建立文档/企业seo顾问服务阿亮
★★★ 本文源自AI Studio社区精品项目,【点击此处】查看更多精品内容 >>>
0 项目背景
信息抽取任务旨在从非结构化的自然语言文本中提取结构化信息。在本系列项目中,将讨论如何又好又快地实现一个简历信息提取任务。
在前面的项目中,基本上都是以PaddleNLP为主导,进行简历信息抽取。
不过,随着PaddleOCR功能的愈发完善,或许可以换个思路,增加OCR能力在简历信息抽取中扮演的角色,提升识别效果,这就是从本项目起,我们试图实现的方案。
0.1 参考资料
- 简历信息提取(一):PDFPlumber和PP-Structure
- 简历信息提取(二):HR救星!用UIE Taskflow快速完成简历信息批量抽取
- 简历信息提取(三):文本抽取的UIE格式转换与微调训练
- 简历信息提取(四):文本抽取微调模型的部署应用
1 数据集和环境准备
# 解压缩数据集
!unzip data/data40148/train_20200121.zip
# 安装依赖库
!pip install python-docx
!pip install pypinyin
!pip install LAC
!pip install --upgrade paddlenlp
!pip install --upgrade paddleocr
!pip install pymupdf
# 首次更新完以后,重启后方能生效
import datetime
import os
import fitz # fitz就是pip install PyMuPDF
import cv2
import shutil
import numpy as np
import pandas as pd
from tqdm import tqdm
import json
!git clone https://gitee.com/paddlepaddle/PaddleOCR.git
正克隆到 'PaddleOCR'...
remote: Enumerating objects: 45329, done.[K
remote: Counting objects: 100% (19708/19708), done.[K
remote: Compressing objects: 100% (7075/7075), done.[K
remote: Total 45329 (delta 14389), reused 17603 (delta 12496), pack-reused 25621[K
接收对象中: 100% (45329/45329), 335.43 MiB | 20.84 MiB/s, 完成.
处理 delta 中: 100% (32250/32250), 完成.
检查连接... 完成。
2 思路介绍
简历信息提取是一种典型的关键信息抽取 (Key Information Extraction, KIE)任务,要从文本或者图像中,抽取出关键的信息。
一般的KIE方法基于命名实体识别(Named Entity Recognition,NER)来展开研究,这也是我们在前置项目中,探索的主要方向。但是此类方法仅使用了文本信息而忽略了位置与视觉特征信息,因此精度受限。近几年大多学者开始融合多个模态的输入信息,进行特征融合,并对多模态信息进行处理,从而提升KIE的精度。主要方法有以下几种:
- (1)基于Grid的方法:此类方法主要关注图像层面多模态信息的融合,文本大多大多为字符粒度,对文本与结构结构信息的嵌入方式较为简单,如Chargrid等算法。
- (2)基于Token的方法:此类方法参考NLP中的BERT等方法,将位置、视觉等特征信息共同编码到多模态模型中,并且在大规模数据集上进行预训练,从而在下游任务中,仅需要少量的标注数据便可以获得很好的效果。如LayoutLM, LayoutLMv2, LayoutXLM, StrucText等算法。
- (3)基于GCN的方法:此类方法尝试学习图像、文字之间的结构信息,从而可以解决开集信息抽取的问题(训练集中没有见过的模板),如GCN、SDMGR等算法。
- (4)基于End-to-end的方法:此类方法将现有的OCR文字识别以及KIE信息抽取2个任务放在一个统一的网络中进行共同学习,并在学习过程中相互加强。如Trie等算法。
PaddleOCR中实现了LayoutXLM等算法(基于Token),同时,在PP-StructureV2中,对LayoutXLM多模态预训练模型的网络结构进行简化,去除了其中的Visual backbone部分,设计了视觉无关的VI-LayoutXLM模型,同时引入符合人类阅读顺序的排序逻辑以及UDML知识蒸馏策略,最终同时提升了关键信息抽取模型的精度与推理速度。
在本文中,我们就准备直接使用PaddleOCR提供的预训练模型,完成简历关键信息抽取任务。
3 准备预训练模型
在PaddleOCR中,已支持的关键信息抽取算法列表如下:
- VI-LayoutXLM
- LayoutLM
- LayoutLMv2
- LayoutXLM
- SDMGR
在XFUND_zh公开数据集上,算法效果如下:
| 模型 | 骨干网络 | 任务 | hmean |
|---|---|---|---|
| VI-LayoutXLM | VI-LayoutXLM-base | SER | 93.19% |
| LayoutXLM | LayoutXLM-base | SER | 90.38% |
| LayoutLM | LayoutLM-base | SER | 77.31% |
| LayoutLMv2 | LayoutLMv2-base | SER | 85.44% |
| VI-LayoutXLM | VI-LayoutXLM-base | RE | 83.92% |
| LayoutXLM | LayoutXLM-base | RE | 74.83% |
| LayoutLMv2 | LayoutLMv2-base | RE | 67.77% |
3.1 KIE模型介绍
对于识别得到的文字进行关键信息抽取,有2种主要的方法。
(1)直接使用SER,获取关键信息的类别:如身份证场景中,将“姓名“与”张三“分别标记为name_key与name_value。最终识别得到的类别为name_value对应的文本字段即为我们所需要的关键信息。
(2)联合SER与RE进行使用:这种方法中,首先使用SER,获取图像文字内容中所有的key与value,然后使用RE方法,对所有的key与value进行配对,找到映射关系,从而完成关键信息的抽取。
3.2 关于XFUND数据集
XFUND数据集是微软提出的一个用于KIE任务的多语言数据集,它包含7种不同语种的表单数据,并且全部用人工进行了键-值对形式的标注。其中每个语种的数据都包含了199张表单数据,并分为149张训练集以及50张测试集。
下载地址:Release XFUND v1.0 · doc-analysis/XFUND 读者也可以在AI Studio的数据集中搜索到。其中文表单数据具体情况如下:
lang split header question answer other total ZH training 441 3,266 2,808 896 7,411 testing 122 1,077 821 312 2,332
查看该数据集的标注信息可以发现,类似姓名、出生日期、籍贯、地址等表单数据常见内容,该数据集都有涉及。
因此,直接使用基于PaddleOCR提供的、在XFUND_zh公开数据集上表现良好的VI-LayoutXLM部署模型,用于简历基本信息的抽取,看来有一定的可行性。
3.3 VI-LayoutXLM部署模型准备
VI-LayoutXLM基于LayoutXLM进行改进,在下游任务训练过程中,去除视觉骨干网络模块,最终精度基本无损的情况下,模型推理速度进一步提升。
在XFUND_zh数据集上,算法复现效果如下:
| 模型 | 骨干网络 | 任务 | 配置文件 | hmean | 下载链接 |
|---|---|---|---|---|---|
| VI-LayoutXLM | VI-LayoutXLM-base | SER | ser_vi_layoutxlm_xfund_zh_udml.yml | 93.19% | 训练模型/推理模型 |
| VI-LayoutXLM | VI-LayoutXLM-base | RE | re_vi_layoutxlm_xfund_zh_udml.yml | 83.92% | 训练模型/推理模型 |
!wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_infer.tar
!wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_infer.tar
--2023-01-29 17:43:26-- https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_infer.tar
正在解析主机 paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)... 182.61.200.229, 182.61.200.195, 2409:8c04:1001:1002:0:ff:b001:368a
正在连接 paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)|182.61.200.229|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度: 1133332480 (1.1G) [application/x-tar]
正在保存至: “re_vi_layoutxlm_xfund_infer.tar”re_vi_layoutxlm_xfu 100%[===================>] 1.05G 36.7MB/s in 31s 2023-01-29 17:43:57 (35.3 MB/s) - 已保存 “re_vi_layoutxlm_xfund_infer.tar” [1133332480/1133332480])
!tar -xvf re_vi_layoutxlm_xfund_infer.tar -C ./PaddleOCR/
re_vi_layoutxlm_xfund_infer/
re_vi_layoutxlm_xfund_infer/inference.pdmodel
re_vi_layoutxlm_xfund_infer/inference.pdiparams
re_vi_layoutxlm_xfund_infer/inference.pdiparams.info
!tar -xvf ser_vi_layoutxlm_xfund_infer.tar -C ./PaddleOCR/
ser_vi_layoutxlm_xfund_infer/
ser_vi_layoutxlm_xfund_infer/inference.pdiparams.info
ser_vi_layoutxlm_xfund_infer/inference.pdiparams
ser_vi_layoutxlm_xfund_infer/inference.pdmodel
# 准备XFUND数据集,这里主要是为了获得字典文件class_list_xfun.txt
!mkdir ./PaddleOCR/train_data
!wget https://paddleocr.bj.bcebos.com/ppstructure/dataset/XFUND.tar
!tar -xf XFUND.tar -C ./PaddleOCR/train_data/
--2023-01-29 16:40:29-- https://paddleocr.bj.bcebos.com/ppstructure/dataset/XFUND.tar
Resolving paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)... 182.61.200.229, 182.61.200.195, 2409:8c04:1001:1002:0:ff:b001:368a
Connecting to paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)|182.61.200.229|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 266224297 (254M) [application/x-tar]
Saving to: ‘XFUND.tar’XFUND.tar 100%[===================>] 253.89M 36.2MB/s in 7.5s 2023-01-29 16:40:36 (33.7 MB/s) - ‘XFUND.tar’ saved [266224297/266224297]
3.4 VI-LayoutXLM预测效果分析
%cd PaddleOCR/ppstructure
/home/aistudio/PaddleOCR/ppstructure
SER预测效果:基本上所有key和value都能识别出来,但是question/answer的判定有的地方还不够准确。
!python kie/predict_kie_token_ser.py \--kie_algorithm=LayoutXLM \--ser_model_dir=../ser_vi_layoutxlm_xfund_infer \--image_dir=../../temp.jpeg \--ser_dict_path=../train_data/XFUND/class_list_xfun.txt \--vis_font_path=../doc/fonts/simfang.ttf \--ocr_order_method="tb-yx"
[32m[2023-01-30 12:13:21,226] [ INFO][0m - Already cached /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/sentencepiece.bpe.model[0m
[32m[2023-01-30 12:13:21,806] [ INFO][0m - tokenizer config file saved in /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/tokenizer_config.json[0m
[32m[2023-01-30 12:13:21,807] [ INFO][0m - Special tokens file saved in /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/special_tokens_map.json[0m
[2023/01/30 12:13:27] ppocr INFO: save vis result to ./output/temp.jpeg
[2023/01/30 12:13:27] ppocr INFO: Predict time of ../../temp.jpeg: 0.029108285903930664

SER + RE预测效果,显然输出的信息在key-value的匹配上还需要进行一些调整,对照的信息错误较多。
!python kie/predict_kie_token_ser_re.py \--kie_algorithm=LayoutXLM \--re_model_dir=../re_vi_layoutxlm_xfund_infer \--ser_model_dir=../ser_vi_layoutxlm_xfund_infer \--use_visual_backbone=False \--image_dir=../../temp.jpeg \--ser_dict_path=../train_data/XFUND/class_list_xfun.txt \--vis_font_path=../doc/fonts/simfang.ttf \--ocr_order_method="tb-yx"
[32m[2023-01-29 17:45:21,766] [ INFO][0m - Already cached /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/sentencepiece.bpe.model[0m
[32m[2023-01-29 17:45:22,463] [ INFO][0m - tokenizer config file saved in /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/tokenizer_config.json[0m
[32m[2023-01-29 17:45:22,464] [ INFO][0m - Special tokens file saved in /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/special_tokens_map.json[0m
[2023/01/29 17:45:33] ppocr INFO: save vis result to ./output/temp_ser_re.jpg
[2023/01/29 17:45:33] ppocr INFO: Predict time of ../../temp.jpeg: 2.472132444381714
[0m
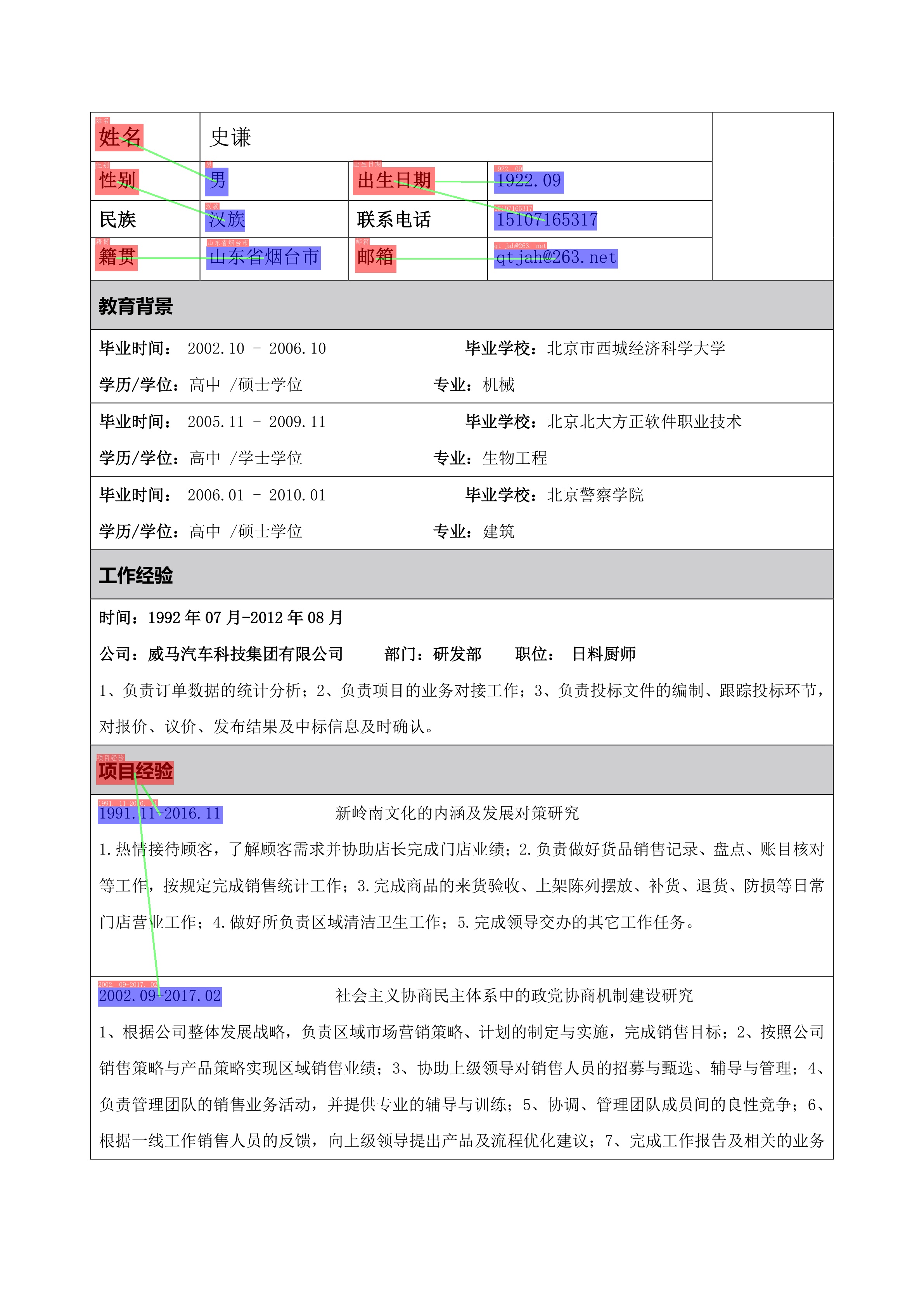
从测试简历图片的的关键信息抽取效果看,SER整体还是可以的,但SER + RE差距就比较大了。
其实也不难理解,因为尽管XFUND是典型的表单数据集,但是训练数据也就百余张图片,标注内容与我们在简历中需要提取的关键信息也不完全一致。
接下来,自然就出现了两种优化方法:
- 提取SER输出的文本信息,组合后回到PaddleNLP.Taskflow中,进行关键信息抽取
- 重新标注数据,进行SER+RE微调
本项目中,我们先采用第一种优化方法,快速提取简历关键信息。
也许读者还有些疑问,前置项目简历信息提取(二):HR救星!用UIE Taskflow快速完成简历信息批量抽取中,最后一种处理方式不就是OCR + NLP么,第一种优化方法,本质上也是OCR + NLP,折腾了一圈,有什么不同?
那是因为,VI-LayoutXLM SER,基于与简历文件形式特别接近的表单数据集重新进行了微调,在版面分析上的效果,与OCR的默认文本检测模型相比,还是有比较大提升的。这对于准备输入Taskflow API的文本而言,提升是很明显的。
4 SER + Taskflow简历批量信息抽取
4.1 SER输出结果的文本拼接
SER预测结果默认保存到输出文件目录的infer.txt文件中,从代码最小改造的角度看,既然这个文件已经包括了我们想要的文本信息,就把输出修改为纯json格式,再次读取该文件进行文本拼接即可。
!cp ~/predict_kie_token_ser_1.py kie/predict_kie_token_ser.py
PaddleOCR/ppstructure/kie/predict_kie_token_ser.py关键代码调整:
res_str = '{}\n'.format(json.dumps({"ocr_info": ser_res,}, ensure_ascii=False))
f_w.write(res_str)
!python kie/predict_kie_token_ser.py \--kie_algorithm=LayoutXLM \--ser_model_dir=../ser_vi_layoutxlm_xfund_infer \--image_dir=../../temp.jpeg \--ser_dict_path=../train_data/XFUND/class_list_xfun.txt \--vis_font_path=../doc/fonts/simfang.ttf \--ocr_order_method="tb-yx"
[2023-01-30 14:54:38,632] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/sentencepiece.bpe.model
[2023-01-30 14:54:39,326] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/tokenizer_config.json
[2023-01-30 14:54:39,327] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/special_tokens_map.json
[2023/01/30 14:54:45] ppocr INFO: save vis result to ./output/temp.jpeg
[2023/01/30 14:54:45] ppocr INFO: Predict time of ../../temp.jpeg: 0.029132604598999023
with open('./output/infer.txt') as f:data = json.load(f)
res = []
for i in range(len(data['ocr_info'])):res.append(data['ocr_info'][i]['transcription'])
# 拼接时不要添加分隔符,taskflow会自动分词
res = ''.join(res)
from pprint import pprint
from paddlenlp import Taskflow
# 选定一些HR关注的基本信息
schema = ['姓名', '出生日期', '电话', '性别', '最高学历', '籍贯', '政治面貌', '毕业院校', '学位', '毕业时间', '工作时间']
ie = Taskflow('information_extraction', schema=schema)
[2023-01-30 14:55:21,972] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base'.
pprint(ie(res))
[{'出生日期': [{'end': 19,'probability': 0.9952766075540538,'start': 11,'text': '1922. 09'}],'姓名': [{'end': 4, 'probability': 0.99853872245383, 'start': 2, 'text': '史谦'}],'学位': [{'end': 115,'probability': 0.507645663226608,'start': 110,'text': '高中/硕士'}],'工作时间': [{'end': 256,'probability': 0.46099927334273616,'start': 239,'text': '1992年07月-2012年08月'},{'end': 537,'probability': 0.47518266090926886,'start': 520,'text': '2002. 09-2017. 02'}],'性别': [{'end': 7,'probability': 0.9323432009985488,'start': 6,'text': '男'}],'毕业时间': [{'end': 88,'probability': 0.5018500184772172,'start': 72,'text': '2002.10- 2006.10'}],'毕业院校': [{'end': 104,'probability': 0.585296516651681,'start': 93,'text': '北京市西城经济科学大学'}],'电话': [{'end': 38,'probability': 0.8479164555647429,'start': 27,'text': '15107165317'}],'籍贯': [{'end': 46,'probability': 0.805421910140236,'start': 40,'text': '山东省烟台市'}]}]
4.2 批量信息抽取实现
下面我们把整个批量抽取过程串起来。首先是准备图片格式的简历文件。
4.2.1 图片格式简历文件准备
%cd ~
/home/aistudio
def get_pic_info(path):# 将整理后的抽取结果返回为字典if os.path.splitext(path)[-1]=='.pdf':pdfDoc = fitz.open(path)for pg in range(pdfDoc.page_count):page = pdfDoc[pg]rotate = int(0)zoom_x = 4 # (1.33333333-->1056x816) (2-->1584x1224)zoom_y = 4mat = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate)pix = page.get_pixmap(matrix=mat, alpha=False)# 保存过渡图片pix.save(path[:-4] + '_%s.jpeg' % pg)
def get_pics(path):filenames = os.listdir(path)result = []for filename in tqdm(filenames):get_pic_info(os.path.join(path,filename))
# 将简历文档转换为图片格式
result = get_pics('resume_train_20200121/pdf')
!mkdir 'resume_train_20200121/imgs'
!mv resume_train_20200121/pdf/*.jpeg resume_train_20200121/imgs/
4.2.2 批量信息提取
这里要对原有的推理脚本做比较大幅度的变更,关键代码如下:
with open(os.path.join(args.output, 'infer.txt'), mode='w',encoding='utf-8') as f_w:pre_img_name = ''res = []for image_file in image_file_list:img, flag, _ = check_and_read(image_file)if not flag:img = cv2.imread(image_file)img = img[:, :, ::-1]if img is None:logger.info("error in loading image:{}".format(image_file))continueser_res, _, elapse = ser_predictor(img)ser_res = ser_res[0]# 如果是同一份简历,不换行,反之,换行if os.path.split(image_file)[1][:-7] == pre_img_name:for item in ser_res:res.append(item['transcription'])res1 = ''.join(res) res_str = '{}'.format(res1, ensure_ascii=False)else:res = []for item in ser_res:res.append(item['transcription'])res1 = ''.join(res)res_str = '{}\n'.format(res1, ensure_ascii=False)f_w.write(res_str)# 记录图片文件名,用于后续比较是否同一份简历pre_img_name = os.path.split(image_file)[1][:-7]# 为节省推理时间,绘图部分可以略去# img_res = draw_ser_results(# image_file,# ser_res,# font_path=args.vis_font_path, )# img_save_path = os.path.join(args.output,# os.path.basename(image_file))# cv2.imwrite(img_save_path, img_res)# logger.info("save vis result to {}".format(img_save_path))# if count > 0:# total_time += elapse# count += 1# logger.info("Predict time of {}: {}".format(image_file, elapse))
%cd PaddleOCR/ppstructure
/home/aistudio/PaddleOCR/ppstructure
!cp ~/predict_kie_token_ser_2.py kie/predict_kie_token_ser.py
!python kie/predict_kie_token_ser.py \--kie_algorithm=LayoutXLM \--ser_model_dir=../ser_vi_layoutxlm_xfund_infer \--use_visual_backbone=False \--image_dir=/home/aistudio/resume_train_20200121/imgs/ \--ser_dict_path=../train_data/XFUND/class_list_xfun.txt \--vis_font_path=../doc/fonts/simfang.ttf \--ocr_order_method="tb-yx"
[2023-01-30 15:44:23,565] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/sentencepiece.bpe.model
[2023-01-30 15:44:24,226] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/tokenizer_config.json
[2023-01-30 15:44:24,227] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/layoutxlm-base-uncased/special_tokens_map.json
from pprint import pprint
from paddlenlp import Taskflow
# 选定一些HR关注的基本信息
schema = ['姓名', '出生日期', '电话', '性别', '最高学历', '籍贯', '政治面貌', '毕业院校', '学位', '毕业时间', '工作时间']
ie = Taskflow('information_extraction', schema=schema)
with open('./output/infer.txt') as f:result = []# Get next line from filefor line in tqdm(f.readlines()):schema_dict = {}a = ie(line)for i in schema:if i in a[0]:schema_dict[i] = a[0][i][0]['text']# 查看抽取信息# print(a[0][i][0]['text'])else:schema_dict[i] = ''result.append(schema_dict)
100%|██████████| 111/111 [02:18<00:00, 1.25s/it]schema_dict[i] = ''result.append(schema_dict)
100%|██████████| 111/111 [02:18<00:00, 1.25s/it]```python
result_pd = pd.DataFrame(result)
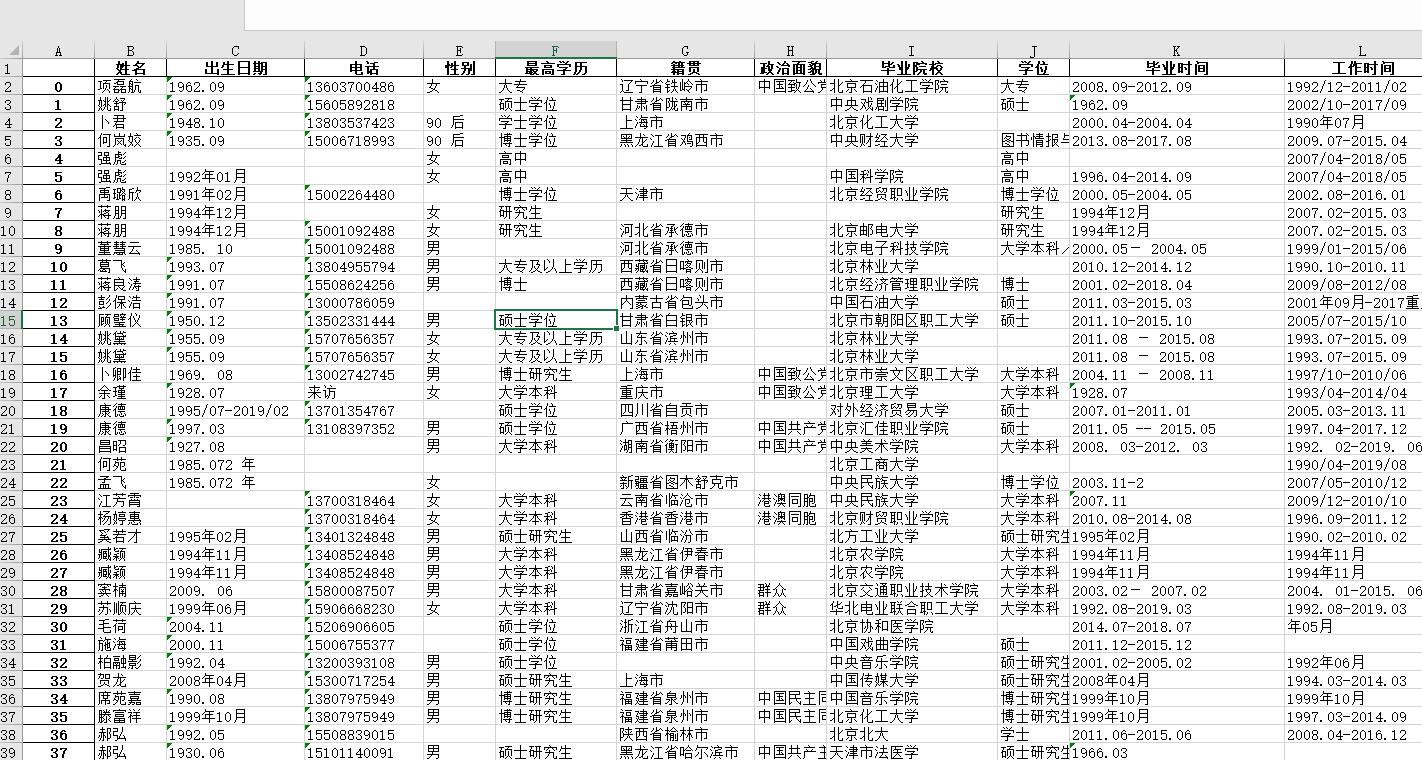
result_pd.head()
| 姓名 | 出生日期 | 电话 | 性别 | 最高学历 | 籍贯 | 政治面貌 | 毕业院校 | 学位 | 毕业时间 | 工作时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 项磊航 | 1962.09 | 13603700486 | 女 | 大专 | 辽宁省铁岭市 | 中国致公党 | 北京石油化工学院 | 大专 | 2008.09-2012.09 | 1992/12-2011/02 |
| 1 | 姚舒 | 1962.09 | 15605892818 | 硕士学位 | 甘肃省陇南市 | 中央戏剧学院 | 硕士 | 1962.09 | 2002/10-2017/09 | ||
| 2 | 卜君 | 1948.10 | 13803537423 | 90 后 | 学士学位 | 上海市 | 北京化工大学 | 2000.04-2004.04 | 1990年07月 | ||
| 3 | 何岚姣 | 1935.09 | 15006718993 | 90 后 | 博士学位 | 黑龙江省鸡西市 | 中央财经大学 | 图书情报与档案管理 | 2013.08-2017.08 | 2009.07-2015.04 | |
| 4 | 强彪 | 女 | 高中 | 高中 | 2007/04-2018/05 |
result_pd.to_excel('简历信息.xlsx')
可以发现,简历信息抽取的完整程度,与同样只用预训练模型的前置项目简历信息提取(二):HR救星!用UIE Taskflow快速完成简历信息批量抽取相比,已经提高了不少。
4 小结
在本项目中,我们使用PaddleOCR提供的VI-LayoutXLM预训练模型,结合PaddleNLP Taskflow API,进一步提升了图片格式的简历文件批量信息提取的效果。
我们发现,引入版面分析技术后,图片格式简历文件内容提取文本的完整性、连贯性都有大幅提升,而且不像word文档提取结果,有大量的多余文字干扰。从而提升了下游实体识别的效果。接下来我们将基于这些处理后的文本内容进行模型微调,进一步提升简历关键信息抽取效果。