上海企业招聘网/seo资讯推推蛙
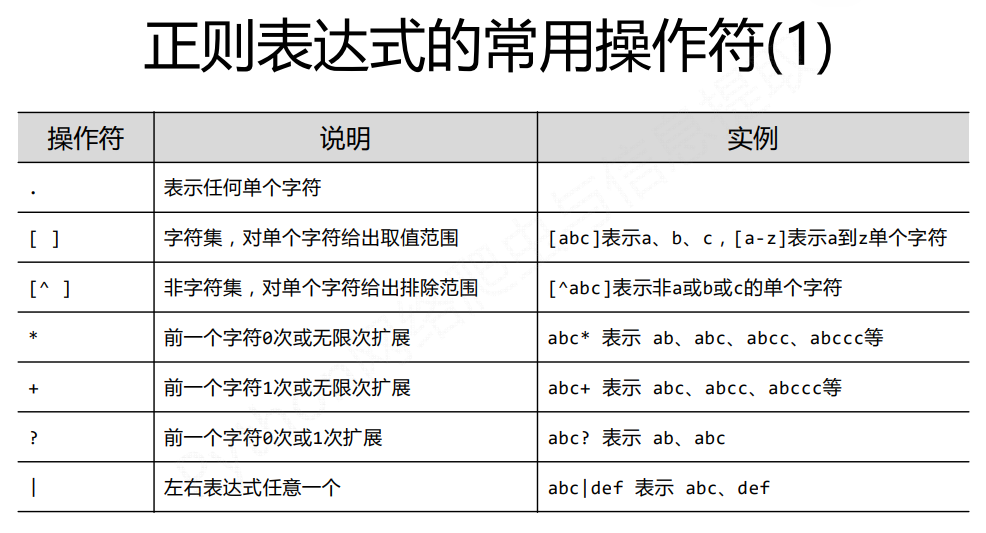
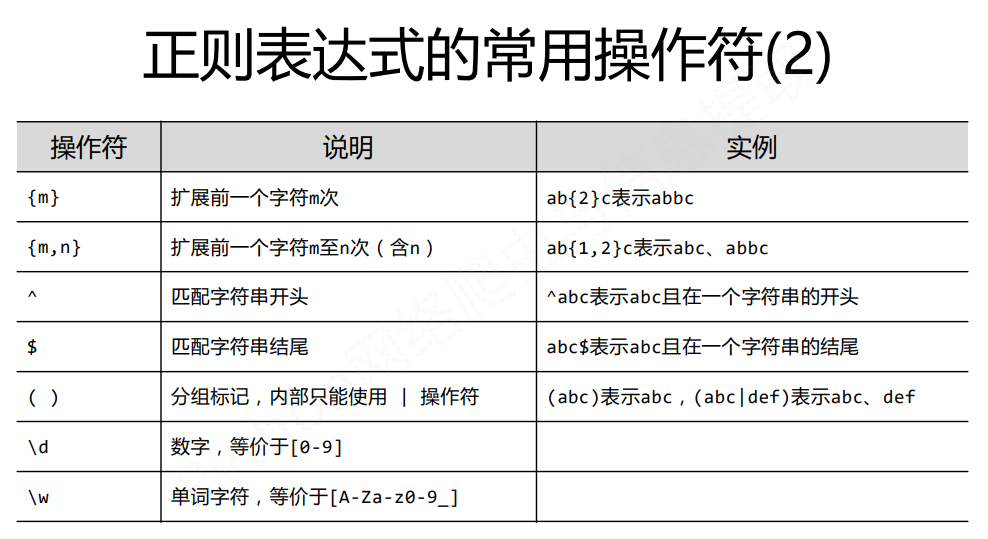
正则表达式的概念
什么是正则表达式?
正则表达式是用来简洁表达一组字符串的表达式
使用正则表达式的优势是什么?
简洁 一行胜前言 一行就是特征(模式)

正则表达式的语法
正则表达式语法由字符和操作符构成

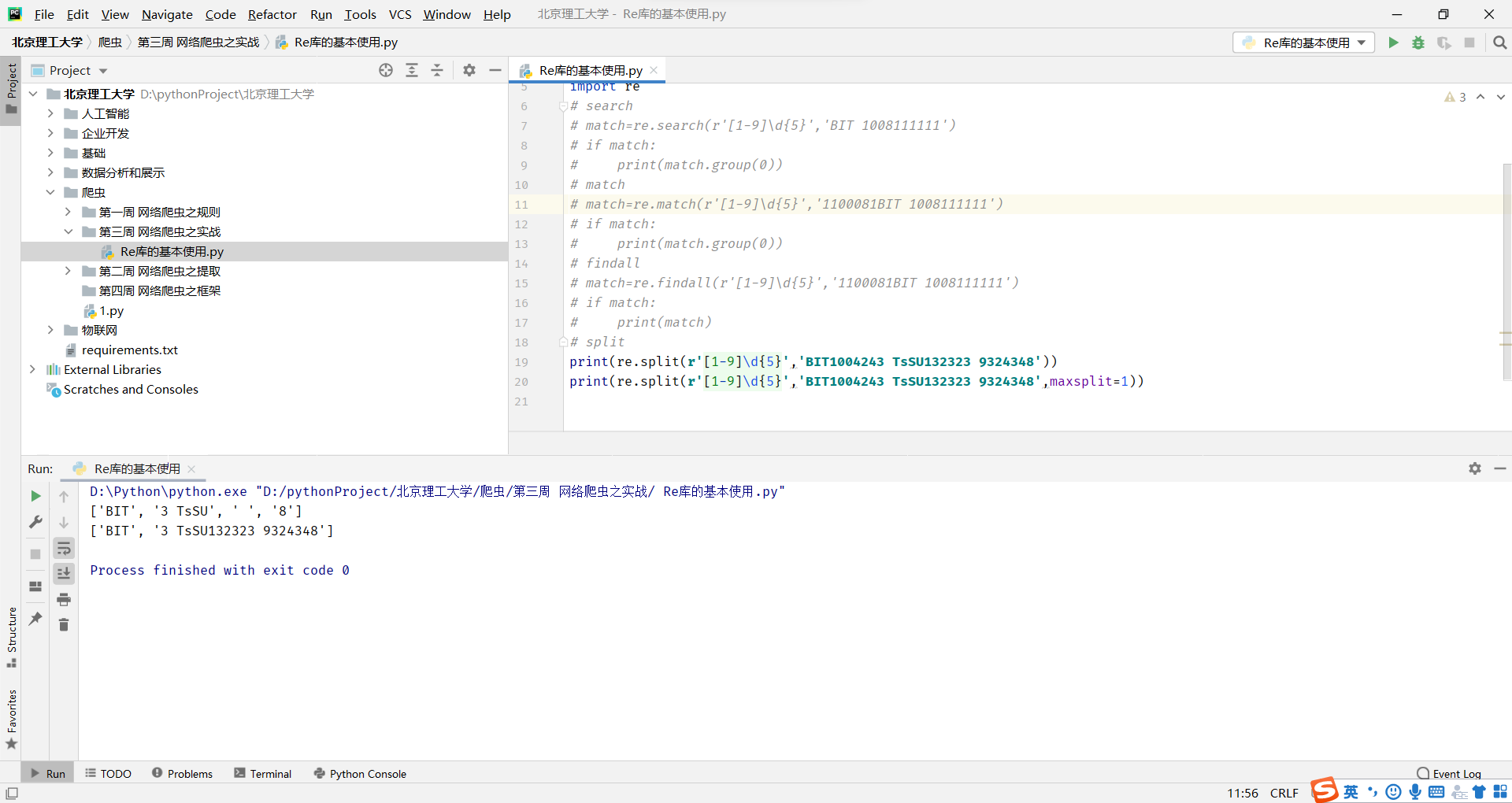
 Re库的基本使用
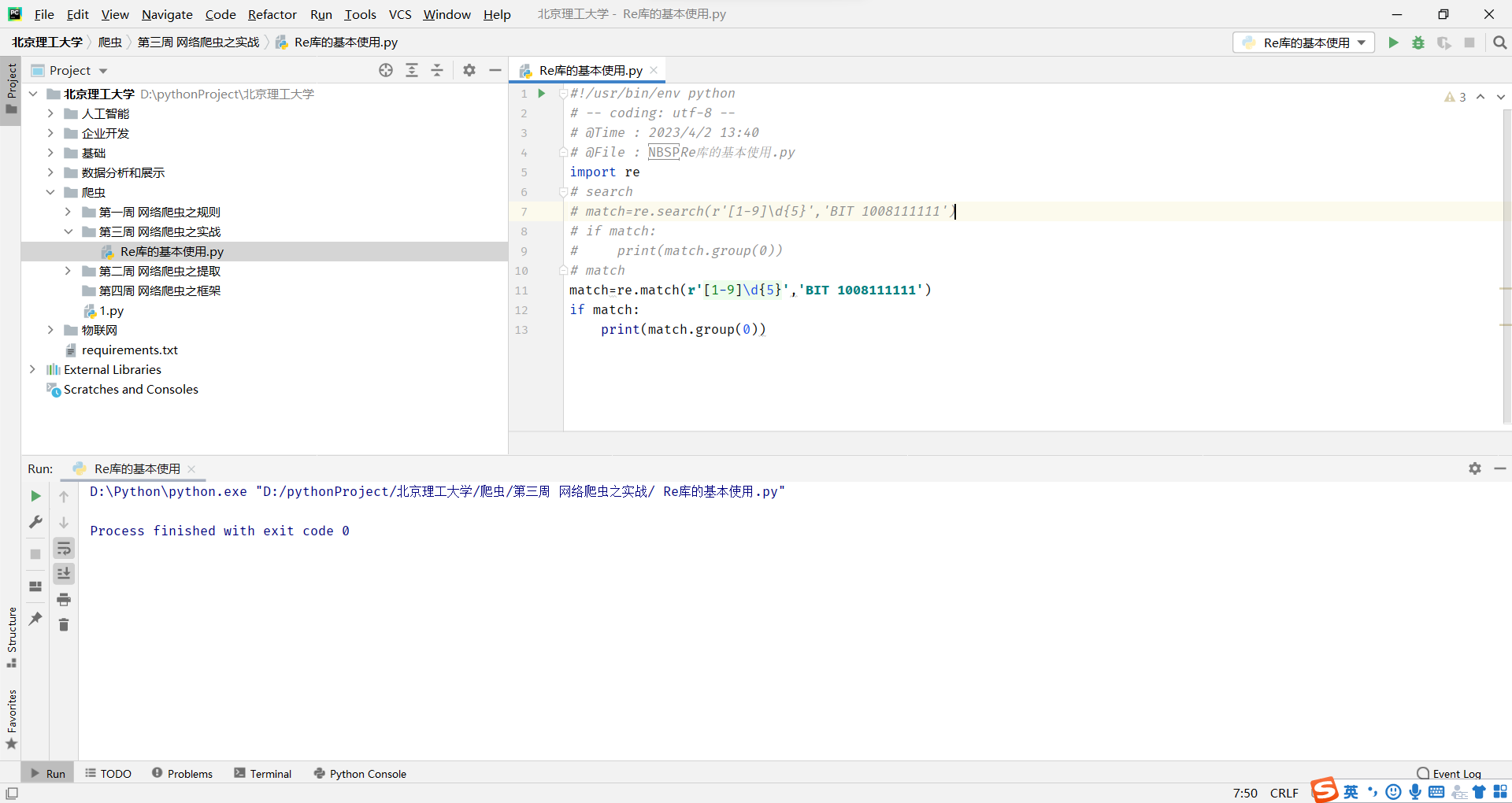
Re库的基本使用
Re库是Python的标准库,主要用于字符串匹配
调用方式:import re
 意思就是出现了转义符,普通的字符串需要\\n转义,而使用原生字符串就不需要,直接r'\n'
意思就是出现了转义符,普通的字符串需要\\n转义,而使用原生字符串就不需要,直接r'\n'
因此:当正则表达式包含转义符时,使用raw string






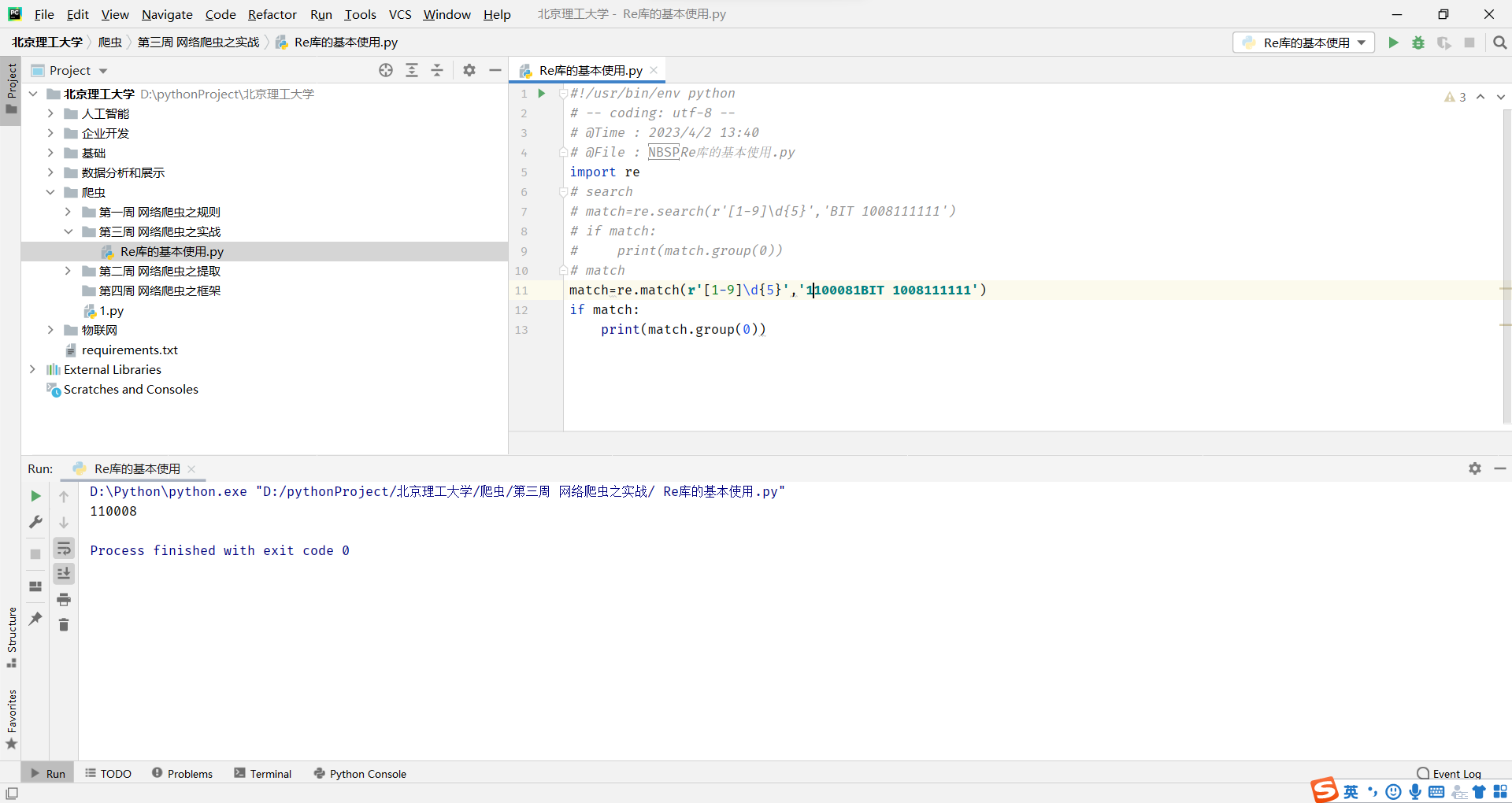 match和search的方法比较相似,都是在一个字符串s中寻找pat子字符串,如果能找到,就返回一个Match对象,如果找不到,就返回None。但是不同的是,mtach方法是从头开始匹配,而search方法,可以在s字符串的任一位置查找。
match和search的方法比较相似,都是在一个字符串s中寻找pat子字符串,如果能找到,就返回一个Match对象,如果找不到,就返回None。但是不同的是,mtach方法是从头开始匹配,而search方法,可以在s字符串的任一位置查找。
意思就是match方法遇到了空格,那么它就会停止查找




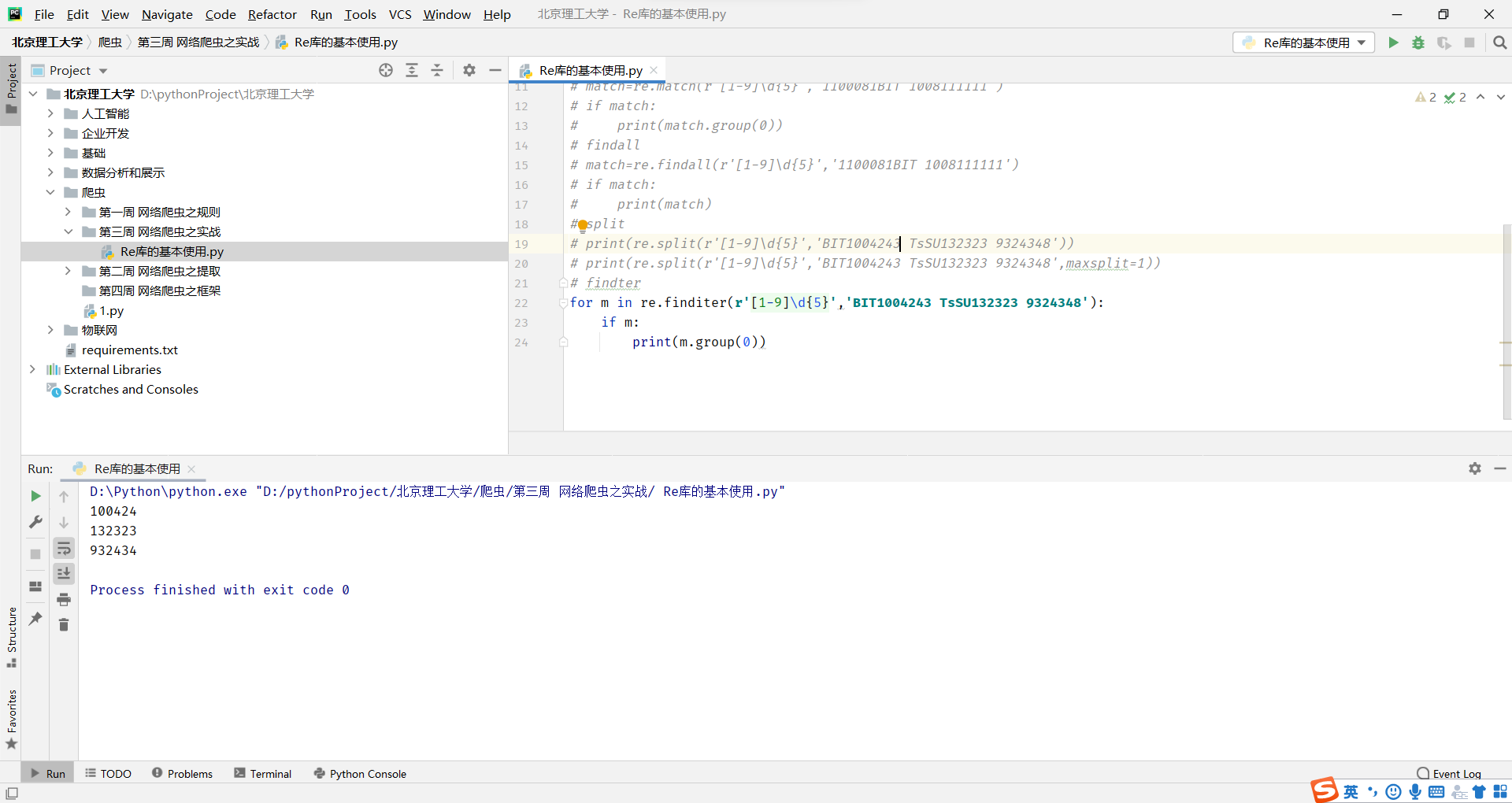





这种等价的用法是通过面向对象的方式来使用正则表达式,它包含有俩部分,第一个部分是使用re.compile,将一个正则表达式的字符串,编译成为一个正则表达式的类型,然后我们就可以通过pattern对象,直接调用search等六个方法来获取相关结果,这种方法的好处是经过一次编译,当我们需要多次对正则表达式进行使用和匹配时,就可以通过这个方式来加快整个程序的运行
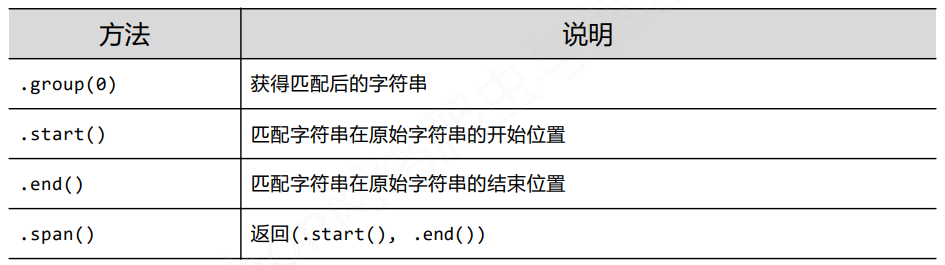
Re库的match对象


 Re库的贪婪匹配和最小匹配
Re库的贪婪匹配和最小匹配

默认是贪婪匹配,匹配最长的子串,如果要修改为非贪婪匹配,需要在后面加一个?,表示匹配最短的子串

淘宝商品信息定向爬虫

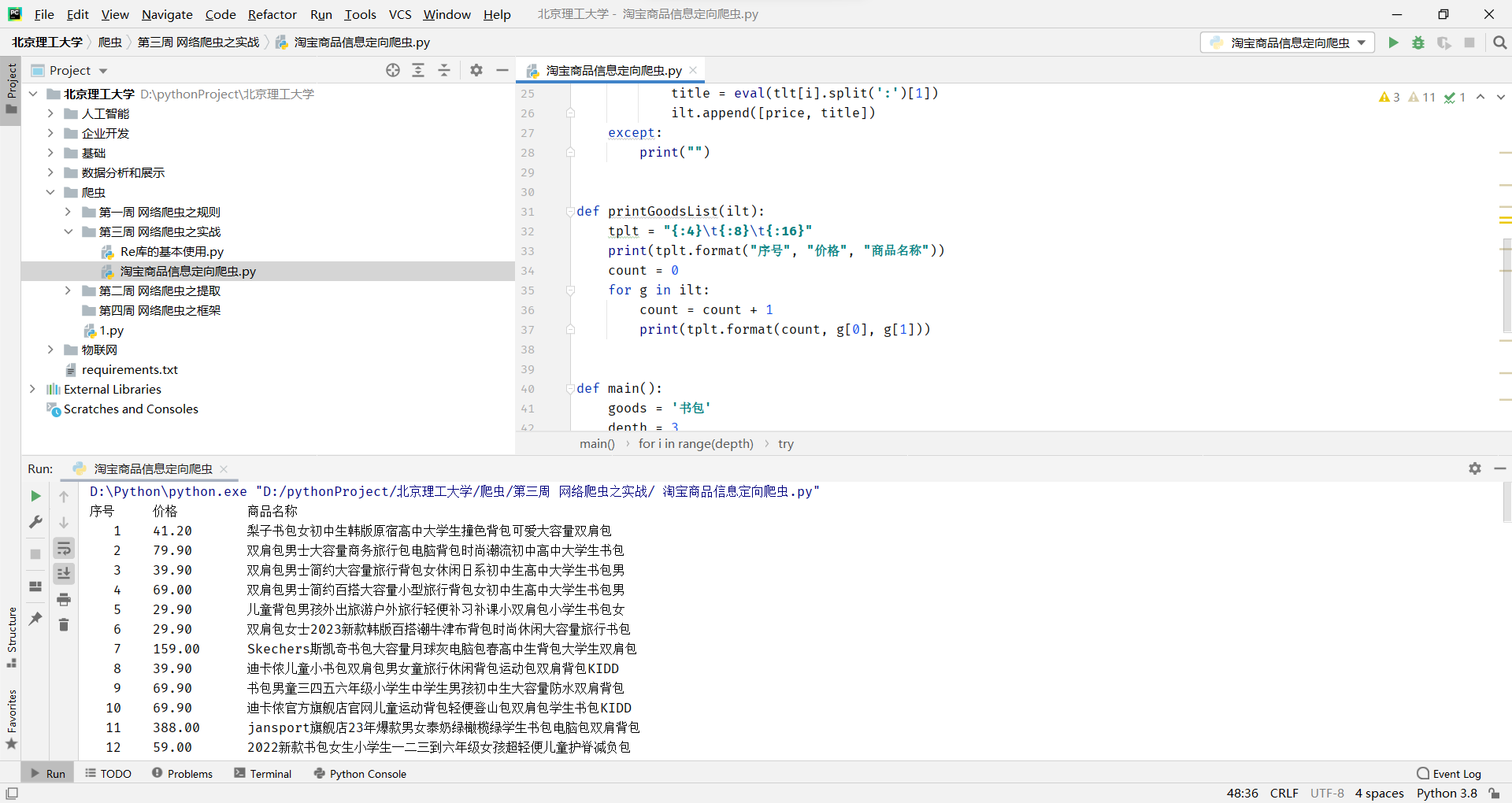
这段代码是一个简单的 Python 爬虫程序,用于爬取淘宝网上指定商品的价格和商品名称,并将结果输出到终端。以下是代码的具体解剖:
引入 requests 和 re 模块
import requests
import re这里使用 requests 模块发送 HTTP 请求,获取网页内容;使用 re 模块进行正则表达式匹配,提取所需信息。
定义函数 getHTMLText(url)
def getHTMLText(url):try:r = requests.get(url, timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return ""这个函数用于获取指定 url 的网页内容,如果访问成功则返回网页内容,否则返回空字符串。
定义函数 parsePage(ilt, html)
def parsePage(ilt, html):try:plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)for i in range(len(plt)):price = eval(plt[i].split(':')[1])title = eval(tlt[i].split(':')[1])ilt.append([price, title])except:print("")这个函数用于解析网页内容,提取价格和商品名称信息,将它们封装成一个列表并添加到 ilt 列表中。其中,plt 和 tlt 分别是提取价格和商品名称的正则表达式;eval 函数用于将提取出来的字符串转换为数值类型或字符串类型。
定义函数 printGoodsList(ilt)
def printGoodsList(ilt):tplt = "{:4}\t{:8}\t{:16}"print(tplt.format("序号", "价格", "商品名称"))count = 0for g in ilt:count = count + 1print(tplt.format(count, g[0], g[1]))这个函数用于将 ilt 列表中的商品价格和名称信息输出到终端,采用的是格式化输出。
定义主函数 main()
def main():goods = '书包'depth = 3start_url = 'https://s.taobao.com/search?q=' + goodsinfoList = []for i in range(depth):try:url = start_url + '&s=' + str(44 * i)html = getHTMLText(url)parsePage(infoList, html)except:continueprintGoodsList(infoList)这个函数用于控制整个爬虫程序的运行流程,首先指定要爬取的商品和爬取的页数;然后根据 start_url 和页数 depth 构造出多个 url,并循环遍历这些 url,通过调用 getHTMLText 函数获取网页内容,然后通过调用 parsePage 函数解析网页内容,将结果保存到 infoList 列表中;最后通过调用 printGoodsList 函数将结果输出到终端
优化一下

在这段代码中,使用了 f-string 格式化字符串的方式,避免了繁琐的字符串拼接操作。同时,优化了正则表达式,避免使用贪婪匹配,提高了代码的效率。
import requests
import redef getHTMLText(url):try:r = requests.get(url, timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return ""def parsePage(ilt, html):try:plt = re.findall(r'"view_price":"([\d\.]*)"', html)tlt = re.findall(r'"raw_title":"(.*?)"', html)for price, title in zip(plt, tlt):ilt.append([price, title])except:print("")def printGoodsList(ilt):print(f'{"序号":4}\t{"价格":8}\t{"商品名称":16}')count = 0for g in ilt:count += 1print(f'{count:4}\t{g[0]:8}\t{g[1]:16}')def main():goods = '书包'depth = 3start_url = f'https://s.taobao.com/search?q={goods}'infoList = []for i in range(depth):try:url = f'{start_url}&s={44*i}'html = getHTMLText(url)parsePage(infoList, html)except:continueprintGoodsList(infoList)if __name__ == '__main__':main()