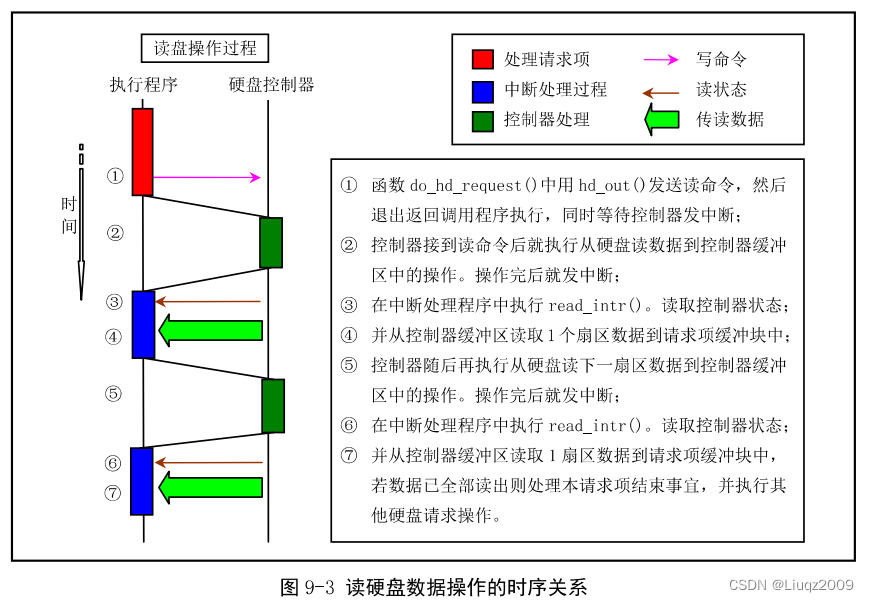
sys_setup之二
位于文件kernel/blk_drv/hd.c中
int sys_setup(void * BIOS)
{// ...rd_load(); // 尝试创建并加载虚拟盘mount_root(); // 安装根文件系统return (0);
}读取硬盘分区表后,现在开始尝试创建并加载虚拟盘(rd_load函数)(跟踪未启用)和安装根文件系统(mount_root函数)。
mount_root之一
fs/super.c
void mount_root(void)
{int i,free;struct super_block * p;struct m_inode * mi;if (32 != sizeof (struct d_inode))panic("bad i-node size");for(i=0;i<NR_FILE;i++)file_table[i].f_count=0;if (MAJOR(ROOT_DEV) == 2) {printk("Insert root floppy and press ENTER");wait_for_keypress();}for(p = &super_block[0] ; p < &super_block[NR_SUPER] ; p++) {p->s_dev = 0;p->s_lock = 0;p->s_wait = NULL;}if (!(p=read_super(ROOT_DEV)))panic("Unable to mount root");if (!(mi=iget(ROOT_DEV,ROOT_INO)))panic("Unable to read root i-node");mi->i_count += 3 ; /* NOTE! it is logically used 4 times, not 1 */p->s_isup = p->s_imount = mi;current->pwd = mi;current->root = mi;// 我们对根文件系统上的资源做统计工作。统计该设备上空闲块数和空闲i节点数。首先令i等于// 超级块中表明的设备逻辑块总数。然后根据逻辑块位图中相应比特位的占用情况统计出空闲块数。// 治理宏函数set_bit()只是在测试比特位,而非设置比特位。free=0;i=p->s_nzones;while (-- i >= 0)if (!set_bit(i&8191,p->s_zmap[i>>13]->b_data))free++;printk("%d/%d free blocks\n\r",free,p->s_nzones);free=0;i=p->s_ninodes+1;while (-- i >= 0)if (!set_bit(i&8191,p->s_imap[i>>13]->b_data))free++;printk("%d/%d free inodes\n\r",free,p->s_ninodes);
}mount_root函数执行流程:
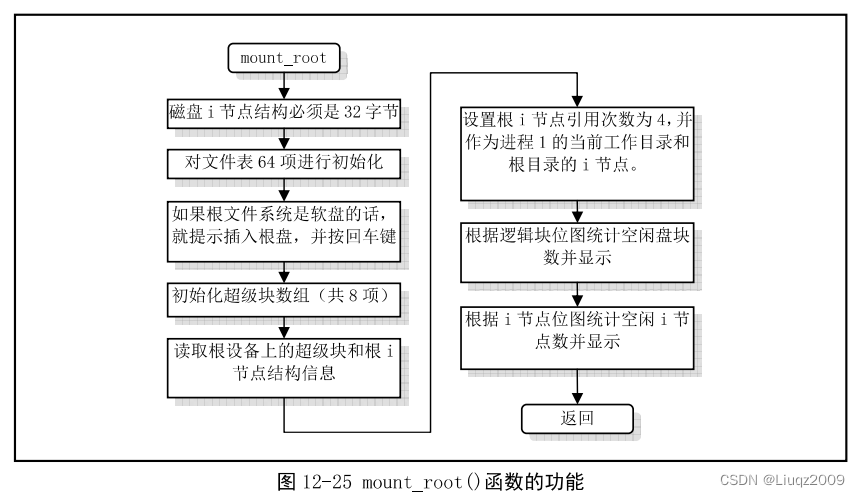
read_super函数

static struct super_block * read_super(int dev)
{struct super_block * s;struct buffer_head * bh;int i,block;if (!dev)return NULL;check_disk_change(dev);if ((s = get_super(dev)))return s;for (s = 0+super_block ;; s++) {if (s >= NR_SUPER+super_block)return NULL;if (!s->s_dev)break;}s->s_dev = dev;s->s_isup = NULL;s->s_imount = NULL;s->s_time = 0;s->s_rd_only = 0;s->s_dirt = 0;// 锁定该超级块,并从设备上读取超级块信息到bh指向的缓冲块中。超级块位于块设备// 的第2个逻辑块(1号block)中,(第1个是引导盘块)。lock_super(s);if (!(bh = bread(dev,1))) {s->s_dev=0;free_super(s);return NULL;}*((struct d_super_block *) s) =*((struct d_super_block *) bh->b_data);brelse(bh);if (s->s_magic != SUPER_MAGIC) {s->s_dev = 0;free_super(s);return NULL;}// 下面开始读取设备上i节点位图和逻辑块位图数据。首先初始化内存超级块结构中位图空间。// 然后从设备上读取i节点位图和逻辑块位图信息,并存放在超级块对应字段中。i节点位图// 保存在设备上2号块开始的逻辑块中,共占用s_imap_blocks(3)个块。逻辑块位图在i节点// 位图所在块的后续块中,共占用s_zmap_blocks(8)个块。for (i=0;i<I_MAP_SLOTS;i++)s->s_imap[i] = NULL;for (i=0;i<Z_MAP_SLOTS;i++)s->s_zmap[i] = NULL;block=2;// 读取设备中i节点位图for (i=0 ; i < s->s_imap_blocks ; i++)if ((s->s_imap[i]=bread(dev,block)))block++;elsebreak;// 读取设备中逻辑块位图for (i=0 ; i < s->s_zmap_blocks ; i++)if ((s->s_zmap[i]=bread(dev,block)))block++;elsebreak;if (block != 2+s->s_imap_blocks+s->s_zmap_blocks) {for(i=0;i<I_MAP_SLOTS;i++)brelse(s->s_imap[i]);for(i=0;i<Z_MAP_SLOTS;i++)brelse(s->s_zmap[i]);s->s_dev=0;free_super(s);return NULL;}// 0号i节点不能用的,所以这里将位图中第1块的最低比特位设置为1,以防止文件系统分配0号i节点。// 同样的道理,也将逻辑块位图的最低位设置为1.s->s_imap[0]->b_data[0] |= 1;s->s_zmap[0]->b_data[0] |= 1;free_super(s);return s;
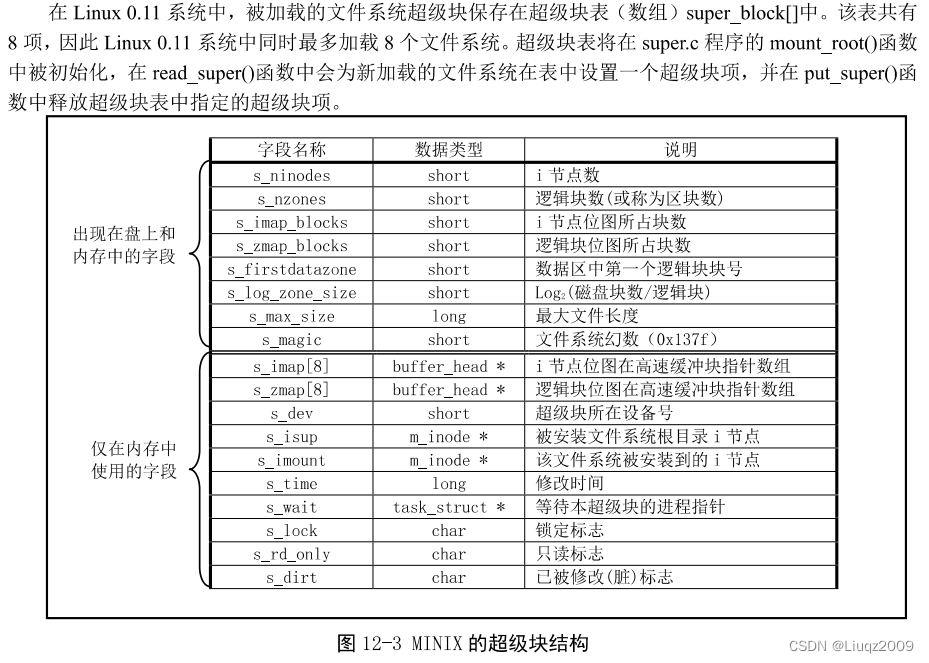
}super_block结构体
内存中磁盘超级块结构
struct super_block {unsigned short s_ninodes; // 节点数unsigned short s_nzones; // 逻辑块数unsigned short s_imap_blocks; // i 节点位图所占用的数据块数unsigned short s_zmap_blocks; // 逻辑块位图所占用的数据块数unsigned short s_firstdatazone; // 第一个数据逻辑块号unsigned short s_log_zone_size; // log(数据块数/逻辑块)(以2为底)unsigned long s_max_size; // 文件最大长度unsigned short s_magic; // 文件系统魔数
/* These are only in memory */struct buffer_head * s_imap[8]; // i 节点位图缓冲块指针数组(占用8块,可表示64M)struct buffer_head * s_zmap[8]; // 逻辑块位图缓冲块指针数组(占用8块)unsigned short s_dev; // 超级块所在的设备号struct m_inode * s_isup; // 被安装的文件系统根目录的 i 节点(isup-super i)struct m_inode * s_imount; // 被安装到的 i 节点unsigned long s_time; // 修改时间struct task_struct * s_wait; // 等待该超级块的进程unsigned char s_lock; // 被锁定标志unsigned char s_rd_only; // 只读标志unsigned char s_dirt; // 已修改(脏)标志
};// 磁盘上超级块结构,与上面super_block的前面部分相同
struct d_super_block {unsigned short s_ninodes;unsigned short s_nzones;unsigned short s_imap_blocks;unsigned short s_zmap_blocks;unsigned short s_firstdatazone;unsigned short s_log_zone_size;unsigned long s_max_size;unsigned short s_magic;
};

mount_root之二 iget 函数


iget函数执行流程: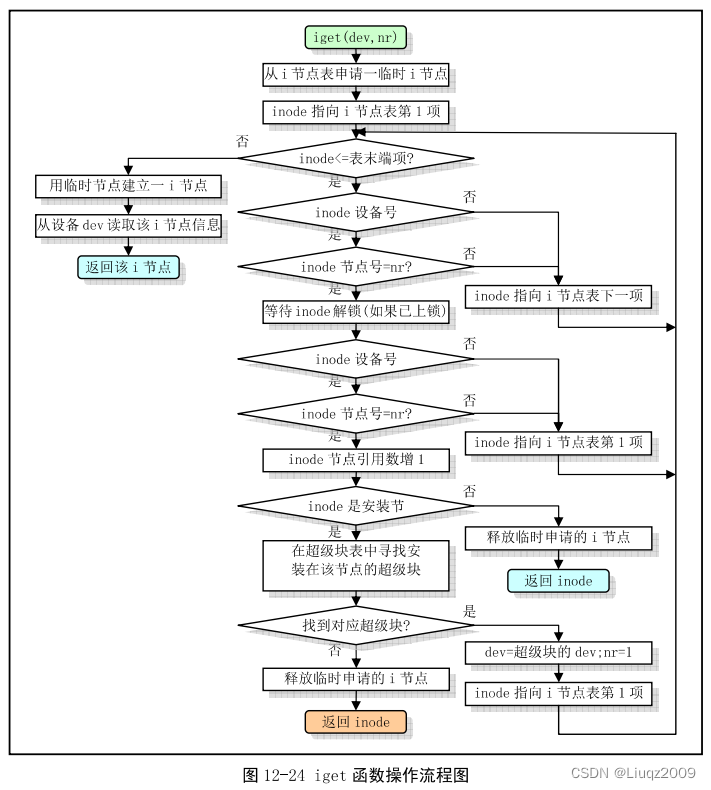
代码:
// 从设备上读取指定节点号的i节点到内存i节点表中,并返回该i节点指针
// 首先在位于高速缓冲区中的i节点表中搜寻,若找到指定节点号的i节点则在经过一些判断
// 处理后返回该i节点指针。否则从设备dev上读取指定i节点号的i节点信息放入i节点表中,
// 并返回该i节点指针
struct m_inode * iget(int dev,int nr)
{struct m_inode * inode, * empty;if (!dev)panic("iget with dev==0");empty = get_empty_inode();inode = inode_table;while (inode < NR_INODE+inode_table) {if (inode->i_dev != dev || inode->i_num != nr) {inode++;continue;}wait_on_inode(inode);if (inode->i_dev != dev || inode->i_num != nr) {inode = inode_table;continue;}inode->i_count++;if (inode->i_mount) {int i;for (i = 0 ; i<NR_SUPER ; i++)if (super_block[i].s_imount==inode)break;if (i >= NR_SUPER) {printk("Mounted inode hasn't got sb\n");if (empty)iput(empty);return inode;}iput(inode);dev = super_block[i].s_dev;nr = ROOT_INO;inode = inode_table;continue;}if (empty)iput(empty);return inode;}if (!empty)return (NULL);inode=empty;inode->i_dev = dev;inode->i_num = nr;read_inode(inode);return inode;
}m_inode
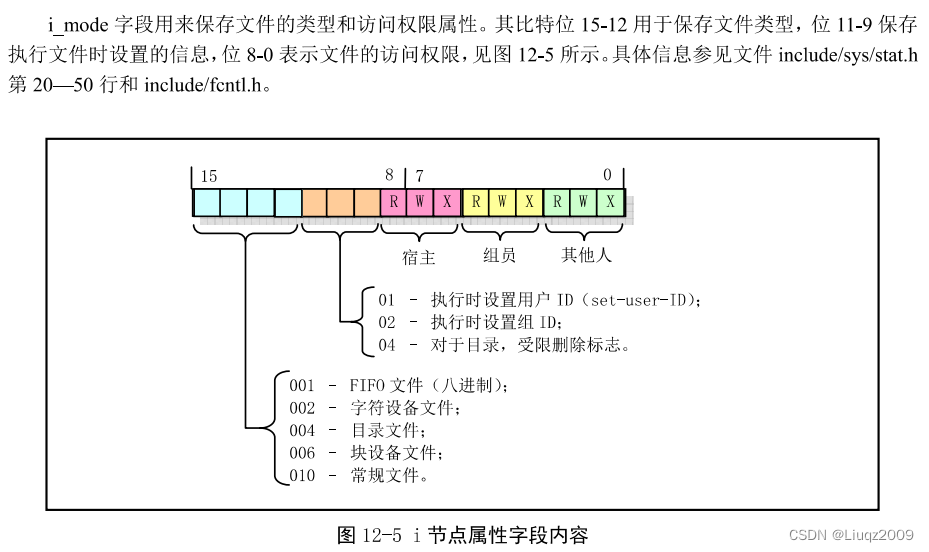
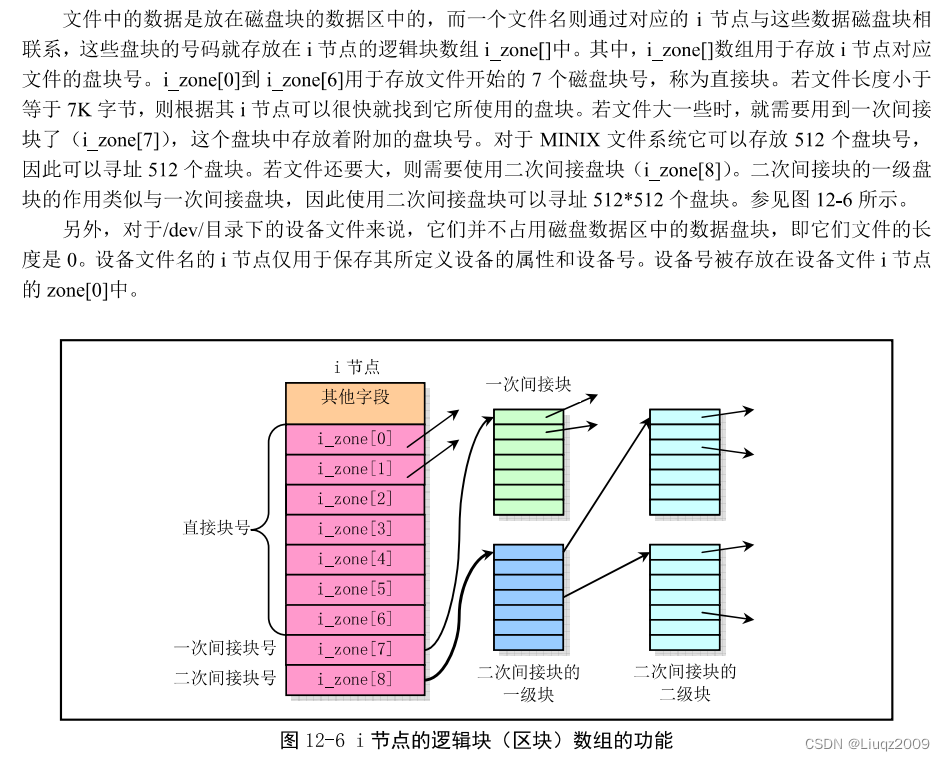
struct d_inode {unsigned short i_mode;unsigned short i_uid;unsigned long i_size;unsigned long i_time;unsigned char i_gid;unsigned char i_nlinks;unsigned short i_zone[9];
};struct m_inode {unsigned short i_mode; // 文件类型和属性(rwx位)unsigned short i_uid; // 用户id(文件拥有者标识符)unsigned long i_size; // 文件大小(字节数)unsigned long i_mtime; // 修改时间(自1970.1.1:0算起,单位秒)unsigned char i_gid; // 组 id(文件拥有者所在的组)unsigned char i_nlinks; // 文件目录项链接数unsigned short i_zone[9]; // 直接(0-6)、间接(7)或双重间接(8)逻辑块号
/* these are in memory also */struct task_struct * i_wait; // 等待该i节点的进程unsigned long i_atime; // 最后访问时间unsigned long i_ctime; // i节点自身修改时间unsigned short i_dev; // i节点所在的设备号unsigned short i_num; // i节点号unsigned short i_count; // i节点被使用的次数,0表示该i节点空闲unsigned char i_lock; // 锁定标志unsigned char i_dirt; // 已修改(脏)标志unsigned char i_pipe; // 管道标志unsigned char i_mount; // 安装标志unsigned char i_seek; // 搜寻标志(lseek时)unsigned char i_update; // 更新标志
};read_inode函数
fs/inode.c
#define BLOCK_SIZE 1024
#define INODES_PER_BLOCK ((BLOCK_SIZE)/(sizeof (struct d_inode)))static void read_inode(struct m_inode * inode)
{struct super_block * sb;struct buffer_head * bh;int block;lock_inode(inode);if (!(sb=get_super(inode->i_dev)))panic("trying to read inode without dev");// 第0个引导块,第1个超级块,s_imap_blocks i节点块数, s_zmap_blocks 逻辑块块数// 节点就位于这些块之后,每块大小为1K,磁盘上i节点占用的空间为sizeof (struct d_inode)(8*8字节)// 所以可知i节点依次放在磁盘上,每块可放16个i节点block = 2 + sb->s_imap_blocks + sb->s_zmap_blocks +(inode->i_num-1)/INODES_PER_BLOCK;if (!(bh=bread(inode->i_dev,block)))panic("unable to read i-node block");*(struct d_inode *)inode =((struct d_inode *)bh->b_data)[(inode->i_num-1)%INODES_PER_BLOCK];brelse(bh);unlock_inode(inode);
}

说明
因此,从上分析可知,通过超级块信息,找到根文件系统i节点存放在磁盘上的位置,读入根文件系统i节点信息,然后通过i节点中的i_zone信息就可以找到根文件下的目录和文件。
6、文件打开open
文件系统根目录下的所有文件名信息则保持在指定i节点(即1号节点)的数据块中。每个目录项只包括一个长度为14字节的文件名字字符串和该文件名对应的2字节的i节点号。有关文件的其它信息则被保存在该i节点号指定的i节点结构中,该结构中主要包括文件访问属性、宿主、长度、访问保存时间以及所在磁盘块等信息。
#define NAME_LEN 14 // 名字长度值
#define ROOT_INO 1 // 根i节点struct dir_entry {unsigned short inode; // i 节点号(0.11版本可理解为存储序号)char name[NAME_LEN]; // 文件名
};在打开一个文件时,文件系统会根据给定的文件名找到其 i 节点号,从而找到文件所在的磁盘块位置。例如对于要查找文件名 /usr/bin/vi 的 i 节点号,文件系统首先会从具有固定 i 节点号(1)的根目录开始操作,即从 i 节点号1的数据块中查找到名称为usr的目录项,从而得到文件/usr的i节点号。根据该i节点号文件系统可以顺利地取得目录/usr,并在其中可以查找到文件名bin的目录项。这样也就知道了/usr/bin的i节点号,因而我们可以知道目录/usr/bin的目录所在位置,并在该目录中查找到vi文件的目录项。最终我们获得了文件路径名/usr/bin/vi的i节点号,从而可以从磁盘上得到该i节点号的i节点结构信息。
init/main.c
void init(void) {// ... (void)open("/dev/tty0", O_RDWR, 0);(void)dup(0);(void)dup(0);// ...
}main.c中init函数有open("/dev/tty0", O_RDWR, 0),现在我们就分析下其调用过程:
open函数
lib/open.c
int open(const char * filename, int flag, ...)
{register int res;va_list arg;va_start(arg,flag);__asm__("int $0x80":"=a" (res):"0" (__NR_open),"b" (filename),"c" (flag),"d" (va_arg(arg,int)));if (res>=0)return res;errno = -res;return -1;
}从上面可知,其通过0x80中断,执行系统调用。
中断响应:kernel/system_call.s文件中system_call函数进行响应,最终调用sys_open函数(具体可参考fork章节)。
sys_open函数
fs/open.c
int sys_open(const char * filename,int flag,int mode)
{struct m_inode * inode;struct file * f;int i,fd;mode &= 0777 & ~current->umask;for(fd=0 ; fd<NR_OPEN ; fd++)if (!current->filp[fd])break;if (fd>=NR_OPEN)return -EINVAL;current->close_on_exec &= ~(1<<fd);f=0+file_table;for (i=0 ; i<NR_FILE ; i++,f++)if (!f->f_count) break;if (i>=NR_FILE)return -EINVAL;(current->filp[fd]=f)->f_count++;if ((i=open_namei(filename,flag,mode,&inode))<0) {current->filp[fd]=NULL;f->f_count=0;return i;}
/* ttys are somewhat special (ttyxx major==4, tty major==5) */if (S_ISCHR(inode->i_mode)) {if (MAJOR(inode->i_zone[0])==4) {if (current->leader && current->tty<0) {current->tty = MINOR(inode->i_zone[0]);tty_table[current->tty].pgrp = current->pgrp;}} else if (MAJOR(inode->i_zone[0])==5)if (current->tty<0) {iput(inode);current->filp[fd]=NULL;f->f_count=0;return -EPERM;}}
/* Likewise with block-devices: check for floppy_change */if (S_ISBLK(inode->i_mode))check_disk_change(inode->i_zone[0]);f->f_mode = inode->i_mode;f->f_flags = flag;f->f_count = 1;f->f_inode = inode;f->f_pos = 0;return (fd);
}open_namei函数
fs/namei.c
// 文件打开函数
// pathname是文件名,flag是打开文件标志,可为:O_RDONLY(只读)、O_WRONLY(只写)或
// O_RDWR(读写),以及O_CREAT(创建)、O_EXCL(被创建文件必须不存在)、O_APPEND(在文件尾添加数据)
// 等其他一些标志的组合。
// 成功返回0,否则返回出错码,res_node返回对应文件路径名的i节点指针
int open_namei(const char * pathname, int flag, int mode,struct m_inode ** res_inode)
{const char * basename;int inr,dev,namelen;struct m_inode * dir, *inode;struct buffer_head * bh;struct dir_entry * de;if ((flag & O_TRUNC) && !(flag & O_ACCMODE))flag |= O_WRONLY;mode &= 0777 & ~current->umask;mode |= I_REGULAR;if (!(dir = dir_namei(pathname,&namelen,&basename)))return -ENOENT;if (!namelen) { /* special case: '/usr/' etc */if (!(flag & (O_ACCMODE|O_CREAT|O_TRUNC))) {*res_inode=dir;return 0;}iput(dir);return -EISDIR;}bh = find_entry(&dir,basename,namelen,&de);if (!bh) {if (!(flag & O_CREAT)) {iput(dir);return -ENOENT;}if (!permission(dir,MAY_WRITE)) {iput(dir);return -EACCES;}inode = new_inode(dir->i_dev);if (!inode) {iput(dir);return -ENOSPC;}inode->i_uid = current->euid;inode->i_mode = mode;inode->i_dirt = 1;bh = add_entry(dir,basename,namelen,&de);if (!bh) {inode->i_nlinks--;iput(inode);iput(dir);return -ENOSPC;}de->inode = inode->i_num;bh->b_dirt = 1;brelse(bh);iput(dir);*res_inode = inode;return 0;}inr = de->inode;dev = dir->i_dev;brelse(bh);iput(dir);if (flag & O_EXCL)return -EEXIST;if (!(inode=iget(dev,inr)))return -EACCES;if ((S_ISDIR(inode->i_mode) && (flag & O_ACCMODE)) ||!permission(inode,ACC_MODE(flag))) {iput(inode);return -EPERM;}inode->i_atime = CURRENT_TIME;if (flag & O_TRUNC)truncate(inode);*res_inode = inode;return 0;
}dir_namei函数
返回指定目录名的 i 节点指针,以及在最顶层目录的名称。
static struct m_inode * dir_namei(const char * pathname,int * namelen, const char ** name)
{char c;const char * basename;struct m_inode * dir;if (!(dir = get_dir(pathname)))return NULL;basename = pathname;while ((c=get_fs_byte(pathname++)))if (c=='/')basename=pathname;*namelen = pathname-basename-1;*name = basename;return dir;
}get_dir函数
根据给出的路径名进行搜索,直到达到最顶端的目录。
static struct m_inode * get_dir(const char * pathname)
{char c;const char * thisname;struct m_inode * inode;struct buffer_head * bh;int namelen,inr,idev;struct dir_entry * de;// 搜索操作会从当前进程任务结构中设置的根(或伪根)i 节点或当前工作目录 i 节点开始。// 因此首先需要判断进程的根 i 节点指针和当前工作目录 i 节点指针是否有效。如果当前进程// 没有设定根 i 节点,或者该进程根 i 节点指向是一个空闲i节点(引用为0),则系统出错停机。// 如果进程的当前工作目录i节点指针为空,或者当前工作目录 i 节点指向是一个空闲i节点,// 这也是系统有问题,停机。if (!current->root || !current->root->i_count)panic("No root inode");if (!current->pwd || !current->pwd->i_count)panic("No cwd inode");// 如果用户指定的路径名的第1个字符是'/',则说明路径是绝对路径名。则从根i节点开始操作。// 否则表示给定的是相对路径名。应从进程的当前工作目录开始操作。则取进程当前工作目录的// i节点。if ((c=get_fs_byte(pathname))=='/') {inode = current->root;pathname++;} else if (c)inode = current->pwd;elsereturn NULL; /* empty name is bad */// 然后针对路径名中的各个目录名部分和文件名进行循环处理。首先把得到的i节点引用计数增1,// 表示我们正在使用。在循环处理过程中,我们先要对当前正在处理的目录名部分(或文件名)的i// 节点进行有效性判断,并且把变量thisname指向当前正在处理的目录名部分(或文件名)。// 如果该i节点不是目录类型的i节点,或者没有可进入该目录的访问许可,则放回该i节点,并返回// NULL退出。当然,刚进入循环时,当前的i节点就是进程根i节点或者是当前工作目录的i节点。// 注意!如果路径名中最后一个名称也是一个目录名,但其后面没有加上'/'字符,则函数不会// 返回该最后目录的i节点!例如:对于路径名/usr/src/linux,该函数将只返回src目录名的i节点。inode->i_count++;while (1) {thisname = pathname;if (!S_ISDIR(inode->i_mode) || !permission(inode,MAY_EXEC)) {iput(inode);return NULL;}// 每次循环我们处理路径名中一个目录名(或文件名)部分。因此在每次循环中我们都要从路径// 名字符串中分离出一个目录名(或文件名)。方法是从当前路径名指针pathname开始处搜索// 检测字符,直到字符是一个结尾符(NULL)或者是一个'/'字符。此时变量namelen正好是当前// 处理目录名部分的长度,而变量thisname正指向该目录名部分的开始处。此时如果字符是结尾符// NULL,则表明已经搜索到路径名末尾,并已到达最后指定目录名或文件名,则返回该i节点指针退出for(namelen=0;(c=get_fs_byte(pathname++))&&(c!='/');namelen++)/* nothing */ ;if (!c)return inode;// 在得到当前目录名部分(或文件名)后,我们调用查找目录项函数find_entry在当前处理的目录中// 寻找指定名称的目录项。如果没找到,则返回NULL退出。否则在找到的目录项中取出其i节点号inr// 和设备号idev,然后取节点号inr的i节点inode,并以该目录项为当前目录继续循环处理路径名中的// 下一目录名部分(或文件名)if (!(bh = find_entry(&inode,thisname,namelen,&de))) {iput(inode);return NULL;}inr = de->inode;idev = inode->i_dev;brelse(bh);iput(inode);if (!(inode = iget(idev,inr)))return NULL;}
}find_entry
/* 查找指定目录和文件名的目录项。* dir 指定目录i节点的指针,name 文件名,namelen文件名长度。* 返回:成功则返回函数告诉缓冲区指针,并在*res_dir处返回的目录项结构指针。失败则返回空指针。
*/
static struct buffer_head * find_entry(struct m_inode ** dir,const char * name, int namelen, struct dir_entry ** res_dir)
{//...
}execve函数
当一个程序使用fork函数创建了一个子进程时,通常会在子进程中调用exec()簇函数之一以加载执行另一个新程序。此时子进程的代码、数据段(包括堆、栈内容)将完全被新程序的替换掉,并在子进程中开始执行新程序。execve函数的主要功能为:

在execve()执行过程中,系统会清掉fork()复制的原程序的页目录和页表项,并释放对应页面。系统仅为新加载的程序代码重新设置进程数据结构中的信息,申请和映射了命令行参数和环境参数块所占的内存页面,以及设置了执行代码执行点。此时内核并不从执行文件所在块设备上加载程序的代码和数据。当该过程返回时即开始执行新的程序,但一开始执行肯定会引起缺页异常中断发生。因为代码和数据还未被从块设备上读入内存。此时缺页异常处理程序会根据引起异常的线性地址在主内存区为新程序申请内存页面(内存帧),并从块设备上读入引起异常的指定页面。同时还为该线性地址设置对应的页目录项和页表项。这种加载执行文件的方法称为需求加载(Load on demand)。
另外,由于新程序是在子进程中执行,所以该子进程就是新程序的进程。新程序的进程ID就是该子进程的进程ID。同样,该子进程的属性也就成为了新程序进程的属性。而对于已打开文件的处理则与每个文件描述符的执行时关闭(close on exec)标志有关。进程中每个打开的文件描述符都有一个执行时关闭标志。在进程控制结构中是使用一个无符号长整数close_on_exec来表示的。它的每个比特位表示对应每个文件描述符的该标志。若一个文件描述符在close_on_exec中的对应比特位被设置,那么执行execve()时该描述符将被关闭,否则该描述符将始终处于打开状态。除非我们使用了文件控制函数fcntl特别地设置了该标志,否则内核默认操作在execve执行后仍然保持描述符的打开状态。
execve函数有大量对命令行参数和环境空间的处理操作,参数和环境空间共可有MAX_ARG_PAGES个页面,总长度可达128KB字节。在该空间中存放数据的方式类似于堆栈操作,即从假设的128KB空间末端处逆向开始存放参数或环境变量字符串的。在初始时,程序定义了一个指向该空间末端(128KB-4字节)处空间内偏移值p,该偏移值随着存放数据的增多后退,下图中可以看出,p明确地指出了当前参数环境空间还剩余多少可用空间。copy_string函数用于从用户内存空间拷贝命令行参数和环境字符串到内核空闲页面中。
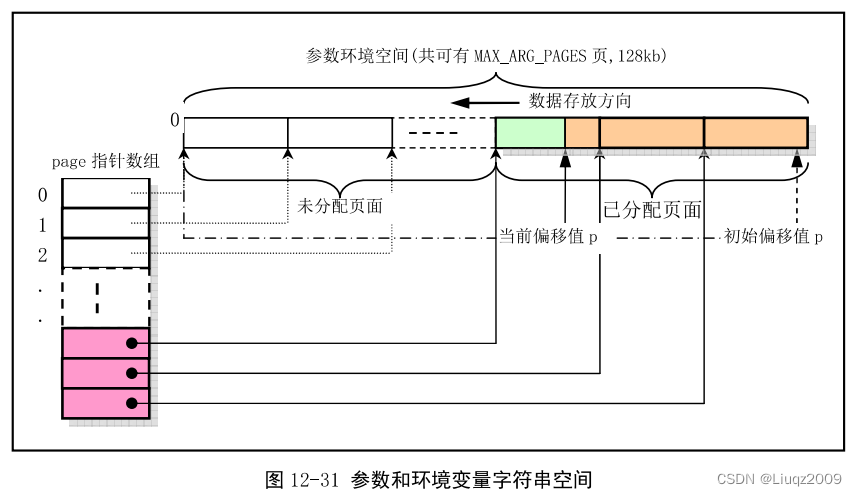
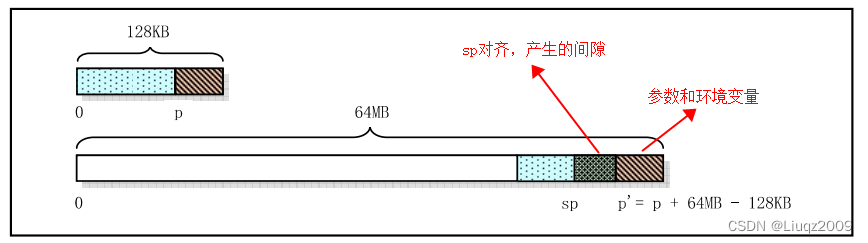
在执行完copy_string函数之后,再通过执行第333行语句,p将被调整为从进程逻辑地址空间开始处算起的参数和环境变量起始处指针,见下图中所示的 。方法是把一个进程占用的最大逻辑空间长度64M减去参数和环境变量占用的长度(128KB - p)。
的左边部分还将使用create_tables函数来存放参数和环境变量的一个指针表,并且
将再次向左调整为指向指针表的起始位置处。再把所得指针进行页面对齐,最终得到初始堆栈指针sp。
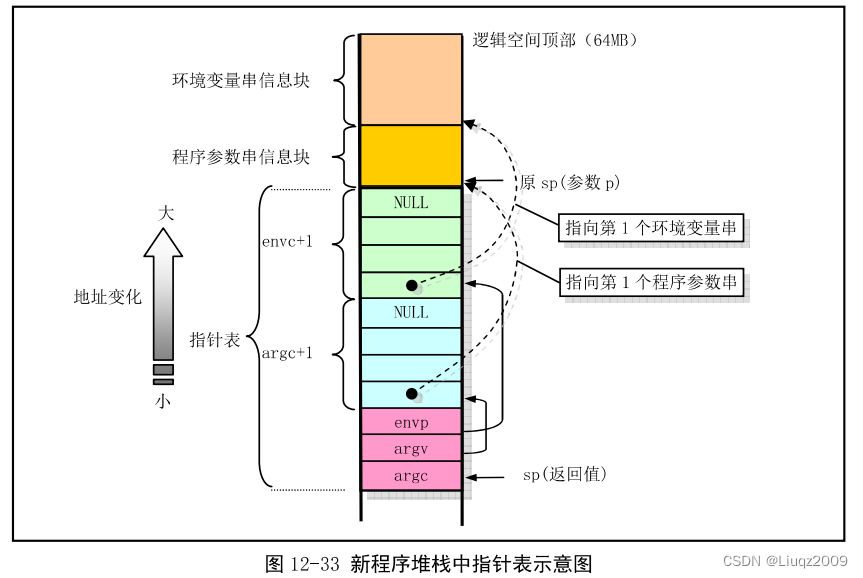
create_tables函数用于根据给定的当前堆栈指针值 p 以及参数变量个数值 argc 和环境变量个数 envc,在新的程序堆栈中创建环境和参数变量指针表,并返回此时的堆栈指针值,再把该指针进行页面对齐处理,最终得到初始堆栈指针 sp。创建完毕后堆栈指针表的形式如下:
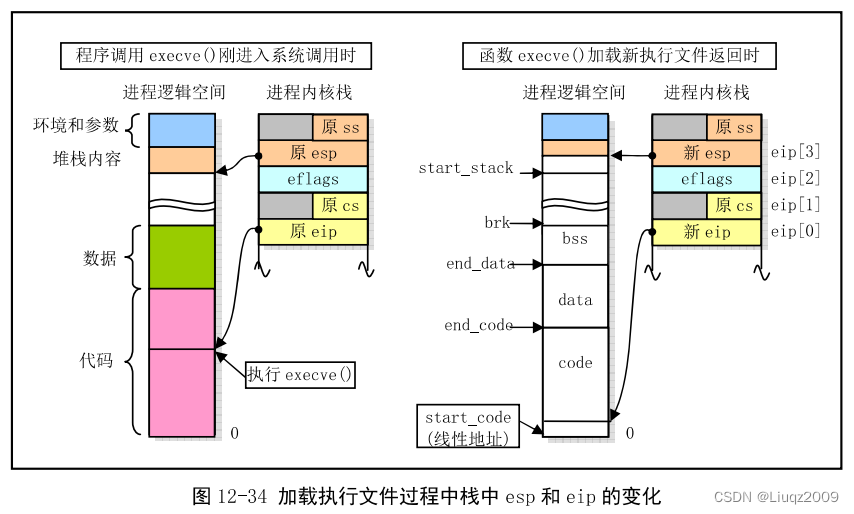
函数 do_execve() 最后返回时会把原调用系统中断程序在堆栈上的代码指针 eip 替换为指向新执行程序的入口点,并将栈指针替换为新执行文件的栈指针 esp 。此后这次系统调用的返回指令最终会弹出这些栈中数据,并使得CPU去执行新执行文件。这个过程如下图所示。图中左半部分是进程逻辑64MB的空间还包含原执行程序时的情况;右半部分是释放了原执行程序代码和数据并且更新了堆栈和代码指针时的情况。其中阴影(彩色)部分中包含代码或数据信息。进程任务结构中的start_code是CPU线性空间中地址,其余几个变量值均是进程逻辑空间中的地址。
main.c中init函数调用了execve函数。
void init(void) {// ...execve("/bin/sh", argv_rc, envp_rc);// ...
}execve也是一个系统调用,其响应函数定义在kernel/system_call.s中200行处为sys_execve。
.align 2
sys_execve:lea EIP(%esp),%eaxpushl %eaxcall do_execveaddl $4,%espretdo_execve函数
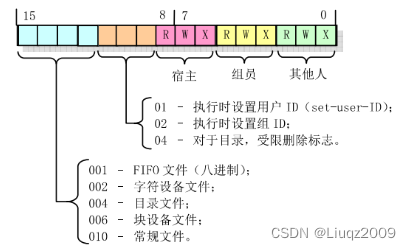
fs/exec.c
int do_execve(unsigned long * eip,long tmp,char * filename,char ** argv, char ** envp)
{struct m_inode * inode;struct buffer_head * bh;struct exec ex;unsigned long page[MAX_ARG_PAGES];int i,argc,envc;int e_uid, e_gid;int retval;int sh_bang = 0;unsigned long p=PAGE_SIZE*MAX_ARG_PAGES-4;if ((0xffff & eip[1]) != 0x000f)panic("execve called from supervisor mode");for (i=0 ; i<MAX_ARG_PAGES ; i++) /* clear page-table */page[i]=0;if (!(inode=namei(filename))) /* get executables inode */return -ENOENT;argc = count(argv);envc = count(envp);restart_interp:if (!S_ISREG(inode->i_mode)) { /* must be regular file */retval = -EACCES;goto exec_error2;}// 下面检查当前进程是否有权运行指定的执行文件。即根据执行文件i节点中的属性,看看本// 进程是否有权执行它。在把执行文件i节点的属性字段值取到i中后,我们首先查看属性中// 是否设置了“设置-用户-ID”(set-user-id)标志和“设置-组-ID”(set-group-id)标志。// 这两个标志主要是让一般用户能够执行特权用户(如超级用户root)的程序,例如改变密码的// 程序 passwd 等。如果set-user-id标志置位,则后面执行进程的有效用户ID(euid)就设置// 成执行文件的用户ID,否则设置成当前进程的 euid。如果执行文件set-group-id被置位的话,// 则执行进程的有效组ID(egid)就设置为执行文件的组ID。否则设置成当前进程的egid。i = inode->i_mode;e_uid = (i & S_ISUID) ? inode->i_uid : current->euid;e_gid = (i & S_ISGID) ? inode->i_gid : current->egid;
// 现在根据进程的euid和egid和执行文件的访问属性进行比较。如果执行文件属于运行进程的用户
// ,则把文件属性值i右移6位,此时其最低3位是文件宿主的访问权限标志。否则的话如果执行文件
// 与当前进程的用户属于同组,则使属性值最低3位是执行文件组用户的访问权限标志。否则此时
// 属性字最低3位就是其他用户访问该执行文件的权限。
// 然后我们根据属性字i的最低3比特值来判断当前进程是否有权限运行这个执行文件。如果选出的
// 相应用户没有运行该文件的权利(位0是执行权限),并且其他用户也没有任何权限或者当前用户
// 不是超级用户,则表明当前进程没有权利运行这个执行文件。于是置不可执行出错码,并跳转到
// exec_error2处去做退出处理if (current->euid == inode->i_uid)i >>= 6;else if (current->egid == inode->i_gid)i >>= 3;if (!(i & 1) &&!((inode->i_mode & 0111) && suser())) {retval = -ENOEXEC;goto exec_error2;}
// 程序执行到这里,说明当前进程有运行指定执行文件的权限。因此从这里开始我们需要取出
// 执行文件头部数据并根据其中的信息来分析设置运行环境,或者运行另一个shell程序来执行
// 脚本程序。首先读取执行文件第1块数据到高速缓冲块中。并复制缓冲块数据到ex中。如果
// 执行文件开始的两个字节是字符“#!”,则说明执行文件是一个脚本文本文件。如果想运行
// 脚本文件,我们就需要执行脚本文件的解释程序(例如shell程序)。通常脚本文件的第一行
// 文本为“#!/bin/bash”。它指明了运行脚本文件需要的解释程序。运行方法是从脚本文件
// 第1行(带字符“#!”)中取出其中的解释程序名及后面的参数(若有的话),然后将这些参数
// 和脚本文件名放进执行文件(此时是解释程序)的命令行参数空间中。在这之前我们当然需要
// 先把函数指定的原有命令行参数和环境字符串放到 128KB 空间中,而这里建立起来的命令行
// 参数则放到他们前面位置处(因为是逆向放置)。最后让内核执行脚本文件的解释程序。
// 下面就是在设置好解释程序的脚本文件名等参数后,取出解释程序的i节点并跳转到204行去
// 执行解释程序。由于我们需要跳转到执行过的代码204行去,因此在下面确认并处理了脚本文件
// 之后需要设置一个禁止再次执行下面的脚本处理代码标志sh_bang。在后面的代码中该标志
// 也用来表示我们已经设置好执行文件的命令行参数,不要重复设置。if (!(bh = bread(inode->i_dev,inode->i_zone[0]))) {retval = -EACCES;goto exec_error2;}ex = *((struct exec *) bh->b_data); /* read exec-header */if ((bh->b_data[0] == '#') && (bh->b_data[1] == '!') && (!sh_bang)) {/** This section does the #! interpretation.* Sorta complicated, but hopefully it will work. -TYT*/char buf[1023], *cp, *interp, *i_name, *i_arg;unsigned long old_fs;// 从这里开始,我们从脚本文件中提取解释程序名及其参数,并把解释程序名、解释程序的参数
// 和脚本文件名组合放入环境参数块中。首先复制脚本文件头 1 行字符' #!' 后面的字符串到 buf
// 中,其中含有脚本解释程序名(例如/bin/sh),也可能还包含解释程序的几个参数。然后对
// buf 中的内容进行处理。删除开始的空格、制表符。strncpy(buf, bh->b_data+2, 1022);brelse(bh);iput(inode);buf[1022] = '\0';if ((cp = strchr(buf, '\n'))) {*cp = '\0';for (cp = buf; (*cp == ' ') || (*cp == '\t'); cp++);}if (!cp || *cp == '\0') {retval = -ENOEXEC; /* No interpreter name found */goto exec_error1;}
// 此时我们得到了开头是脚本解释程序名的一行内容(字符串)。下面分析该行。首先取第一
// 字符串,它应该是解释程序名,此时 i_name 指向该名称。若解释程序名后还有字符,则它们应
// 该是解释程序的参数串,于是令 i_arg 指向该串。interp = i_name = cp;i_arg = 0;for ( ; *cp && (*cp != ' ') && (*cp != '\t'); cp++) {if (*cp == '/')i_name = cp+1;}if (*cp) {*cp++ = '\0';i_arg = cp;}/** OK, we've parsed out the interpreter name and* (optional) argument.*/
// 现在我们要把上面解析出来的解释程序名 i_name 及其参数 i_arg 和脚本文件名作为解释程
// 序的参数放进环境和参数块中。不过首先我们需要把函数提供的原来一些参数和环境字符串
// 先放进去,然后再放这里解析出来的。例如对于命令行参数来说,如果原来的参数是"-arg1
// -arg2"、解释程序名是"bash"、其参数是"-iarg1 -iarg2"、脚本文件名(即原来的执行文
// 件名)是"example.sh",那么在放入这里的参数之后,新的命令行类似于这样:
// "bash -iargl -iarg2 example.sh -argl -arg2"
// 这里我们把 sh_bang 标志置上,然后把函数参数提供的原有参数和环境字符串放入到空间中。
// 环境字符串和参数个数分别是 envc 和 argc-1 个。少复制的一个原有参数是原来的执行文件。
// 名,即这里的脚本文件名。[[?? 可以看出,实际上我们不需要去另行处理脚本文件名,即这
// 里完全可以复制 argc 个参数,包括原来执行文件名(即现在的脚本文件名)。因为它位于同
// 一个位置上 ]]。注意!这里指针 p 随着复制信息增加而逐渐向小地址方向移动,因此这两个
// 复制串函数执行完后,环境参数串信息块位于程序命令行参数串信息块的上方,并且 p 指向
// 程序的第 1 个参数串。copy_strings()最后一个参数(0)指明参数字符串在用户空间。if (sh_bang++ == 0) {p = copy_strings(envc, envp, page, p, 0);p = copy_strings(--argc, argv+1, page, p, 0);}/** Splice in (1) the interpreter's name for argv[0]* (2) (optional) argument to interpreter* (3) filename of shell script** This is done in reverse order, because of how the* user environment and arguments are stored.*/
// 接着我们逆向复制脚本文件名、解释程序的参数和解释程序文件名到参数和环境空间中。
// 若出错,则置出错码,跳转到 exec_error1。另外,由于本函数参数提供的脚本文件名
// filename 在用户空间,而这里赋予 copy_strings()的脚本文件名指针在内核空间,因此。
// 这个复制字符串函数的最后一个参数(字符串来源标志)需要被设置成 1。若字符串在
// 内核空间,则 copy_strings()的最后一个参数要设置成 2,如下面的第 276、279 行。p = copy_strings(1, &filename, page, p, 1);argc++;if (i_arg) {p = copy_strings(1, &i_arg, page, p, 2);argc++;}p = copy_strings(1, &i_name, page, p, 2);argc++;if (!p) {retval = -ENOMEM;goto exec_error1;}/** OK, now restart the process with the interpreter's inode.*/
// 最后我们取得解释程序的 i 节点指针,然后跳转到 204 行去执行解释程序。为了获得解释程
// 序的 i 节点,我们需要使用 namei() 函数,但是该函数所使用的参数(文件名)是从用户数
// 据空间得到的,即从段寄存器 fs 所指空间中取得。因此在调用 namei()函数之前我们需要
// 先临时让 fs 指向内核数据空间,以让函数能从内核空间得到解释程序名,并在 namei()
// 返回后恢复 fs 的默认设置。因此这里我们先临时保存原 fs 段寄存器(原指向用户数据段)
// 的值,将其设置成指向内核数据段,然后取解释程序的 i 节点。之后再恢复 fs 的原值。并
// 跳转到 restart_interp(204 行)处重新处理新的执行文件 -- 脚本文件的解释程序。old_fs = get_fs();set_fs(get_ds());if (!(inode=namei(interp))) { /* get executables inode */set_fs(old_fs);retval = -ENOENT;goto exec_error1;}set_fs(old_fs);goto restart_interp;}
// 此时缓冲块中的执行文件头结构数据已经复制到了 ex 中。 于是先释放该缓冲块,并开始对
// ex 中的执行头信息进行判断处理。对于 Linux 0.11 内核来说,它仅支持 ZMAGTC 执行文件格
// 式,并且执行文件代码都从逻辑地址 0 开始执行,因此不支持含有代码或数据重定位信息的
// 执行文件。当然,如果执行文件实在太大或者执行文件残缺不全,那么我们也不能运行它。
// 因此对于下列情况将不执行程序:如果执行文件不是需求页可执行文件(ZMAGIC)、或者代
// 码和数据重定位部分长度不等于 0、或者(代码段+数据段+堆)长度超过 50MB、或者执行文件
// 长度小于 (代码段+数据段+符号表长度+执行头部分)长度的总和。brelse(bh);if (N_MAGIC(ex) != ZMAGIC || ex.a_trsize || ex.a_drsize ||ex.a_text+ex.a_data+ex.a_bss>0x3000000 ||inode->i_size < ex.a_text+ex.a_data+ex.a_syms+N_TXTOFF(ex)) {retval = -ENOEXEC;goto exec_error2;}
// 另外,如果执行文件中代码开始处没有位于 1 个页面(1024 字节)边界处,则也不能执行。
// 因为需求页(Demand paging)技术要求加载执行文件内容时以页面为单位,因此要求执行
// 文件映像中代码和数据都从页面边界处开始。if (N_TXTOFF(ex) != BLOCK_SIZE) {printk("%s: N_TXTOFF != BLOCK_SIZE. See a.out.h.", filename);retval = -ENOEXEC;goto exec_error2;}
// 如果 sh_bang 标志没有设置,则复制指定个数的命令行参数和环境字符串到参数和环境空间。
// 中。若 sh_bang 标志已经设置,则表明是将运行脚本解释程序,此时环境变量页面已经复制,
// 无须再复制。同样,若 sh_bang 没有置位而需要复制的话,那么此时指针 p 随着复制信息增
// 加而逐渐向小地址方向移动,因此这两个复制串函数执行完后,环境参数串信息块位于程序
// 参数串信息块的上方,并且 p 指向程序的第 1 个参数串。事实上,p 是 128KB 参数和环境空
// 间中的偏移值。因此如果 p=0,则表示环境变量与参数空间页面已经被占满,容纳不下了。if (!sh_bang) {p = copy_strings(envc,envp,page,p,0);p = copy_strings(argc,argv,page,p,0);if (!p) {retval = -ENOMEM;goto exec_error2;}}
/* OK, This is the point of no return */
/* OK,下面开始就没有返回的地方了 */
// 前面我们针对函数参数提供的信息对需要运行执行文件的命令行参数和环境空间进行了设置,
// 但还没有为执行文件做过什么实质性的工作,即还没有做过为执行文件初始化进程任务结构
// 信息、建立页表等工作。现在我们就来做这些工作。由于执行文件直接使用当前进程的"驱
// 壳",即当前进程将被改造成执行文件的进程,因此我们需要首先释放当前进程占用的某些
// 系统资源,包括关闭指定的已打开文件、占用的页表和内存页面等。然后根据执行文件头结
// 构信息修改 当前进程使用的局部描述符表 LDT 中描述符的内容,重新设置代码段和数据段描
// 述符的限长,再利用前面处理得到的 e_uid 和 e_gid 等信息来设置进程任务结构中相关的字
// 段。最后把执行本次系统调用程序的返回地址 eip 指向执行文件中代码的起始位置处。这。
// 样当本系统调用退出返回后就会去运行新执行文件的代码了。注意,虽然此时新执行文件代。
// 码和数据还没有从文件中加载到内存中,但其参数和环境块已经在 copy_strings() 中使用
// get_free_page(分配了物理内存页来保存数据,并在 change_ldt()函数中使用 put_page()
// 放到了进程逻辑空间的末端处。 另外,在 create_tables(中也会由于在用户栈上存放参数
// 和环境指针表而引起缺页异常,从而内存管理程序也会就此为用户栈空间映射物理内存页。
// 这里我们首先放回进程原执行程序的 i 节点,并且让进程 executable 字段指向新执行文件。
// 的 i 节点。然后复位原进程的所有信号处理句柄。[[但对于 SIG_IGN 句柄无须复位,因此在
// 322 与 323 行之间应该添加 1 条 if 语句:if (current->sa[i].sa_handler != SIG_IGN)]]
// 再根据设定的执行时关闭文件句柄(close_on_exec)位图标志,关闭指定的打开文件,并
// 复位该标志。if (current->executable)iput(current->executable);current->executable = inode;for (i=0 ; i<32 ; i++)current->sigaction[i].sa_handler = NULL;for (i=0 ; i<NR_OPEN ; i++)if ((current->close_on_exec>>i)&1)sys_close(i);current->close_on_exec = 0;
// 然后根据当前进程指定的基地址和限长,释放原来程序的代码段和数据段所对应的内存页表
// 指定的物理内存页面及页表本身。此时新执行文件并没有占用主内存区任何页面,因此在处
// 理器真正运行新执行文件代码时就会引起缺页异常中断,此时内存管理程序即会执行缺页处
// 理而为新执行文件申请内存页面和设置相关页表项,并且把相关执行文件页面读入内存中。
// 如果"上次任务使用了协处理器"指向的是当前进程,则将其置空,并复位使用了协处理器
// 的标志。free_page_tables(get_base(current->ldt[1]),get_limit(0x0f));free_page_tables(get_base(current->ldt[2]),get_limit(0x17));if (last_task_used_math == current)last_task_used_math = NULL;current->used_math = 0;
// 然后我们根据新执行文件头结构中的代码长度字段 a_text 的值修改局部表中描述符基址和。
// 段限长,并将 128KB 的参数和环境空间页面放置在数据段末站。执行下面语句之后,p 此时
// 更改成以数据段起始处为原点的偏移值,但仍指向参数和环境空间数据开始处,即已转换成
// 为栈指针值。然后调用内部函数 create_tables()在栈空间中创建环境和参数变量指针表,
// 供程序的 main()作为参数使用,并返回该栈指针。p += change_ldt(ex.a_text,page)-MAX_ARG_PAGES*PAGE_SIZE;p = (unsigned long) create_tables((char *)p,argc,envc);
// 接着再修改进程各字段值为新执行文件的信息。即令进程任务结构代码尾字段 end_code 等。
// 于执行文件的代码段长度 a_text;数据尾字段 end_data 等于执行文件的代码段长度加数
// 据段长度(a_data + a_text);并令进程堆结尾字段 brk = a_text + a_data + a_bss。
// brk 用于指明进程当前数据段(包括未初始化数据部分)末端位置。然后设置进程栈开始字
// 段为栈指针所在页面,并重新设置进程的有效用户 id 和有效组 id。current->brk = ex.a_bss +(current->end_data = ex.a_data +(current->end_code = ex.a_text));current->start_stack = p & 0xfffff000;current->euid = e_uid;current->egid = e_gid;
// 如果执行文件代码加数据长度的末端不在页面边界上,则把最后不到 1 页长度的内存空间初
// 始化为零。[[ 实际上由于使用的是 ZMAGIC 格式的执行文件,因此代码段和数据段长度均是
// 页面的整数倍长度,因此 343 行不会执行,即(i&0xfff) = 0。这段代码是 Linux 内核以前
// 版本的残留物:) ]]i = ex.a_text+ex.a_data;while (i&0xfff)put_fs_byte(0,(char *) (i++));
// 最后将原调用系统中断的程序在堆栈上的代码指针替换为指向新执行程序的入口点,并将栈
// 指针替换为新执行文件的栈指针。此后返回指令将弹出这些栈数据并使得 CPU 去执行新执行
// 文件,因此不会返回到原调用系统中断的程序中去了。eip[0] = ex.a_entry; /* eip, magic happens :-) */ /* eip,魔法起作用了*/eip[3] = p; /* stack pointer */ /* esp,堆栈指针 */return 0;
exec_error2:iput(inode); // 放回 i 节点。
exec_error1:for (i=0 ; i<MAX_ARG_PAGES ; i++)free_page(page[i]); // 释放存放参数和环境串的内存页面。return(retval); // 返回出错码。
}接下来程序,由于缺页,则会进入缺页处理程序。详细参加上面缺页处理部分。