济南做网站最好的公司/什么叫做关键词

python爬虫——爬取百度百科简介
写在前面的话
首先呢,这是本文作者第一次发关于技术的文章,如有不足还请大家指出。
另外,我们这一次使用的 IDE(集成开发环境)是 PyCharm,其他的还请大家自行研究了。
任务简介
利用 python 爬取百度百科的任何一个词条的简介,在本文中我们将了解爬虫的几个库的基本使用方法,例如 bs4 (BeautifulSoup),requests 等等,可以这么说,学完这一篇文章,你就可以爬取一些静态网页的东西了,是不是很兴奋呢,那就让我们赶快开始吧!(在这里我提醒一下各位,最好还是要自己手敲哦!)
开始正文
首先呢,大家需要引进几个库:
from bs4 import BeautifulSoupimport requestsimport osfrom time import sleepps.有些库属于第三方库,需要用pip安装哦:
pip install 安装库的名字各位不知道成功了没有呢,让我们继续吧!
好的,咱们先打开百度百科的首页,随便搜一个关键词,看一看上边的网址有什么变化呢?

一个还看不出来,咱们再搜一个:

看见木有上面的那个网址!!!除了我画黄的部分和后面的那一串字符跟上面不一样其余的都一样!!!那你可能就会说了,那我怎么可能会知道后面的那一串字符是什么呀,这可怎么办呢?如果光输入关键词就可以查询该多好呀!行,既然想了,那咱们就试试:

没错,我没有写后面的东西,咱们看下结果:
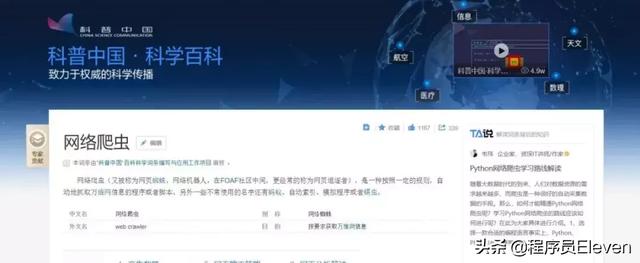
不可思议!竟然成功了!那接下来的事情就好办了
我们就可以使用字符串拼接功能把前面的
“https://baike.baidu.com/item/”
和用户输入的内容组成在一起,代码如下:
url = ‘https://baike.baidu.com/item/’ + input(‘请输入您要查询的关键词’)下面就是最最重要的一个步骤——添加头部信息
我们都知道,既然有爬虫,那就必定有反爬虫,普通的反爬虫一般都是通过辨别头部信息来进行反爬,如果你不伪装一下的话,就相当于明目张胆地告诉反爬虫系统:我是爬虫!你们来抓我呀!!
所以只有把自己的头部信息给伪装一下,让反爬系统认为:哦!你原来就是一个普通的浏览器。才行,代码如下:
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'}#我们使用的头部信息(防止反爬虫阻碍我们搞事情)接下来就是最激动人心的时刻了,我们的 requests 要登场了!
在我们的这个小程序里面,requests 的主要任务是帮我们 get 一下网页的源代码,话不多说,代码放出:
url_get = requests.get(url,headers = header)上面我们调用了两个变量:
1.url(就是保存网址的)
2.header(就是保存头部信息的,把他的内容给了一个叫做 headers 的参数,很晕,是不?)
好了这时候咱们 print 一下 url_get(哦,对了,这里说一下哈,如果想查看源代码的话,需要在 print 的括号里面填上 .text )
好,给大家看一下结果:

WHAT!!!怎么可能会是这样!就算源代码再丑也不可能是这些奇奇怪怪的???

就这样,这个项目就因为这个 bug 被搁置了,后来。。。。我正在逛 CSDN,忽然看见了解决方法,于是又把这个项目捡起来了呵呵呵。原来,在网页源代码的第8行里,它的编码竟然是utf-8!

按照 CSDN 大神的指示,应该把 utf-8 的编码换成 gb2312
行,听你的,我换!代码如下:
url_decode = url_get.content.decode(“utf-8″,”ignore”).encode(“gb2312″,”ignore”) #utf-8为网页编码,把它转换成gb2312另外,我们也接着设置一下解析器:
url_soup = BeautifulSoup(url_decode,’html.parser’)好啦!!!咱们 print 一下,看是不是真正的弄好了呢?

啊,哈哈哈哈哈哈哈哈,总算把编码问题搞定了,下面开始进行数据清理!
数据清理,数据清理,顾名思义就是要把不要的东西剔除掉,那怎么剔除呢?
其实非常简单(不过要深入的话还是比较难的)
咱们先来看一下获取到的源代码,里面的东西那么多,但其实我们只需要下面这一行的内容:

所以我们就可以运用到find这个功能,看代码:
url_meta = url_soup.find(‘meta’, attrs={‘name’:’description’})这句话的意思就是从源代码中找出一个带有meta标签的东西,并且还还有一个属性叫做 name,他的参数是 description
好啦,到此为止,我们的核心代码部分就完成啦,相信聪明的你肯定能猜到接下来要干什么啦,那当然就是:
print(url_meta)
哈哈哈哈,运行成功!前头突发奇想弄了段奇葩代码,嘻嘻!
本文中所有的源代码:
from bs4 import BeautifulSoupimport requestsimport osfrom time import sleep#温馨提示print('由于技术原因,有一点障碍没有突破,还请各位多多谅解(本人在最后放了一个彩蛋,你们可以去看一看哦!)')sleep(1)#来一段逗X程序print('欢迎使用全国最大的百科网站,百度百科的检索工具,您可以输入任何的词语,我们的服务器都会在最快的时间内帮您找到他的解释')print('程序正在自检........')sleep(2)print('滴!程序自检成功,正在装载至内存,可能需要1~2秒钟,请稍等................')sleep(1)print('程序装载成功,已开启')#好,开始说正事url = 'https://baike.baidu.com/item/' + input('请输入您要查询的关键词')header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'}#我们使用的头部信息(防止反爬虫阻碍我们搞事情)url_get = requests.get(url,headers = header)url_decode = url_get.content.decode("utf-8