营销型网站建设公司推荐/推广普通话的意义
目录
- shuffle
- 为什么要有shuffle
- shuffle分类
- Shuffle Write
- Shuffle Read
- shuffle可能会面临的问题
- HashShuffle优化解决问题
- reduce分区数决定因素
- SortShuffle
shuffle
为什么要有shuffle
shuffle:为了让相同的key进入同一个reduce
每一个key对应的value不一定都在同一个分区中,也未必都在同一个节点上,而是极可能分布在各个节点上
shuffle分类
Shuffle Write
发生在map端的shuffle,需要将数据进行分组排序,将数据写出去
Shuffle Read
发生在reduce端的shuffle,将数据读进来
shuffle可能会面临的问题
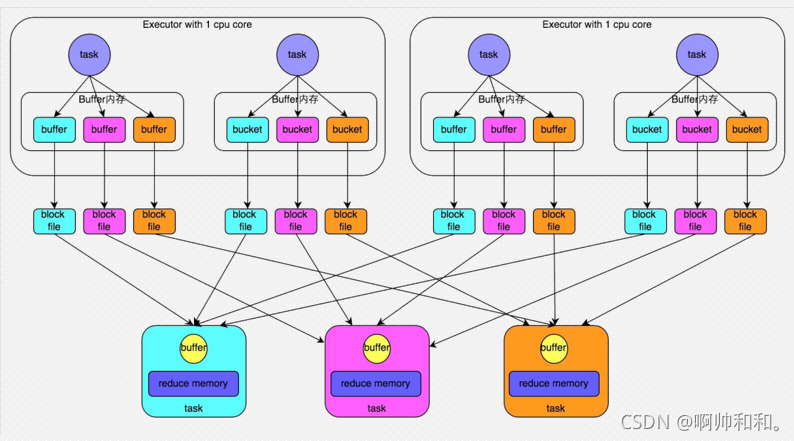
为了让不同分区的文件进入同一个reduce(这里有三个reduce),这里会形成map的数量*reduce数量的文件,reduce的数量由分区数决定,分区数量由切片数量决定,切片数量差不多是128MB一个切片
假如我们这里有10G的文件,128MB切一个文件,差不多就是80个文件,那这里就有80*80=6400个文件,小文件非常多,会很影响效率
HashShuffle优化解决问题
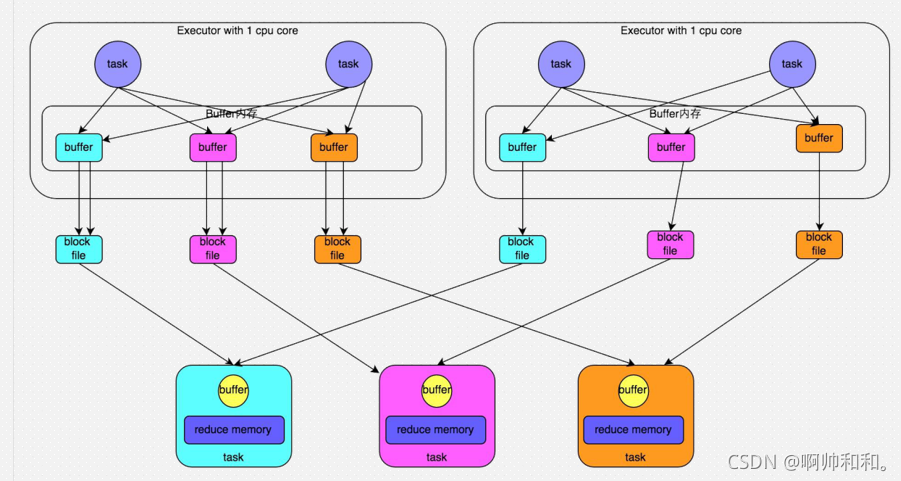
每个Executor都带1核,每次最多只能执行一个task,这里面的task依次运行,每次只能生成一个文件,每一个Executor最终生成和reduce个数对应的文件
这里的文件就是核数reduce个数,而凡是shuffle类的算子都可以指定分区
reduce分区数决定因素
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("Demo10Broadcast")//通过conf设置spark默认的并行度conf.set("spark.default.parallelism","4")val sc: SparkContext = new SparkContext(conf)//在集群中运行的时候,默认最少是两个分区val stuRDD: RDD[String] = sc.textFile("D:\\BigDaTa\\JAVA_Project\\ShuJia01\\data\\students.txt",2)println(stuRDD.getNumPartitions) //2个分区//如果没有产生shuffle,那么子RDD的分区数由父RDD的分区数决定val wordsRDD: RDD[String] = stuRDD.flatMap(_.split(","))println(wordsRDD.getNumPartitions)val mapRDD: RDD[(String, Int)] = wordsRDD.map(word=>(word,1))println(mapRDD.getNumPartitions)val repRDD: RDD[(String, Int)] = mapRDD.repartition(4)println(repRDD.getNumPartitions)//shuffle类的算子可以手动指定分区数//相当于手动设置reduce个数val wordCntRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_,3) //这里如果不指定为3的话,就会使用默认的并行度4println(wordCntRDD.getNumPartitions)/*** shuffle类算子产生的RDD的分区数决定因素* 1、如果没有指定,默认和父RDD分区数一样* 2、可以手动指定修改分区数* 3、通过默认参数设置** 手动设置 > 默认设置 > 父RDD的分区数*/}
SortShuffle
spark使用的shuffle机制
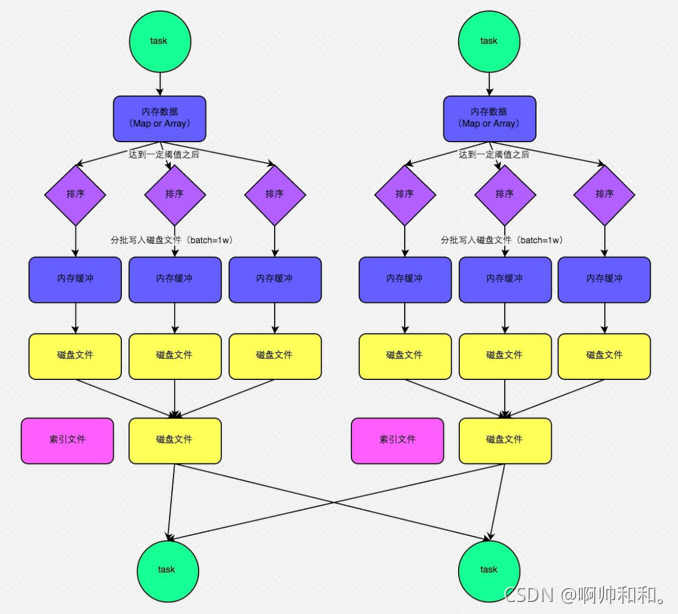
- 普通运行机制
- bypass运行机制
相比较普通运行,少了排序,reduce个数小于200,默认这种方式
这里的内存数据初始化时5MB,不够用了就*2
索引文件可以区分不同的分区,在找文件的时候可以更快一些
这里最后产生的文件的数量就是 2×分区 的数量
感谢阅读,我是啊帅和和,一位大数据专业大四学生,祝你快乐。