做网站开发要多久/产品网络推广的方法有哪些
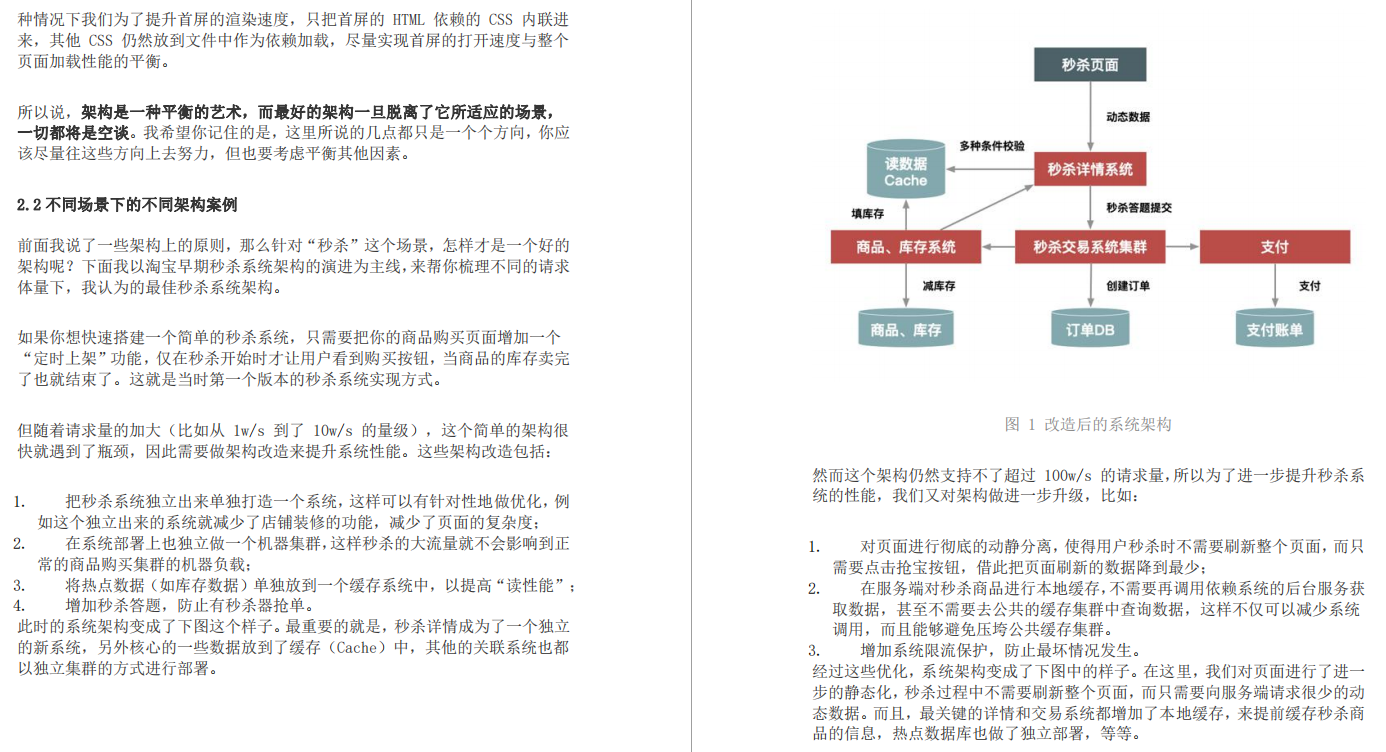
前言
微服务是近年来备受关注的话题,相比于传统的SOA而言,更容易理解,也更容易实践,它将“面向服务”的思想做得更加彻底。有人说它非常好,但就是“玩不起”,why?
微服务是一种分布式系统架构,它建议我们将业务切分为更加细粒度的服务,并使每个服务的责任单一且可独立部署,服务内部高内聚,隐含内部细节,服务之间低耦合,彼此相互隔离。此外,我们根据面向服务的业务领域来建模,对外提供统一的API接口。微服务的思想不只是停留在开发阶段,它贯穿于设计、开发、测试、部署、运维等软件生命周期阶段。
可见,我们提到的微服务,实际上是一种架构思想,我们不妨称它为“微服务架构”。今天就带着大家;来学习这份阿里技术专家手写的《微服务架构笔记》,让你成为一名优秀的微服务架构师。

Cache aside
Cache aside也就是旁路缓存,是比较常用的缓存策略。
(1)读请求常见流程
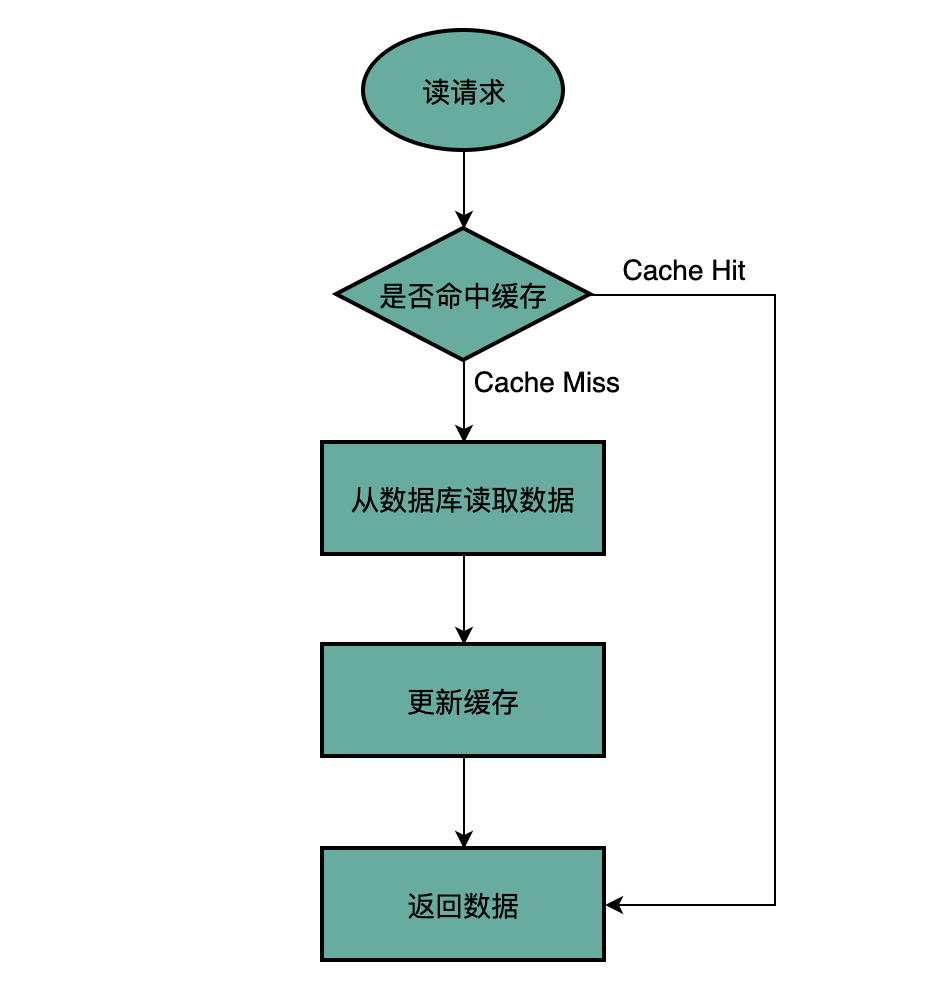
应用首先会判断缓存是否有该数据,缓存命中直接返回数据,缓存未命中即缓存穿透到数据库,从数据库查询数据然后回写到缓存中,最后返回数据给客户端。
(2)写请求常见流程
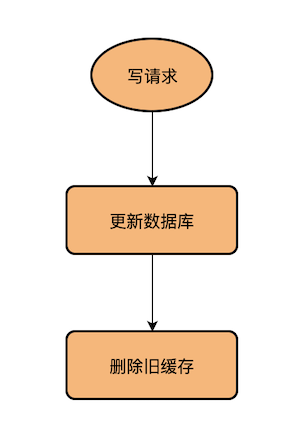
首先更新数据库,然后从缓存中删除该数据。
看了写请求的图之后,有些同学可能要问了:为什么要删除缓存,直接更新不就行了?这里涉及到几个坑,我们一步一步踩下去。
Cache aside踩坑
Cache aside策略如果用错就会遇到深坑,下面我们来逐个踩。
踩坑一:先更新数据库,再更新缓存
如果同时有两个写请求需要更新数据,每个写请求都先更新数据库再更新缓存,在并发场景可能会出现数据不一致的情况。
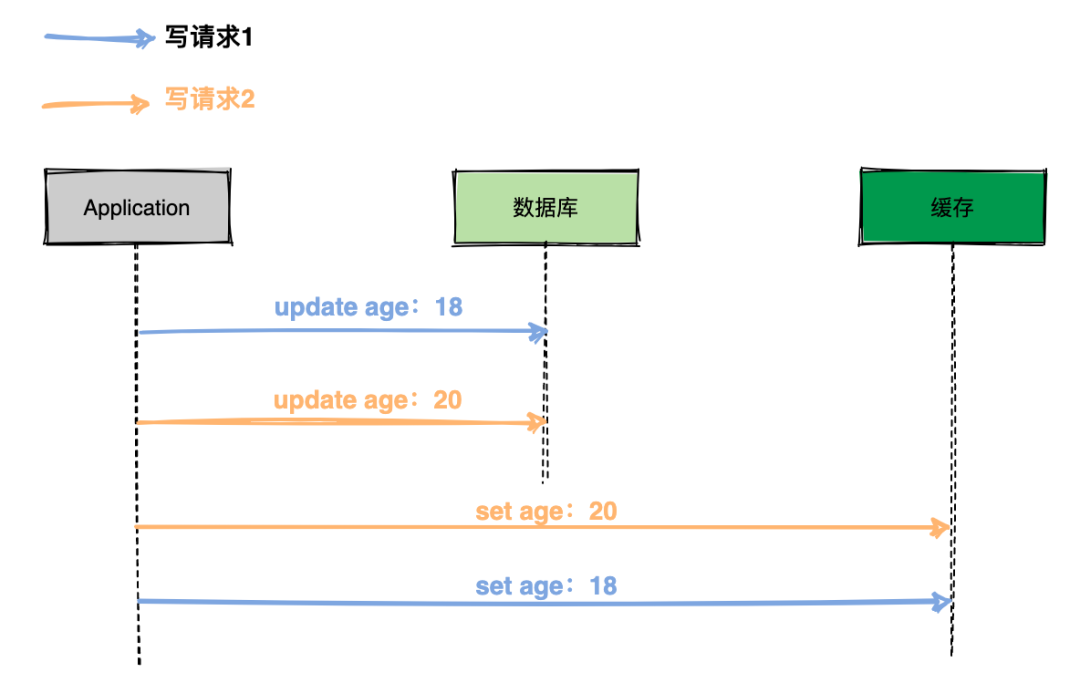
如上图的执行过程:
(1)写请求1更新数据库,将 age 字段更新为18;
(2)写请求2更新数据库,将 age 字段更新为20;
(3)写请求2更新缓存,缓存 age 设置为20;
(4)写请求1更新缓存,缓存 age 设置为18;
执行完预期结果是数据库 age 为20,缓存 age 为20,结果缓存 age为18,这就造成了缓存数据不是最新的,出现了脏数据。
踩坑二:先删缓存,再更新数据库
如果写请求的处理流程是先删缓存再更新数据库,在一个读请求和一个写请求并发场景下可能会出现数据不一致情况。
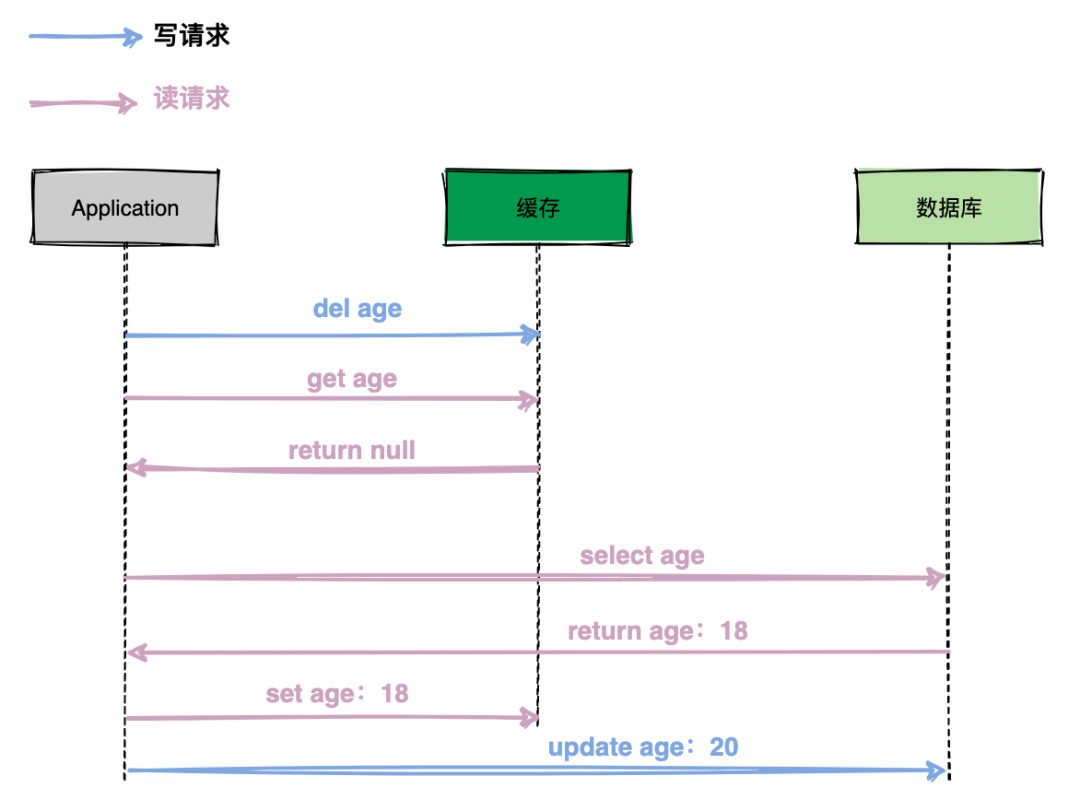
如上图的执行过程:
(1)写请求删除缓存数据;
(2)读请求查询缓存未击中(Hit Miss),紧接着查询数据库,将返回的数据回写到缓存中;
(3)写请求更新数据库。
整个流程下来发现数据库中age为20,缓存中age为18,缓存和数据库数据不一致,缓存出现了脏数据。
踩坑三:先更新数据库,再删除缓存
在实际的系统中针对写请求还是推荐先更新数据库再删除缓存,但是在理论上还是存在问题,以下面这个例子说明。
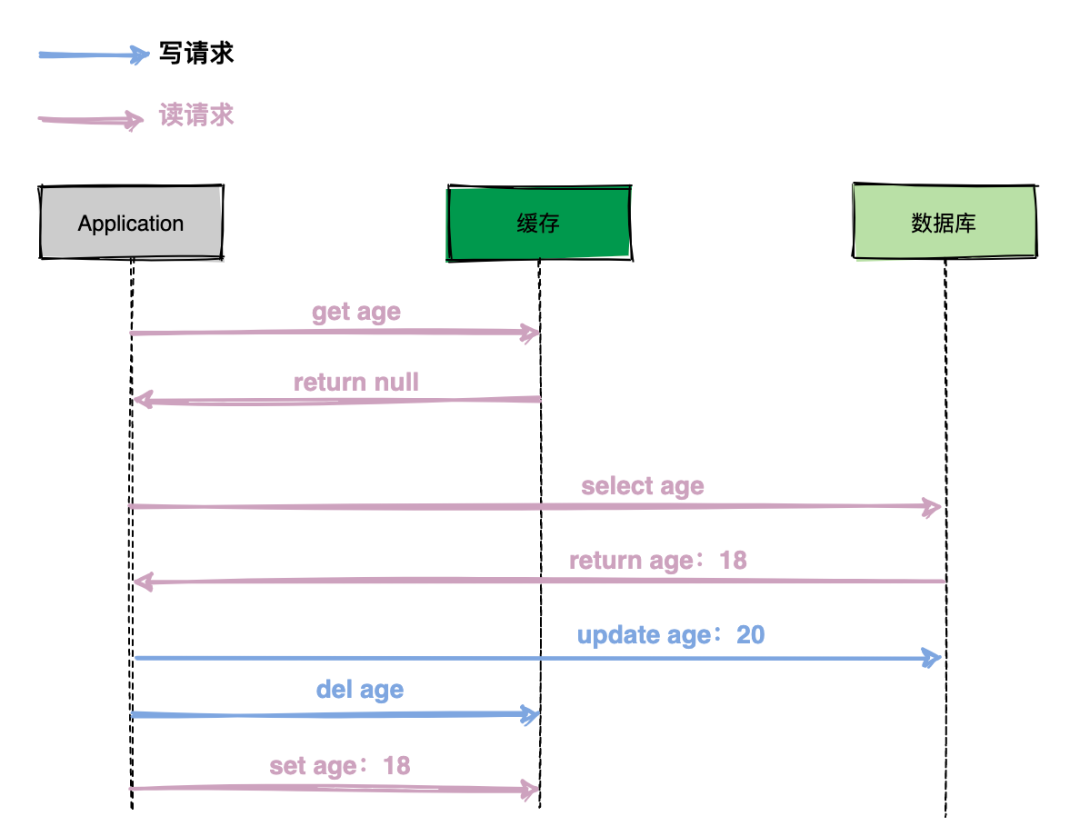
如上图的执行过程:
(1)读请求先查询缓存,缓存未击中,查询数据库返回数据;
(2)写请求更新数据库,删除缓存;
(3)读请求回写缓存;
整个流程操作下来发现数据库age为20,缓存age为18,即数据库与缓存不一致,导致应用程序从缓存中读到的数据都为旧数据。
但我们仔细想一下,上述问题发生的概率其实非常低,因为通常数据库更新操作比内存操作耗时多出几个数量级,上图中最后一步回写缓存(set age 18)速度非常快,通常会在更新数据库之前完成。
如果这种极端场景出现了怎么办?我们得想一个兜底的办法:缓存数据设置过期时间。通常在系统中是可以允许少量的数据短时间不一致的场景出现。
Read through
在 Cache Aside 更新模式中,应用代码需要维护两个数据源头:一个是缓存,一个是数据库。而在 Read-Through 策略下,应用程序无需管理缓存和数据库,只需要将数据库的同步委托给缓存提供程序 Cache Provider 即可。所有数据交互都是通过抽象缓存层完成的。
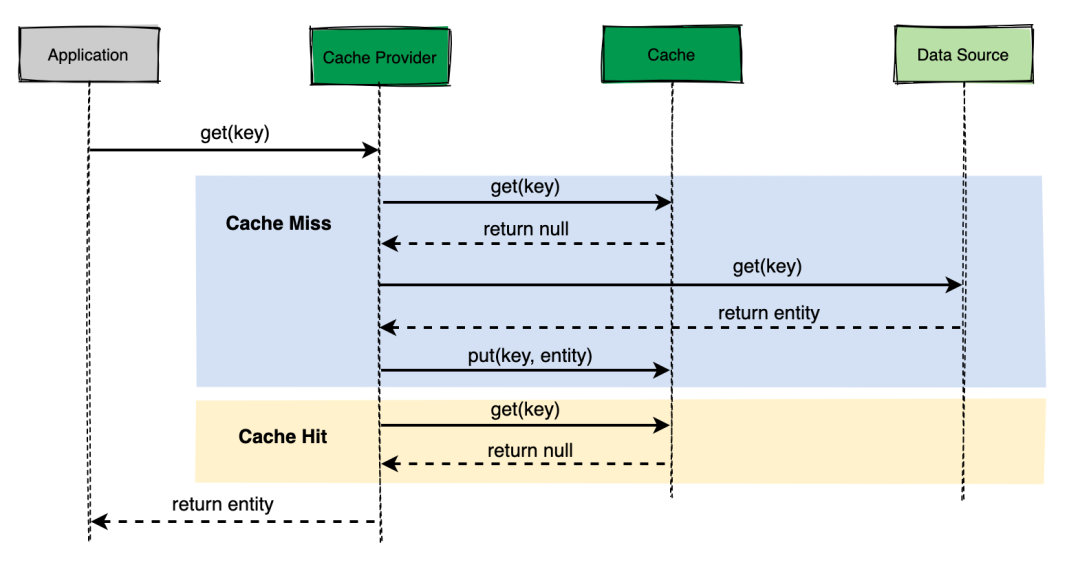
如上图,应用程序只需要与Cache Provider交互,不用关心是从缓存取还是数据库。
在进行大量读取时,Read-Through 可以减少数据源上的负载,也对缓存服务的故障具备一定的弹性。如果缓存服务挂了,则缓存提供程序仍然可以通过直接转到数据源来进行操作。
Read-Through 适用于多次请求相同数据的场景,这与 Cache-Aside 策略非常相似,但是二者还是存在一些差别,这里再次强调一下:
- 在 Cache-Aside 中,应用程序负责从数据源中获取数据并更新到缓存。
- 在 Read-Through 中,此逻辑通常是由独立的缓存提供程序(Cache Provider)支持。
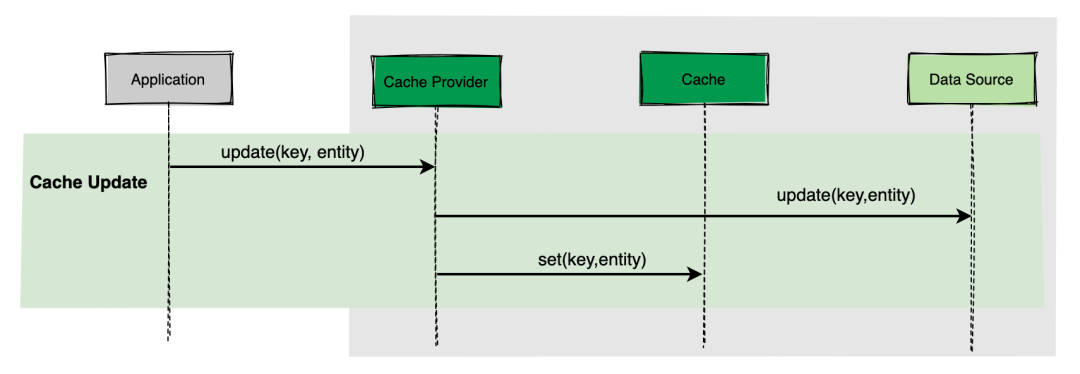
Write through
Write-Through 策略下,当发生数据更新(Write)时,缓存提供程序 Cache Provider 负责更新底层数据源和缓存。
缓存与数据源保持一致,并且写入时始终通过抽象缓存层到达数据源。
Cache Provider类似一个代理的作用。
Write behind
Write behind在一些地方也被成为Write back, 简单理解就是:应用程序更新数据时只更新缓存, Cache Provider每隔一段时间将数据刷新到数据库中。说白了就是延迟写入。
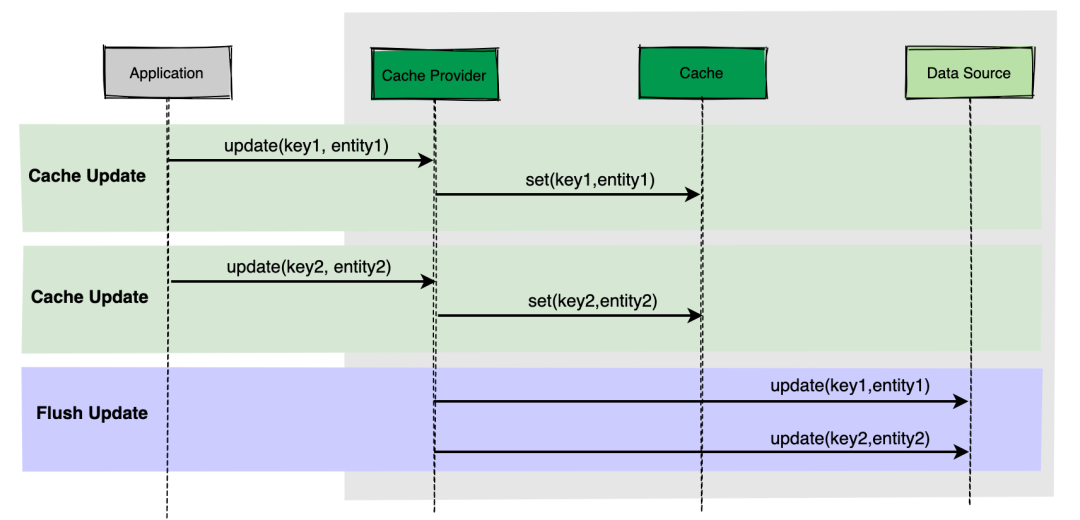
如上图,应用程序更新两个数据,Cache Provider 会立即写入缓存中,但是隔一段时间才会批量写入数据库中。
这种方式有优点也有缺点:
-
优点是数据写入速度非常快,适用于频繁写的场景。 -
缺点是缓存和数据库不是强一致性,对一致性要求高的系统慎用。
总目录展示
该笔记共八个节点(由浅入深),分为三大模块。
高性能。 秒杀涉及大量的并发读和并发写,因此支持高并发访问这点非常关键。该笔记将从设计数据的动静分离方案、热点的发现与隔离、请求的削峰与分层过滤、服务端的极致优化这4个方面重点介绍。
一致性。 秒杀中商品减库存的实现方式同样关键。可想而知,有限数量的商品在同一时刻被很多倍的请求同时来减库存,减库存又分为“拍下减库存”“付款减库存”以及预扣等几种,在大并发更新的过程中都要保证数据的准确性,其难度可想而知。因此,将用一个节点来专门讲解如何设计秒杀减库存方案。
高可用。 虽然介绍了很多极致的优化思路,但现实中总难免出现一些我们考虑不到的情况,所以要保证系统的高可用和正确性,还要设计一个PlanB来兜底,以便在最坏情况发生时仍然能够从容应对。笔记的最后,将带你思考可以从哪些环节来设计兜底方案。
篇幅有限,无法一个模块一个模块详细的展示(这些要点都收集在了这份《高并发秒杀顶级教程》里),觉得有需要的码友们,麻烦各位转发一下(可以帮助更多的人看到哟!)点这里,即可获得免费下载的方式!!

由于内容太多,这里只截取部分的内容。需要这份《高并发秒杀顶级教程》的小伙伴,麻烦各位帮忙点赞分享支持一下(可以帮助更多的人看到哟!)
中…(img-xPiT2kBR-1623303986811)]
[外链图片转存中…(img-iNbCIayx-1623303986812)]
由于内容太多,这里只截取部分的内容。需要这份《高并发秒杀顶级教程》的小伙伴,麻烦各位帮忙点赞分享支持一下(可以帮助更多的人看到哟!)