做资源网站怎么不封/快速提高排名
目录
- 正则表达式基础
- 总结:
- 正则表达式进阶
每次做题或者看程序都会看到正则表达式,都会有点晕,今天就来整理一番
正则表达式基础
[ABC] 匹配集合中的任何字符

[^ABC] 匹配不在集合中的任何字符(相当于取反)

[A-Z]匹配ASCII码在指定范围区间的字符
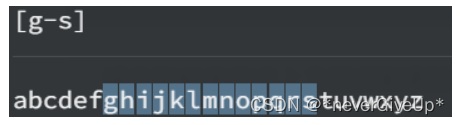
在特殊字符前加上 \ 代表匹配特殊字符

快捷方式:
- \d 与任意数字匹配
- \w 匹配字母,数字,下划线
- \s 匹配空白字符,比如空格,tab,换行等
- \b 匹配的市单词边界(空格也是字符边界)

^ 代表一个字符串的开始;$ 代表一个字符串的结束
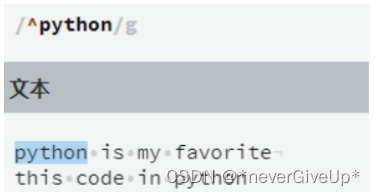
. 字符代表匹配任何单个字符,它只能出现在方括号以外

?字符指定一个字符,意味着该字符出现0次或者1次,另外一个作用是非贪婪模式
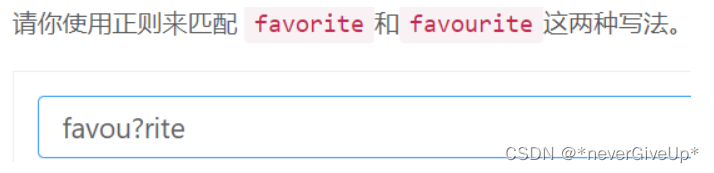
快捷方式取反:
- \D 匹配所有的非数字
- \W 匹配所有的非字符
- \S 匹配所有的非空白
{N} 表示在它之前的字符组出现N次
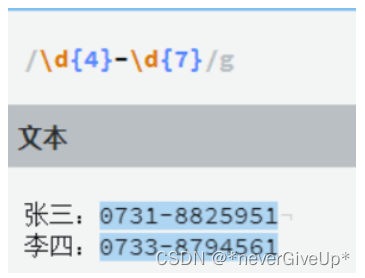
{M,N} 重复区间,M是下界而N是上界

\d{3,4} 既可以匹配3个数字也可以匹配4个数字,不过当有4个数字的时候,匹配的是4个数字,因为正则表达式默认的贪婪模式,尽可能的匹配更多字符,而使用非非贪婪模式,我们要在表达式后面加上?号
总结:
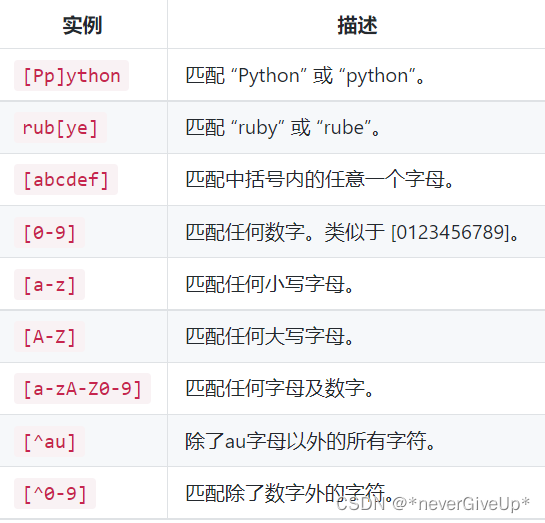

正则表达式进阶
分组()

这段正则表达式将文本分成了两组,第一组为0731,第二组为8825951
或者条件 |
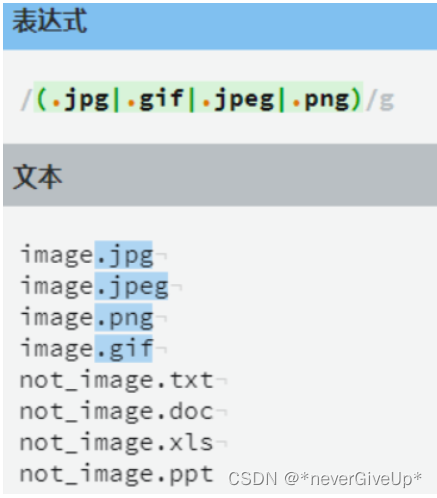
非捕获分组(?:表达式)
有时我们不需要捕获某个分组的内容,但是又想使用分组的特性
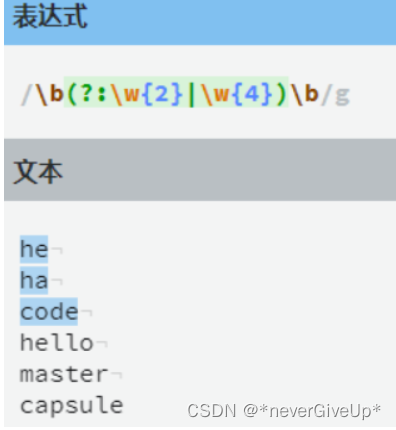
分组的回溯引用
正则表达式还提供了一种引用之前匹配分组的机制,有些时候,我们或许会寻找到一个子匹配,改匹配接下来会再次出现。可以使用分组的回溯引用,使用\N可以引用编好为N的分组
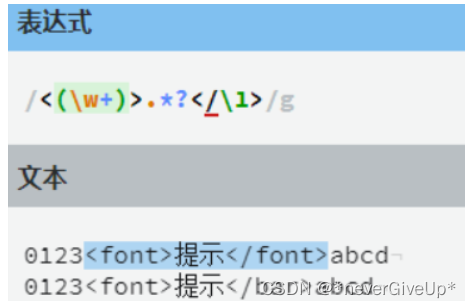
通过这个例子,可以发现 \1 表示的就是第一个分组,在这里第一个分组匹配的是
font 所以\1 就代表font
正向先行断言(?=表达式)
指某个位置向右看,表示所在位置右侧必须能匹配表达式。
我喜欢你 我喜欢我 我喜欢我 喜欢 喜欢你
如何要取出喜欢这两个字,要求在喜欢后面有你,这个时候就要这么写:喜欢(?=你),这就是正向先行断言
反向先行断言 (?!表达式) 保证右边不能出现某字符
我喜欢你 我喜欢 我喜欢我 喜欢 喜欢你
如果要取出喜欢两个字,要求这个喜欢后面没有你,这个时候就要这么写:喜欢(?!你),这就是反向先行断言
正向后行断言 (?<=表达式) 指在某个位置向左看,表示所在位置左侧必须能匹配表达式
例如:如果要取出喜欢两个字,要求喜欢的前面有我,后面有你,这个时候就要这么写:
(?<=我)喜欢(?=你)
反向后行断言 (?<!表达式) 指在某个位置向左看,表示所在位置左侧不能匹配表达式
例如:如果要取出喜欢两个字,要求喜欢的前面没有我,后面没有你,这个时候就要这么写:
(?<!我)喜欢(?!你)。
正则在线测试工具:https://regexr-cn.com/#native_link#
正则练习:https://codejiaonang.com/#/course/regex_chapter1/0/0