seo服务理念/优化模型数学建模
“ 词向量是词汇表的单词和短语和实数向量的映射结果,词向量已经被证明可以提高NLP任务的性能,有助于更好的完成语法分析和情感分析。本文主要是基于开源的工具完成一个定制化的词向量的训练。”
01
—
词向量的定义
词向量(Word embedding),又叫Word嵌入式自然语言处理(NLP)中的一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。从概念上讲,它涉及从每个单词一维的空间到具有更低维度的连续向量空间的数学嵌入。
生成这种映射的方法包括神经网络,单词共生矩阵的降维,概率模型,可解释的知识库方法,和术语的显式表示单词出现的背景。
当用作底层输入表示时,单词和短语嵌入已经被证明可以提高NLP任务的性能,例如语法分析和情感分析
百度百科
02
—
中文分词
国内主流的中文分词工具
jieba(结巴分词) 免费使用
HanLP(汉语言处理包) 免费使用
SnowNLP(中文的类库) 免费使用
FoolNLTK(中文处理工具包) 免费使用
Jiagu(甲骨NLP) 免费使用
pyltp(哈工大语言云) 商用需要付费
THULAC(清华中文词法分析工具包) 商用需要付费
NLPIR(汉语分词系统) 付费使用
Fnlp(复旦中文类库) 免费试用
本文使用jieba作为分词工具
各个分词工具大同小异,各有特色,在不同的数据集合上表现也各有差异,读者实际操作过程中可以进行对比测试,从性能、分词效果、工具使用便捷性等角度综合考量。
jieba实现分词
def wordcut(text,user_dict): # 获取原始文本数据 text=pd.read_excel(text,'sheet1') # 并行加速 jieba.enable_parallel(64) # 加载用户自定义词典 jieba.load_userdict(user_dict) # 对文档进行分析 text['文本分词'] = text['正文'].apply(lambda i:jieba.cut(i) ) text['文本分词'] =[' '.join(i) for i in text['文本分词']] # 将series结构的数据,切分成列表 sentence=[i.split() for i in text['文本分类']] # 返回分词的列表 return sentence获取停用词列表
# 获取停用词列表def stopwordslist(stoplist): stopwords = [line.strip() for line in open(stoplist, 'r', encoding='utf-8').readlines()] return stopwords移除停用词
像“的”、“】”等没有太多实际含义的词其实会影响词向量的构建,所以很有必要将其从词列表中移除。
# 分词后的文本移除停用词def movestopwords(sentence,stoplist): stopwords = stopwordslist(stoplist) for i in range(len(sentence)): sentence[i] = [x for x in sentence[i] if len(x) > 1 and x.strip() not in stopwords] if(i%100==0): print(i) return sentence03
—
词向量模型训练
语料选择和分词
获取文本语料库,本文使用复旦的分类文本语料,读者在训练的过程中可以根据实际情况选择合适的语料。
# 读取文本语料,并进行分词sentences = wordcut('data/复旦大学中文文本分类语料.xlsx', 'data/keyword.txt')# 将分词后的内容去除停用词retain_sentences = movestopwords(sentences,'data/stopwords_all.txt')模型训练
训练模型的接口

关键参数说明
sentences :供训练的句子
size :word向量的维度。
window :一个句子中当前单词和被预测单词的最大距离。
min_count : 忽略词频小于此值的单词。
workers :训练模型时使用的线程数。
sg : 模型的训练算法: 1代表skip-gram; 0代表CBOW.
hs :1代表 采用hierarchical softmax训练模型; 0代表使用负采样。
# word2vec 词向量训练model = gensim.models.Word2Vec(sentences,min_count =3,window =8,workers=4, size=100, sg=1)# 将词向量保存到本文路径,此处采取非二进制的保存方式model.wv.save_word2vec_format("./word2Vec" + ".txt", binary=False)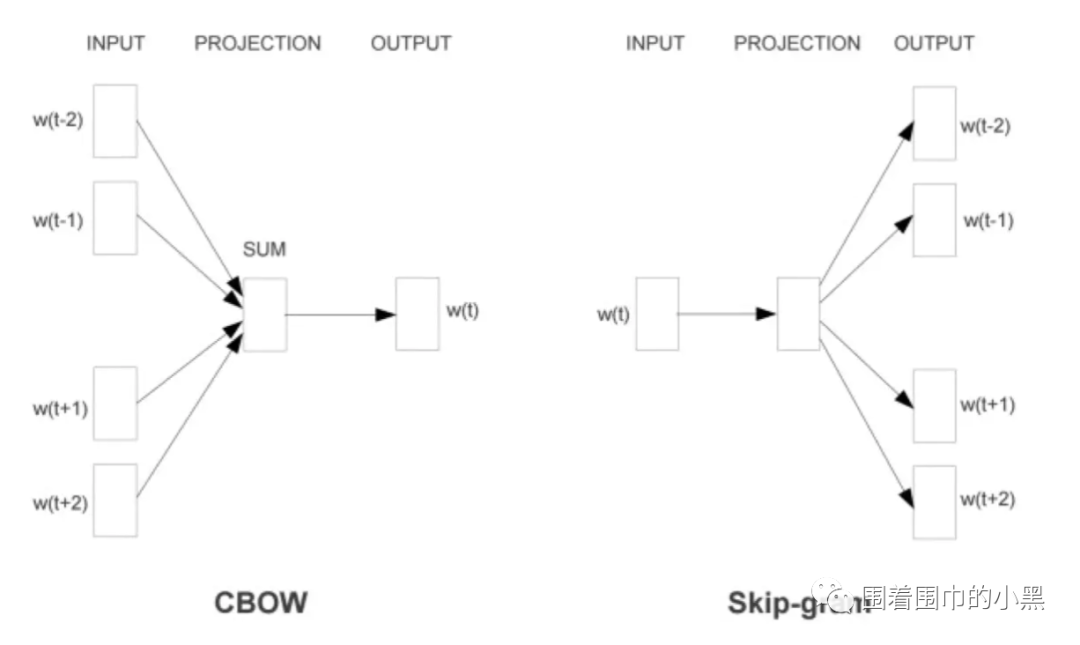
图1、训练词向量的两种算法CBOW和Skip-gramm
04
—
词向量验证
相似词组和词组间的相似度计算
# 模型加载word2vec_model = gensim.models.KeyedVectors.load_word2vec_format('./word2Vec.txt')# 寻找相似的词res1 = word2vec_model.wv.most_similar(u"经济")# 计算词直接的相似度res2 = word2vec_model.wv.similarity(u"经济发展", u"发展")print (res1[0],res1[1])# 结果('经济发展', 0.8110860586166382) ('发展', 0.788112998008728)print(res2)# 结果0.87487227感兴趣的读者可以多多关注本公众号,后续会持续分享科技、金融方面的话题,尤其是金融大数据分析领域。
