人力资源公司网站建设/搜索引擎营销的英文缩写是
一、事发背景
上个月的某一天,由于集群空间不足,公司有一位权限较高的员工通过跳板机在某个线上集群执行手动清理命令,疯狂地执行hadoop fs -rmr -skipTrash /user/hive/warehouse/xxxxx,突然,不知道是编辑器的问题还是换行问题,命令被截断,命令变成了hadoop fs -rmr -skipTrash /user/hive/warehouse,悲剧此刻开始发生!?
/user/hive/warehouse目录下存储了所有hive表的数据,关联公司多个业务线,一旦丢失,意味着巨大的损失。由于加了-skipTrash参数,意味着删除的数据不会放入回收站而是直接删除,这个参数不加的话很容易挽回,回收站里直接找,可惜逃不了墨菲定律,最担心的事还是发生了。
领导解决不了的事,只有小弟上,看我接下来怎样四两拨千斤。
二、应急措施
运维第一时间找到我,当时说误删了 /user/hive/warehouse目录。当时我也是一震惊,完了完了!凭我仅有的直觉,立马停掉了HDFS集群!后面证明是很明智的选择。
直观的方案
- 通过快照恢复?hdfs快照从来没用过,也没创建过快照,所以此路不通
- 通过回收站恢复?删除时加了-skipTrash参数,不会放回收站,此路也不通
- 删库跑路成为一代传奇人物?嗯,还不错
三、分析过程
想要恢复数据,首先要理解hdfs删除文件的过程,各个文件系统的删除逻辑都不一样,理解了hdfs的删除过程,才知道上面那一条hadoop fs -rmr xxxx究竟干了什么,究竟还有没有救,怎么去救等等问题。
-
hdfs文件删除过程
下面是hdfs删除路径的方法,源码路径
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.delete()boolean delete(String src, boolean recursive, boolean logRetryCache)throws IOException {waitForLoadingFSImage();BlocksMapUpdateInfo toRemovedBlocks = null;writeLock();boolean ret = false;try {checkOperation(OperationCategory.WRITE);checkNameNodeSafeMode("Cannot delete " + src);toRemovedBlocks = FSDirDeleteOp.delete( // @1this, src, recursive, logRetryCache);ret = toRemovedBlocks != null;} catch (AccessControlException e) {logAuditEvent(false, "delete", src);throw e;} finally {writeUnlock();}getEditLog().logSync();if (toRemovedBlocks != null) {removeBlocks(toRemovedBlocks); // @2}logAuditEvent(true, "delete", src);return ret;}代码@1里面做了三件比较重要的事
①从NameNode维护的的目录树里面删除路径,这也是为什么执行删除操作之后就无法再通过
hadoop fs -ls xxx或其它api方式再查看到路径的根本原因②找出被删路径关联的block信息,每个文件包含多个block块,分布在各个DataNode,此时并未真正物理删除DataNode上物理磁盘上的block块
③记录删除日志到editlog(这一步也很重要,甚至是后面恢复数据的关键)
代码@2把将要删除的block信息添加到
org.apache.hadoop.hdfs.server.blockmanagement.BlockManager里面维护的InvalidateBlocks对象中,InvalidateBlocks专门用于保存等待删除的数据块副本以上步骤并未涉及真正的物理删除的操作
BlockManager
BlockManager管理了hdfs block的生命周期并且维护在Hadoop集群中的块相关的信息,包括快的上报、复制、删除、监控、标记等等一系列功能。BlockManager中有个方法invalidateWorkForOneNode()专门用于定时删除InvalidateBlocks中存储的待删除的快,此方法会在NameNode启动时在BlockManager的内部线程类ReplicationMonitor定时轮循把要删除的块放入DatanodeDescriptor中的逻辑,方法的调用路径如下:org.apache.hadoop.hdfs.server.namenode.NameNode#initialize(Configuration conf) org.apache.hadoop.hdfs.server.namenode.NameNode#startCommonServices(Configuration conf)org.apache.hadoop.hdfs.server.namenode.FSNamesystem#startCommonServices(Configuration conf, HAContext haContext)org.apache.hadoop.hdfs.server.blockmanagement.BlockManager#activate(Configuration conf)org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.ReplicationMonitor#run()org.apache.hadoop.hdfs.server.blockmanagement.BlockManager#computeDatanodeWork()org.apache.hadoop.hdfs.server.blockmanagement.BlockManager#computeDatanodeWorkcomputeInvalidateWork(int nodesToProcess)org.apache.hadoop.hdfs.server.blockmanagement.BlockManager#invalidateWorkForOneNode(DatanodeInfo dn)org.apache.hadoop.hdfs.server.blockmanagement.InvalidateBlocks#invalidateWork(final DatanodeDescriptor dn)BlockManager维护了InvalidateBlocks,存放了待删除的 block,BlockManager在NameNode启动时会单独启动一个线程,定时把要删除的块信息放入InvalidateBlocks中,每次会从InvalidateBlocks队列中为每个DataNode取出blockInvalidateLimit(由配置项dfs.block.invalidate.limit,默认1000)个块逻辑在BlockManager.computeInvalidateWork()方法里会把要删除的块信息放入DatanodeDescriptor中的invalidateBlocks数组,DatanodeManager再通过DataNode与NameNode心跳时,构建删除块的指令集,NameNode再把指令下发给DataNode,心跳由DatanodeProtocol调用,方法的调用路径如下:org.apache.hadoop.hdfs.server.protocol.DatanodeProtocol#sendHeartbeat()org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer#sendHeartbeat()org.apache.hadoop.hdfs.server.namenode.FSNamesystem#handleHeartbeat()org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager#handleHeartbeat()DatanodeManager.handleHeartbeat()中构建删除的指令给DataNode,待NameNode发送,的代码如下:
/** Handle heartbeat from datanodes. */public DatanodeCommand[] handleHeartbeat(形参略){// ....其余代码逻辑略//check block invalidationBlock[] blks = nodeinfo.getInvalidateBlocks(blockInvalidateLimit);if (blks != null) {cmds.add(new BlockCommand(DatanodeProtocol.DNA_INVALIDATE,blockPoolId, blks));}// ....其余代码逻辑略return new DatanodeCommand[0];}定时轮循+limit 1000个块删除的特性决定了hdfs删除数据并不会立即真正的执行物理删除,并且一次删除的数量也有限,所以上面的应急措施中立即停止HDFS集群是最明智的选择,虽然有的数据在轮循中已被删除,所以事发后停止HDFS集群越早,被删的数据越少,损失越小!
EditLog
恢复数据的另一个关键是EditLog,EditLog记录了hdfs操作的每一条日志记录,包括当然包括删除,我们所熟知的文件操作类型只有增、删、改,但是在HDFS的领域里,远远不止这些操作,我们看看EditLog操作类型的枚举类org.apache.hadoop.hdfs.server.namenode.FSEditLogOpCodes
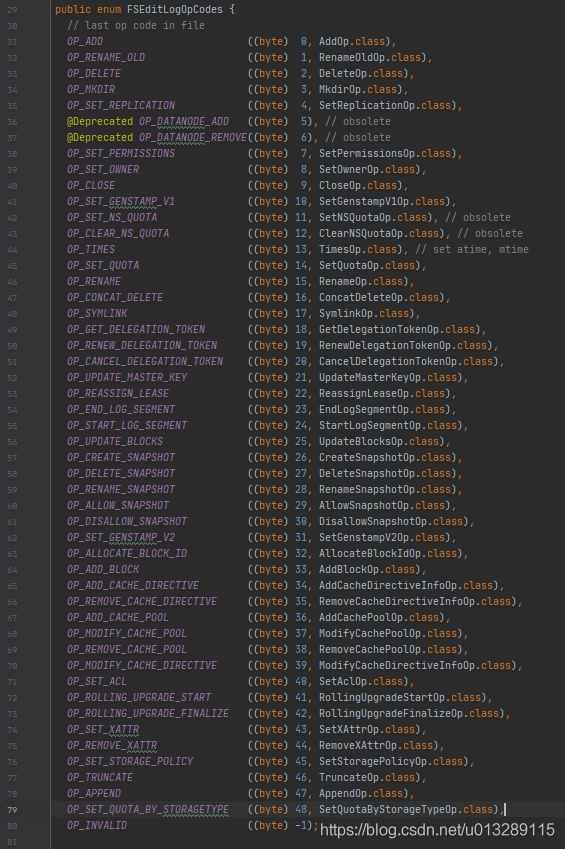
总计40多种操作类型!打破了人们印象中文件只有增删改读的几种操作,有木有突破你的想象?
EditLog长啥样呢?在hadoop的配置参数dfs.namenode.name.dir可以找到路径
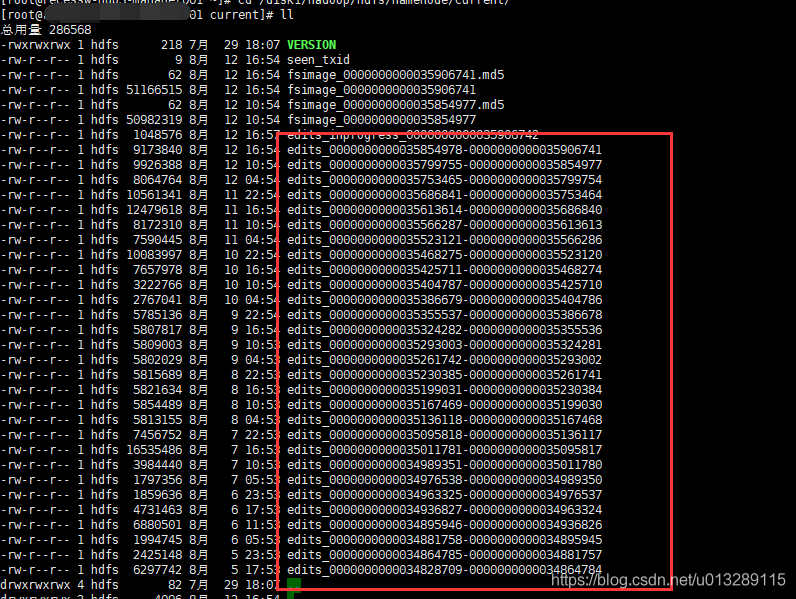
这里EditLog文件是序列化后的二进制文件不能直接查看,hdfs自带了解析的命令,可以解析成xml明文格式,我们解析一个看看
hdfs oev -i edits_0000000000035854978-0000000000035906741 -o edits.xml查看文件
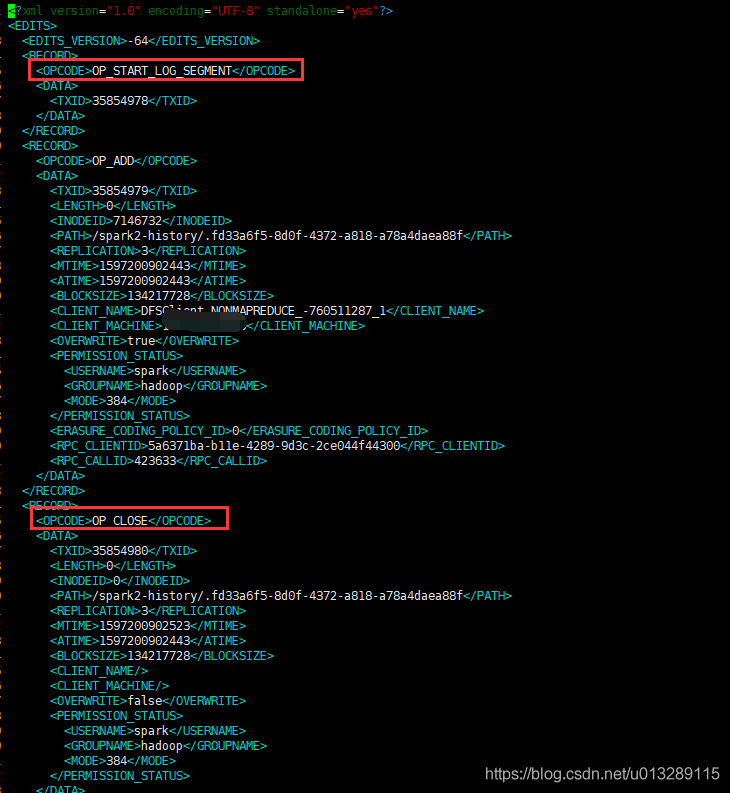
对hdfs的每一个操作都会记录一串RECORD,RECORD里面不同的操作包含的字段属性也不同,但是所有操作都具备的属性是OPCODE,对应上面的枚举类org.apache.hadoop.hdfs.server.namenode.FSEditLogOpCodes中40多种操作
hdfs元数据的加载
hdfs启动时,NameNode会加载Fsimage,Fsimage记录了hdfs现有的全量的路径信息,启动过程中仅仅加载Fsimage?这句话不完全正确!启动的同时,还会加载未被合并成fsimage的EditLog。关于fsimage具体细节这里不展开。举个栗子:
假设Hadoop 3分钟checkpoint一次生成Fsimage文件,EditLog 1分钟生成一个文件,下面是依次生成的文件:
fsimage_1
editlog_1
editlog_2
editlog_3
fsimage_2
editlog_4
editlog_5当NameNode启动时,会加载后缀时间戳最大的那个fsimage文件和它后面产生的editlog文件,也就是会加载fsimage_2、editlog_4、editlog_5进NameNode内存。假设我们执行hadoop fs -rmr xxx命令的操作记录在了editlog_5上面,那么,重启NameNode后,我们查看hdfs无法再查看到xxx路径,如果我们把fsimage_2删掉,NameNode则会加载fsimage_1、editlog_1、editlog_2,此时的元数据里面xxx还未被删除,如果此时DataNode未物理删除block,则数据可以恢复,但是editlog_4、editlog_5对应的hdfs操作会丢失。有没有更好的方法呢?
方案确定
方案一:删掉fsimage_2,从上一次checkpoint的地方也就是fsimage_1恢复,我们集群的实际配置,是一个小时生成一次fsimage文件,也就是说,这种恢复方案会导致近一小时hdfs新增的文件全部丢失,集群日工作流的的量2w左右,这一个小时不知道发生了多少事情,可想而知的后果是恢复之后一堆报错,显然不是最好的方案
方案二:修改editlog_5,把删除xxx那条操作改成其它安全的操作类型,这样重启NameNode后,又可以看到这个路径。good idea!就这么干!
四、灾难重演
为了完整的演示一遍恢复过程,我找了个测试环境重新演示一遍。请勿随意在生产环境演示!!!
-
删除路径
bash-4.2$ hadoop fs -ls /tmp/user/hive Found 1 items drwxrwxrwx - hdfs hdfs 0 2020-08-13 15:02 /tmp/user/hive/warehouse bash-4.2$ hadoop fs -rmr -skipTrash /tmp/user/hive/warehouse rmr: DEPRECATED: Please use '-rm -r' instead. Deleted /tmp/user/hive/warehouse bash-4.2$ bash-4.2$ hadoop fs -ls /tmp/user/hive bash-4.2$ -
关闭HDFS集群
-
解析editlog
找到删除操作时间点范围内所属的editlog文件,解析
hdfs oev -i edits_0000000000005827628-0000000000005827630 -o editlog.xml查看editlog.xml,执行删除操作的日志已经记录在里面了
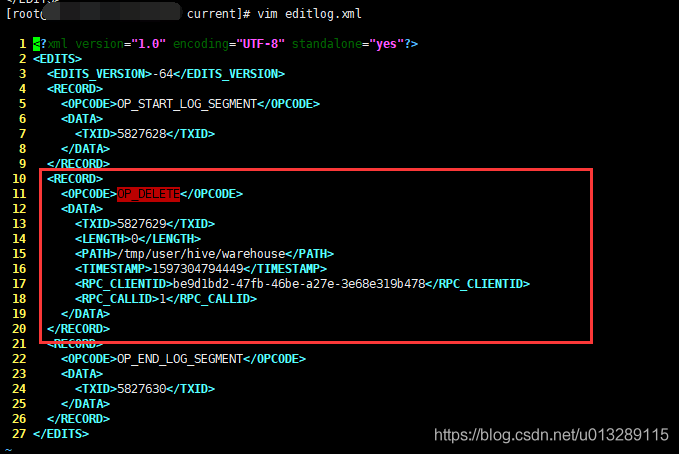
-
替换删除操作
把OP_DELETE操作替换成比较安全的操作,例如:
<RECORD><OPCODE>OP_SET_OWNER</OPCODE><DATA><TXID>5827629</TXID><SRC>/tmp/user/hive/warehouse</SRC><USERNAME>hadoop</USERNAME></DATA> </RECORD>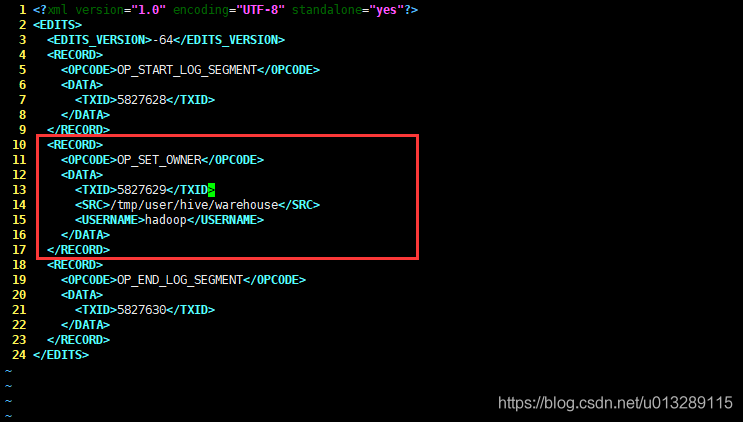
注意:TXID一定要一样!!!
-
反解析成editlog
# 反解析更改后的xml文件成editlog
hdfs oev -i editlog.xml -o edits_0000000000005827628-0000000000005827630.tmp -p binary
# 重命名掉之前的editlog
mv edits_0000000000005827628-0000000000005827630 edits_0000000000005827628-0000000000005827630.bak
# 替换反解析后的editlog
mv edits_0000000000005827628-0000000000005827630.tmp edits_0000000000005827628-0000000000005827630-
拷贝到JournalNodes
需要把修改后的editlog考本到所有JournalNode节点的本地editlog存放目录,可在
dfs.journalnode.edits.dir找到scp edits_0000000000005827628-0000000000005827630 xxx001:/hadoop/hdfs/journal/master/current/ scp edits_0000000000005827628-0000000000005827630 xxx002:/hadoop/hdfs/journal/master/current/ scp edits_0000000000005827628-0000000000005827630 xxx003:/hadoop/hdfs/journal/master/current/ -
启动HDFS
启动hdfs后,查看被删目录是否已恢复
bash-4.2$ hadoop fs -ls /tmp/user/hive
Found 1 items
drwxrwxrwx - hadoop hdfs 0 2020-08-13 15:41 /tmp/user/hive/warehouse被删除的**/tmp/user/hive/warehouse**目录已成功恢复!!
五、经验总结
- 从恢复程度来看,会有部分block块已被删除,读取时会报block missed之类的错误,但是已经把损失降到了最低,删除的多少取决于误删后停掉hdfs集群的时间,停的越早,损失越小
- 从预防方面,权限必须要控制好,由于线上跳板机权限给的过于随意导致了误操作的产生
- hdfs删数据的规范,一定不能加
-skipTrash做强制删除,放入回收站,多给自己和公司一些挽回的余地 - 这是一次宝贵的经历,头一回感受到处理时的心弦紧绷和成功解决后的兴奋激动,事后奶茶已收到,当事人也保住了饭碗,哈哈
作者:喜剧之皇
最后
如何获取免费架构学习资料?
资料获取方式:点击下方蓝色传送门
Java学习、面试;文档、视频资源免费获取

由于篇幅原因,就不多做展示了
)
[外链图片转存中…(img-YKFW0Usb-1623615718444)]
[外链图片转存中…(img-ouSCycQ5-1623615718445)]
[外链图片转存中…(img-0wRomx6y-1623615718445)]
[外链图片转存中…(img-of2dUEbe-1623615718445)]
[外链图片转存中…(img-Pz8mv0qJ-1623615718446)]
[外链图片转存中…(img-SgxWYRxT-1623615718446)]
由于篇幅原因,就不多做展示了