青岛做网站好的公司/水果网络营销推广方案
目录
- 1、什么是自注意力self-attention?
- 2、Transformer为什么需要进行Multi-head Attention?
- 3、self-attention为什么要使用Q、K、V?
- 3、为什么Q、K、V代表了注意力?
- 4、Q、K、V是怎么得到的
- 5、多头是什么意思?
- 6、Transformer在训练什么?
- 7、Q、K矩阵相乘为什么最后要除以√dk?
- 8、Transformer如何实现并行化?
- 9、transformer的位置编码如何表达位置?
- 10、transformer的位置编码为什么使用三角函数?
- 参考文献
这篇博文主要结合个人理解和思考,通过整理和自己的解释列出关于Transformer的部分重要问题(持续更新),看完后会对Transformer有个更好的理解。
如果没有接触过Transformer,我建议你先看一下:深入浅出理解Transformer及其pytorch源码(零基础理解为什么是Transformer?什么是Transformer?)
1、什么是自注意力self-attention?
自注意力机制,是一种通过自身和自身相关联的attention机制,从而得到一个更好的 representation 来表达自身。
不严谨的说,自注意力机制就是利用 xix_ixi 之间两两相关性作为权重的一种加权平均将每一个 xix_ixi映射到 ziz_izi,比如 x1x_1x1和x2x_2x2表示“Thinking”和“Machines”的embedding。此时可以说x1x_1x1和x2x_2x2都只表示自己的word,没有考虑局部依赖关系。自注意力机制首先计算了 x1x_1x1与x1x_1x1、x1x_1x1和x2x_2x2之间的相关性,记为 α1α_1α1和α2α_2α2, z1=α1∗x1+α2∗x2z_1= α_1*x_1+α_2*x_2z1=α1∗x1+α2∗x2 ,通过这样加权平均方式得到的z1z_1z1 来表示“Thinking”。
2、Transformer为什么需要进行Multi-head Attention?
引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,Multi-head Attention是多层次的self-attention,多头的注意力有助于网络捕捉到更丰富的特征/信息(类比 CNN 中同时使用多个卷积核)。
在self-attention中,Q=K=V,序列中的每个单词(token)和该序列中其余单词(token)进行attention计算。self-attention的特点在于无视词(token)之间的距离直接计算依赖关系,从而能够学习到序列的内部结构,实现起来也比较简单
3、self-attention为什么要使用Q、K、V?
Query,Key,Value的概念取自于信息检索系统,Q表示的就是与我这个单词相匹配的单词的属性,K就表示我这个单词的本身的属性,V表示的是我这个单词的包含的信息本身。
Attention机制中的Q,K,V即是,我们对当前的Query和所有的Key计算相似度,将这个相似度值通过Softmax层进行得到一组权重,根据这组权重与对应Value的乘积求和得到Attention下的Value值。
实验发现self-attention使用Q、K、V,这样三个参数独立,模型的表达能力和灵活性很好。
3、为什么Q、K、V代表了注意力?
V是表示输入特征的向量,Q、K是计算Attention权重的特征向量。它们都是由输入特征得到的。Attention(Q,K,V)是根据关注程度对V乘以相应权重
你有一个问题Q,然后去搜索引擎里面搜,搜索引擎里面有好多文章,每个文章V有一个能代表其正文内容的标题K,然后搜索引擎用你的问题Q和那些文章V的标题K进行一个匹配,看看相关度(QK —>attention值),然后你想用这些检索到的不同相关度的文章V来表示你的问题,就用这些相关度将检索的文章V做一个加权和,那么你就得到了一个新的Q’,这个Q’融合了相关性强的文章V更多信息,而融合了相关性弱的文章V较少的信息。这就是注意力机制,注意力度不同,重点关注(权值大)与你想要的东西相关性强的部分,稍微关注(权值小)相关性弱的部分。
4、Q、K、V是怎么得到的
Q、K、V都源于输入特征本身,是根据输入特征产生的向量。
举个例子:当我们打游戏出现打野来上被他反杀这种现象时,我们的第一反应是:在self-attention中,我们能否通过语言理解去做到,这个他指的是上单还是打野?
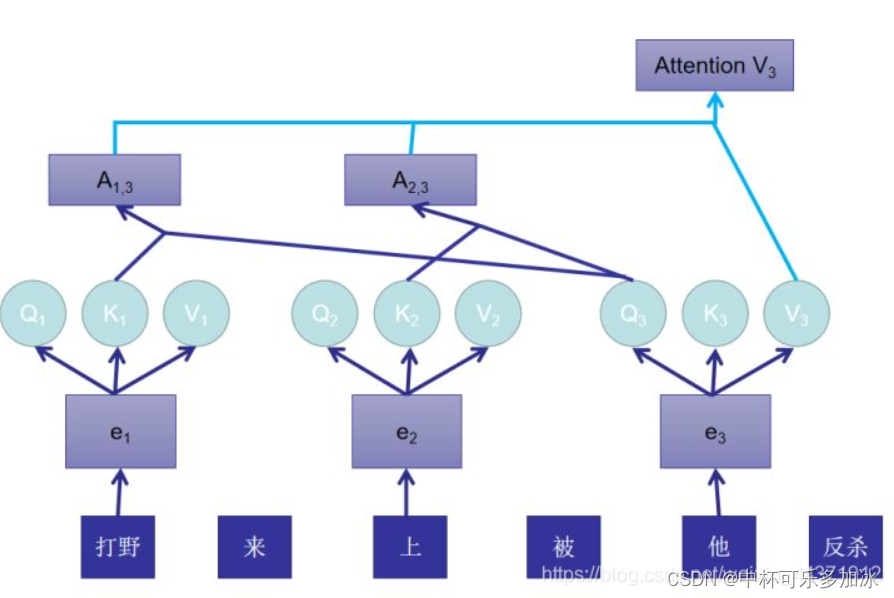
那么在Self-Attention中的做法是:
1、根据这个句子得到打野、上、他的embedding,在下图表示为e1,e2,e3。
2、将e通过不同的线性变换形成Q、K、V,他们都只是我们原本的序列e做了不同的线性变换之后的结果,都可以作为X的代表。
3、根据Q3分别与K1、K2做运算,计算相似程度即Attention值。得到A13A_{13}A13、A23A_{23}A23
4、AttentionV3AttentionV_3AttentionV3=(A13A_{13}A13+A23A_{23}A23+1)×V3V_3V3,AttentionV3V_3V3向量中就包含了:他更可能指代上单,而不是打野。
下面是另一种理解:
下图是self-attention过程:若需要计算a2的注意力,首先将q2与所有k(包括自己的)相乘,然后得到权重α,权重算softmax后去乘以所有的v,加起来得到最终的b。
其实这图横过来看可以看成神经网络,而q与k相乘就是算权重,输入为a2,输出为b2。
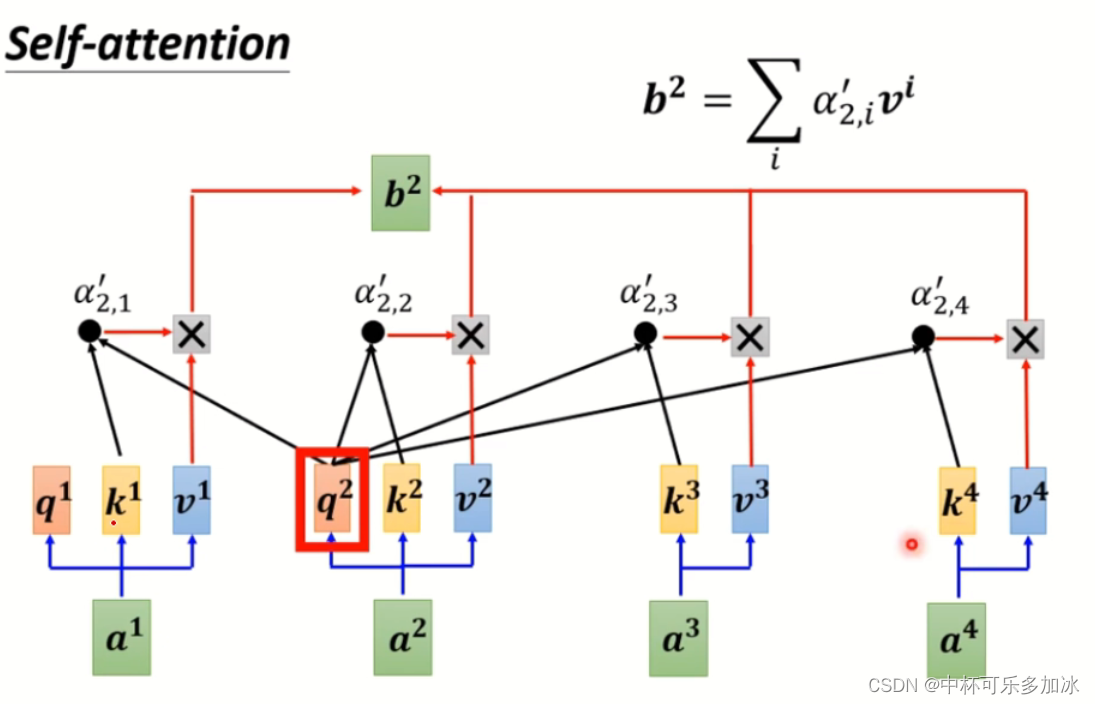
但是简单将单词编码成a的话,会缺失一个位置信息,导致每个a之间相当,于是便加入了positional encoding。
5、多头是什么意思?
在4中我们说到,e通过不同的线性变换形成Q、K、V,一个注意力头就是说一套线性变换的矩阵( WQW^QWQ、WKW^KWK、WVW^VWV),多个注意力头就是多套线性变换( W0QW_0^QW0Q、W0KW_0^KW0K、W0VW_0^VW0V)、( W1QW_1^QW1Q、W1KW_1^KW1K、W1VW_1^VW1V)、( W2QW_2^QW2Q、W2KW_2^KW2K、W2VW_2^VW2V)…了,多套之间线性变换的参数W是不一样的,对于输入矩阵X,每一套Q、K、V都可以得到一个输出矩阵Z,最后将他们拼接起来就好了。
多头类似于CNN的多个卷积核。通过三个线性层的映射,不同头中的Q、K、V是不一样的,而这三个线性层的权重是先初始化后续通过学习得到的。不同的权重可以捕捉到序列中不同的相关性。
多头自注意力层的作用是将原始文本序列信息做整合,转换后的文本序列中每个字符都与整个文本序列的信息相关(这也是Transformer中最创新的思想,尽管根据最新的综述研究表明,Transformer的效果非常好其实多头自注意力层并不占据绝大贡献)。
6、Transformer在训练什么?
个人理解Transformer在训练时就是不断的在优化自己的多头注意力层,不断调整输入与输出之间的隐层特征,调整Q、K、V的权重矩阵,使其能够学习到两种语言(如德语到英语,也不仅限于NLP)的复杂映射关系。
7、Q、K矩阵相乘为什么最后要除以√dk?
当 √dk 特别小的时候,其实除不除无所谓。无论编码器还是解码器Q、K矩阵其实本质是一个相同的矩阵。Q、K相乘其实相等于Q乘以Q的转置,这样造成结果会很大或者很小。小了还好说,大的话会使得后续做softmax继续被放大造成梯度消失,不利于梯度反向传播。
8、Transformer如何实现并行化?
Transformer之所以能支持Decoder部分并行化训练,是基于以下两个关键点:
①、teacher force
对于teacher force,是指在每一轮预测时,不使用上一轮预测的输出,而强制使用正确的单词,过这样的方法可以有效的避免因中间预测错误而对后续序列的预测,从而加快训练速度,而Transformer采用这个方法,为并行化训练提供了可能,因为每个时刻的输入不再依赖上一时刻的输出,而是依赖正确的样本,而正确的样本在训练集中已经全量提供了。值得注意的一点是:Decoder的并行化仅在训练阶段,在测试阶段,因为我们没有正确的目标语句,t时刻的输入必然依赖t-1时刻的输出,这时跟之前的seq2seq就没什么区别了。
②、masked self attention
我们在5里说到,多头注意力意味着多组KQV进行self-attention运算,不同于LSTM中的一步步的按部就班的运算,而是KQV的运算可以是同时计算的(这是因为每QKV的线性变换不同,计算互不影响)
注意transformer的运算复杂度,乘法运算不一定比LSTM少,但因为可以进行同步运算,因而可以依靠硬件加速。
multi-head attention 是每一个head都进行了KQV生成以及attention的计算,这些计算是同步实现的,也就是并行实现的,因而可以同时获取不同空间的特征。
9、transformer的位置编码如何表达位置?
根据公式,第t个位置的位置编码为
pt→=[sin(ω1⋅t)cos(ω1⋅t)sin(ω2⋅t)cos(ω2⋅t)⋮sin(ωd/2⋅t)cos(ωd/2⋅t)]d×1\overrightarrow{p_{t}}=\left[\begin{array}{c} \sin \left(\omega_{1} \cdot t\right) \\ \cos \left(\omega_{1} \cdot t\right) \\ \sin \left(\omega_{2} \cdot t\right) \\ \cos \left(\omega_{2} \cdot t\right) \\ \vdots \\ \sin \left(\omega_{d / 2} \cdot t\right) \\ \cos \left(\omega_{d / 2} \cdot t\right) \end{array}\right]_{d \times 1}pt=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡sin(ω1⋅t)cos(ω1⋅t)sin(ω2⋅t)cos(ω2⋅t)⋮sin(ωd/2⋅t)cos(ωd/2⋅t)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤d×1
我们将所有位置(句子长度不超过50)和维度表示如下:
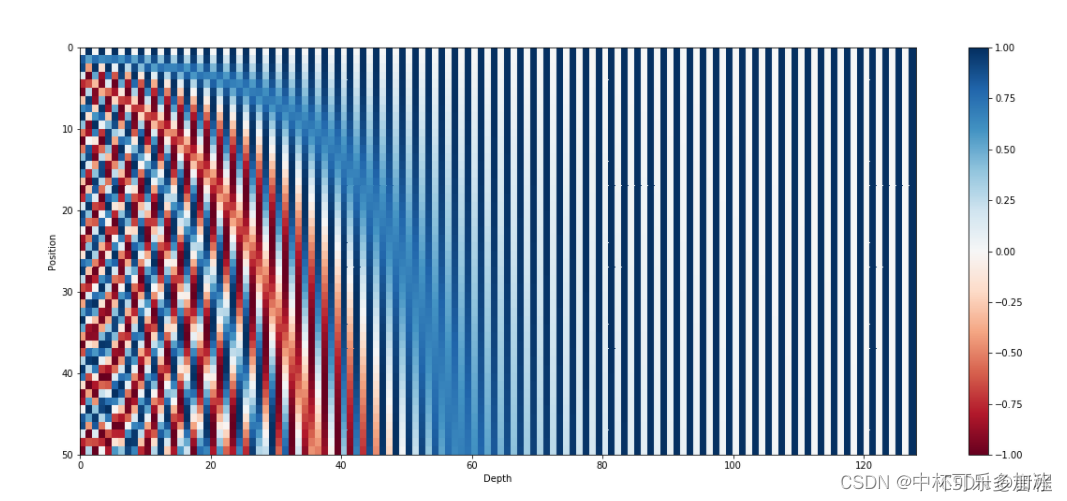
其中纵坐标为位置,横坐标为维度,每一行表示的是一个位置的编码信息,如第1行(图表从上往下数)代表的就是句子第一个词的位置信息。
显然,这个是绝对位置编码,即只要位置小于1万,每一个位置的编码都是不同的。
10、transformer的位置编码为什么使用三角函数?
三角函数的周期性能够很好的表示相对位置信息,给定k,存在一个固定的与k相关的线性变换矩阵,从而由pos的位置编码线性变换而得到pos+k的位置编码。(换一句话说:对于任何固定的偏移量k,ptp_tpt可以表示成pt+kp_{t+k}pt+k的线性函数。)且使用三角函数表达能使不同长度的句子之间,任何两个时间步之间的距离保持一致。
作为初学者,有些说法可能不太严谨,请大家指正。
有其他疑问请在评论区留言,你提出的问题将对作者和其他人提供很大帮助。
参考文献
1、通俗易懂:Attention中的Q、K、V是什么?怎么得到Q、K、V?
2、关于transformer的几个为什么
3、关于Transformer中常遇到的问题解答