国内有做外汇的正规网站吗网站关键词优化的价格
说明
果然还是碰到了一些小故障,看起来是好事。
这个故障算是一个设计上必须要考虑到的,提前碰到了也挺好。通过这个故障分析和修复,可以继续完善ADBS。
内容
1 问题描述
发现在work_out 队列始终有十几个任务没有输出。
使用docker logs CONTAINER --tail=100 查看后,发现是有一个特征缺失。
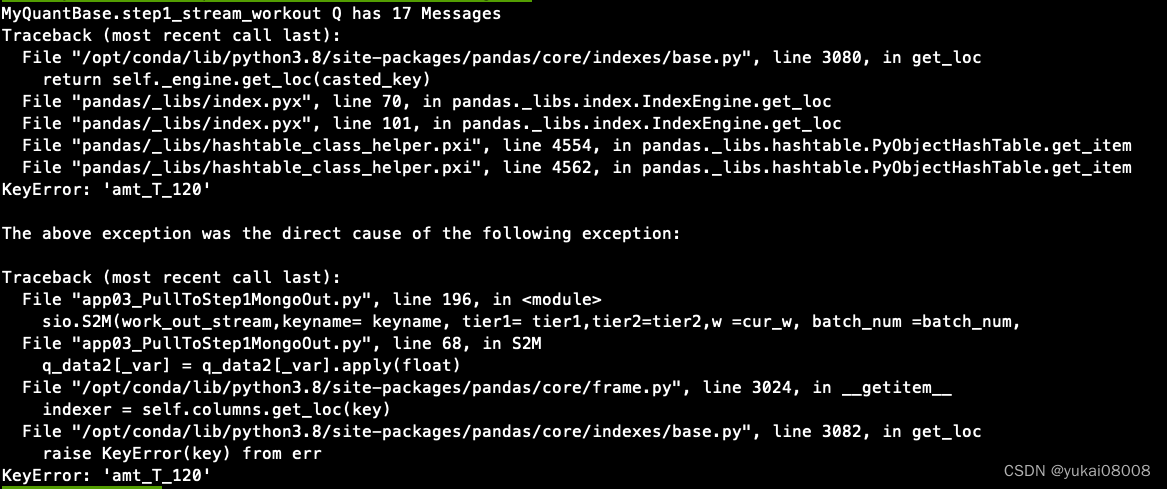
这个故障的最终结果是导致整个work out队列阻塞,无法再输出。
粗一想,这似乎挺脆弱,一粒老鼠屎也能坏一锅粥,是不是要放宽一些(例如允许漏掉几个时隙)。转念一想,从量化的逻辑上,肯定是应该严谨的。处理流停下来会让问题暴露的很清楚,甚至还应该发短信通知。前端的数据源应该是一条数据也不遗失才对。
所以,这是一个模式,一个有错就停止的模式,而不是一个需要完善的逻辑。
接下来先进行错误分析,解决具体的问题;然后,约定一个Worker输出的规范,这将作为ADBS的基础规范之一。
2 问题处理
- 1 找到出问题的时隙,将Worker的样例数据使用该时隙: 结果,Worker输出的结果正常
- 2 使用
worker01_ETL.py,修改了数据库字段后(重置)运行也正常 - 3 将整个容器关掉重启,重置所有的问题任务,运行结果正常
结论:可能是之前的某个版本有问题,总之现在无法复现,也没有故障了。
3 机制约定
3.1 入数据约定
每个系统的输入都是由sniffer驱动的,sniffer要遵循入数据schema。如果sniffer出错,那么数据无法进入系统。
表现在,监控页面没有数据流入;以及,mongo_in没有数据增长。
3.2 Worker约定
每个Worker会从队列中取数,然后进行处理。
在处理时,可能会有一些情况导致worker无法正常工作的:
- 1 原始数据错误。
- 2 原始数据不足(例如本次,根据数据再发起数据请求)。
- 3 worker的处理逻辑出错。
当问题出现时,数据或者会送到出队列,或者根本送不出(逻辑中断)
表现在,meta数据多余out数据;worker out队列始终存在残留,而且这些残留会继续阻断所有的后续处理(正常的也无法输出)。
处理的方法是调试正确后,将出现问题的任务在mongo_in中重置通道。一般来说,根据在mongo_in中创建的时间重刷就可以。
所以,这就要求所有的数据输出允许幂等操作:即数据可以重新处理多次。这是ADBS的幂等约定。
4 结论
原则上,我还是希望ADBS能够精确处理每一条数据,而发现错误即阻塞肯定是一种重要的运行模式。(后续还可能有容错运行模式)
本身从结构上,ADBS就是允许层层迭代的,这样总可以经过有限次的层级,将不稳定因素控制在很低的范围。核心的ADBS应该总是稳定
、精确运行的,而周边的ADBS(例如数据源)则可能有一定概率出现中断。
最后,还是希望故障早日重现,我还是假设系统或者逻辑仍然有不完备的地方。