建立的网站打开空白seo点击排名软件哪里好
面向人群: 零基础或者初学者
难度: 简单, 属于Python基础课程
对于那些学习编程的人来说,Python是一种出色的语言,非常适合那些希望“完成工作”并且不花很多时间在样板代码上的人。
重要说明
我们尽力保证课程内容的质量以及学习难度的合理性,但即使如此,真正决定课程效果的,还是你的每一次思考和实践。
课程多数题目的解决方案都不是唯一的,这和我们在实际工作中的情况也是一致的。因此,我们的要求功能的实现,更是要多去思考不同的解决方案,评估不同方案的优劣,然后使用在该场景下最优雅的方式去实现。所以,我们列出的参考资料未必是实现需求所必须的。有的时候,实现题目的要求很简单,甚至参考资料里就有,但是背后的思考和亲手去实践却是任务最关键的一部分。在学习这些资料时,要多思考,多提问,多质疑。相信通过和小伙伴们的交流,能让你的学习事半功倍。
一、可视化示例任务
1.1 简介
如同艺术家们用绘画让人们更贴切的感知世界,数据可视化也能让人们更直观的传递数据所要表达的信息。在本文中,我将介绍如何开始使用Python和matplotlib、seaborn两个库对数据进行可视化。
1.2 任务
下面这个图表:
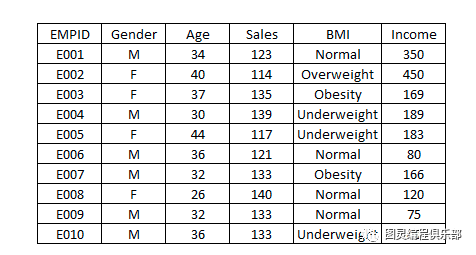
当然如果你把这张图表丢给别人,他们倒是也能看懂,但无法很直观的理解其中的信息,而且这种形式的图表看上去也比较 low,这个时候我们如果换成直观又美观的可视化图形,不仅能突显逼格,也能让人更容易的看懂数据。
下面我们就用上面这个简单的数据集作为例子,展示用 Python 做出9种可视化效果,并附有相关代码。分别是
直方图
箱线图
小提琴图
条形图
折线图
堆叠柱状图
散点图
气泡图
饼状图
热力图
1.3 知识点
Linux命令行的使用
Python基础
matplotlib、seaborn两个库的简单使用
.14 环境
linux系统(ubuntu18.04)/ windows系统可以打开ubuntu子系统
pycharm编辑器(windows如何安装pycharm社区版本)
Python 3.6.9(windows如何安装python环境)
pip3 9.0.1
Matplotlib 3.3.3:基于Python的绘图库,提供完全的 2D 支持和部分 3D 图像支持。在跨平台和互动式环境中生成高质量数据时,matplotlib 会很有帮助。也可以用作制作动画。
官方文档:https://matplotlib.org/
Seaborn:该 Python 库能够创建富含信息量和美观的统计图形。Seaborn 基于 matplotlib,具有多种特性,比如内置主题、调色板、可以可视化单变量数据、双变量数据,线性回归数据和数据矩阵以及统计型时序数据等,能让我们创建复杂的可视化图形。
官方文档: http://seaborn.pydata.org/
$ python --versionPython 3.6.9$ pip3 --versionpip 9.0.1 from /usr/lib/python3/dist-packages (python 3.6)windows系统:
(1)Win+R,输入cmd,打开Windows的命令行。(2)输入:pip install Matplotlib、Seaborn,等待安装完成。如果安装过程不顺利,请百度找到原因,直到安装成功为止
linux系统:
pip3 安装Matplotlib、Seaborn
pip3 install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simplepip3 install seaborn安装完后,你可以使用 python -m pip list 命令来查看是否安装了 matplotlib 模块。
$ pip3 list | grep matplotlibmatplotlib 3.3.3
1.5 代码
导入数据集
import matplotlib.pyplot as pltimport pandas as pddf=pd.read_excel("data/First.xlsx", "Sheet1")可视化为直方图
fig=plt.figure() #Plots in matplotlib reside within a figure object, use plt.figure to create new figure#Create one or more subplots using add_subplot, because you can't create blank figureax = fig.add_subplot(1,1,1)#Variableax.hist(df['Age'],bins = 7) # Here you can play with number of binsLabels and Titplt.title('Age distribution')plt.xlabel('Age')plt.ylabel('#Employee')plt.show()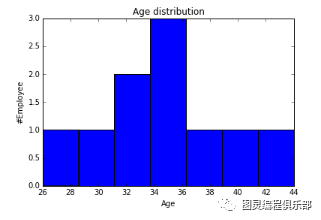
可视化为箱线图
import matplotlib.pyplot as pltimport pandas as pdfig=plt.figure()ax = fig.add_subplot(1,1,1)#Variableax.boxplot(df['Age'])plt.show()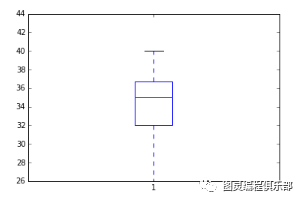
可视化为小提琴图
import seaborn as sns sns.violinplot(df['Age'], df['Gender']) #Variable Plotsns.despine()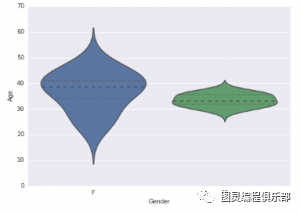
可视化为条形图
var = df.groupby('Gender').Sales.sum() #grouped sum of sales at Gender levelfig = plt.figure()ax1 = fig.add_subplot(1,1,1)ax1.set_xlabel('Gender')ax1.set_ylabel('Sum of Sales')ax1.set_title("Gender wise Sum of Sales")var.plot(kind='bar')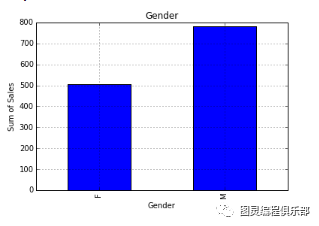
可视化为折线图
var = df.groupby('BMI').Sales.sum()fig = plt.figure()ax1 = fig.add_subplot(1,1,1)ax1.set_xlabel('BMI')ax1.set_ylabel('Sum of Sales')ax1.set_title("BMI wise Sum of Sales")var.plot(kind='line')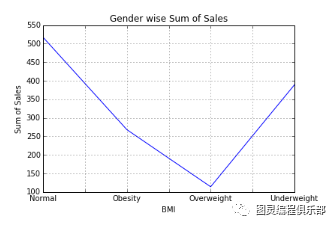
可视化为堆叠柱状图
var = df.groupby(['BMI','Gender']).Sales.sum()var.unstack().plot(kind='bar',stacked=True, color=['red','blue'], grid=False)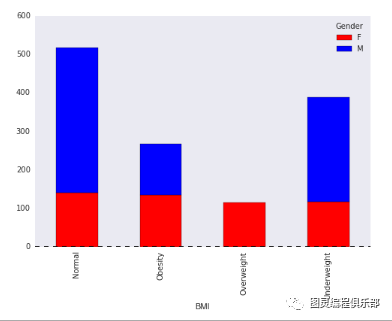
可视化为散点图
fig = plt.figure()ax = fig.add_subplot(1,1,1)ax.scatter(df['Age'],df['Sales']) #You can also add more variables here to represent color and size.plt.show()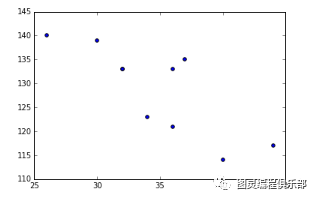
可视化为气泡图
fig = plt.figure()ax = fig.add_subplot(1,1,1)ax.scatter(df['Age'],df['Sales'], s=df['Income']) # Added third variable income as size of the bubbleplt.show()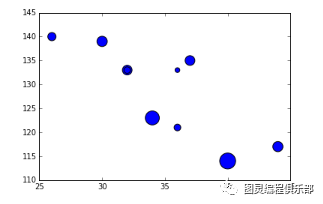
可视化为饼状图
var=df.groupby(['Gender']).sum().stack()temp=var.unstack()type(temp)x_list = temp['Sales']label_list = temp.indexpyplot.axis("equal") #The pie chart is oval by default. To make it a circle use pyplot.axis("equal")#To show the percentage of each pie slice, pass an output format to the autopctparameter plt.pie(x_list,labels=label_list,autopct="%1.1f%%") plt.title("Pastafarianism expenses")plt.show()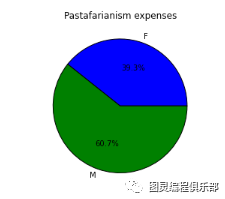
可视化为热力图
import numpy as np#Generate a random number, you can refer your data values alsodata = np.random.rand(4,2)rows = list('1234') #rows categoriescolumns = list('MF') #column categoriesfig,ax=plt.subplots()#Advance color controlsax.pcolor(data,cmap=plt.cm.Reds,edgecolors='k')ax.set_xticks(np.arange(0,2)+0.5)ax.set_yticks(np.arange(0,4)+0.5)# Here we position the tick labels for x and y axisax.xaxis.tick_bottom()ax.yaxis.tick_left()#Values against each labelsax.set_xticklabels(columns,minor=False,fontsize=20)ax.set_yticklabels(rows,minor=False,fontsize=20)plt.show()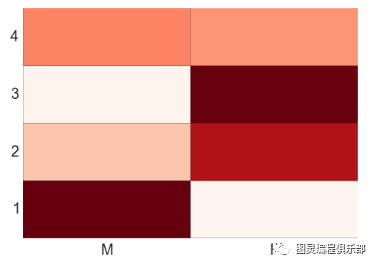
你也可以自己试着根据两个变量比如性别(X 轴)和 BMI(Y 轴)绘出热度图。
小结
这里我们分享了如何利用 Python 及 matplotlib 和 seaborn 库制作出多种多样的可视化图形。通过上面的例子,我们应该可以感受到利用可视化能多么美丽的展示数据。而且和其它语言相比,使用 Python 进行可视化更容易简便一些。
参考
https://www.analyticsvidhya.com/blog/2015/05/data-visualization-python/
二、可视化示例详情
2.1 基础概念
数据:离散的,客观事实的数字表示
信息:处理后的数据,为实际问题提供答案
为数据提供一种关系或一个关联后,数据就成了信息,这种关联通过提供数据背景来完成
知识: 是数据、信息和通过经验获得的技能
知识包括做出适当决策的能力和执行时所需的技能
观点:
如何获取观点: 基于已有数据信息得到最佳或现实的决策,我们可以通过数据分析
数据分析 依赖数学算法来确定产生观点的数据之间的关系
信息是可量化的、可测度的、有形式的,可被访问、生成、存储、分发、搜索、压缩和复制。
信息可以通过数量或信息量进行量化。,信息可转换为知识,知识要比信息更量化。在某些领域,知识持续经历一个不断发展周期。当数据发生变化时,这种演变过程随之发生。
通过离散算法
数据转换:数据被转换成信息,得到进一步处理,然后用来解决问题
数据的种类不同,包括表现数据, 实验数据,基准数据
2.2 可视化的思路和工具
可视化的整个过程需要不用技能和专业领域的人。
数据工人努力收集数据并完成分析
数学家和统计学家理解可视化设计原则,并用这些原则完成数据交流
设计师和艺术家和开发者具备可视化转换的技能
业务分析员等找寻行为模式,离群点或突发趋势
整个过程额步骤是:
获取或收集数据:
解析和过滤数据:用编程方法进行解析、清洗和减少数据
分析提炼数据:删除噪音和一些不必要维度,发展模式
呈现和交互 用更容易得到和理解的方式展示数据
这里我们会使用下面几种绘图工具
matplotlib:是一个最基础的Python可视化库,作图风格接近MATLAB,所以称为matplotlib。一般都是从matplotlib上手Python数据可视化,然后开始做纵向与横向拓展
Seaborn:是一个基于matplotlib的高级可视化效果库,针对的点主要是数据挖掘和机器学习中的变量特征选取,seaborn可以用短小的代码去绘制描述更多维度数据的可视化效果图
Plotly:绘图工具,是建立在一个开放源码库plotly.js上,由一家拥有多种产品和开源工具的
Pyecharts : 是基于百度echarts的一个开源项目,也是我目前接触到的最容易实现交互可视化的工具,相比bokeh和plotly,pyecharts的语法更简单,实现效果更佳出众(做过前端的对这个应该很了解)
Bokeh: 是一个用于做浏览器端交互可视化的库,实现分析师与数据的交互
pandas:是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
Mapbox: 处理
地理数据引擎更强的可视化工具库geoplotlib
cufflinks:a library for easy interactive Pandas charting with Plotly
数据的可视化是表达信息的过程,在可视化化过程我们要思考:
要处理多少变量?我们试图画出怎样的图像?
x轴和y轴指代什么?(三维图中有z轴)
数据的大小是否被标准化?数据点的大小意味着什么?
我们的选色对吗?
对于时间序列数据,我们是否试图识别趋势或相关性
2.3 主要图表的使用
2.3.1 点图
这里有个学生数据:http://www.knapdata.com/pytho...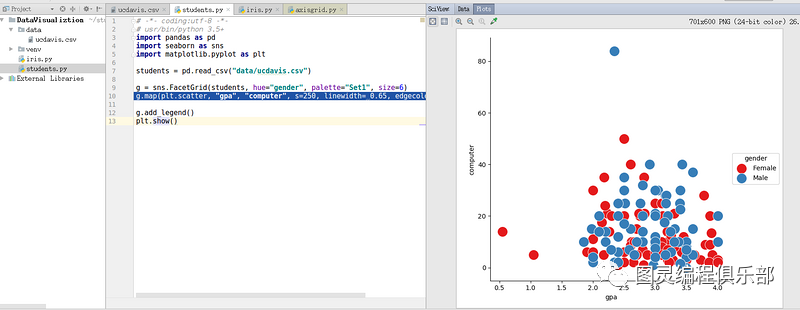
# -*- coding:utf-8 -*-
# usr/bin/python 3.5+
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
students = pd.read_csv("data/ucdavis.csv")
g = sns.FacetGrid(students, hue="gender", palette="Set1", size=6)
g.map(plt.scatter, "gpa", "computer", s=250, linewidth= 0.65, edgecolor="white")
g.add_legend()
plt.show()acetGrid 类可以刻画三个维度: 行、列、色调
点图:用于对数据子集中的一个变量的分布或者多个变量关系进行可视化
2.3.1 箱图
箱图(boxplot): 可能是最常见的图形类型之一。它能够很好表示数据中的分布规律。箱型图方框的末尾显示了上下四分位数。极线显示最高和最低值,不包括异常值。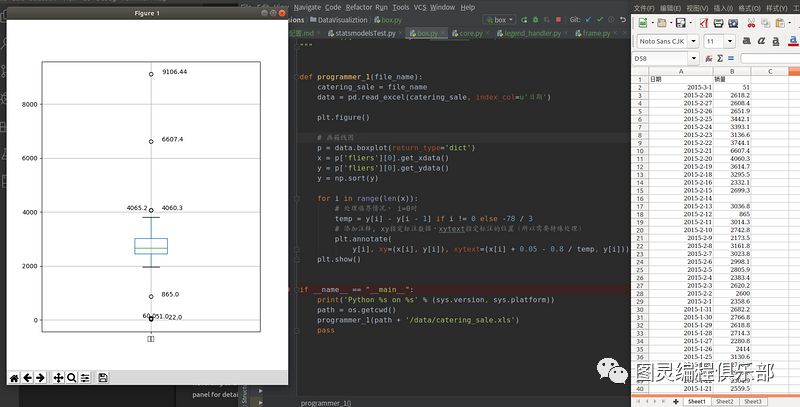
2.3.2 柱状图
matplotlib.pyplot.bar
import numpy as np
import matplotlib.pyplot as plt
N = 7
winnersplot = (142.6, 125.3, 62.0, 81.0, 145.6, 319.4, 178.1 )
ind = np.arange(N)
width = 0.35
fig, ax = plt.subplots()
winners = ax.bar(ind, winnersplot, width, color='#ffad00')
print(winners)
nomineesplot = (109.4, 94.8, 60.7, 44.6, 116.9,262.5,102.0)
nominees = ax.bar(ind + width, nomineesplot, width, color='#9b3c38')
# add some text for labels ,title and axes ticks
ax.set_xticks(ind+width)
ax.set_xticklabels(('小明', '小红', '小凡', '小钱', '小刘', '小赵', '小文'))
ax.legend((winners[0], nominees[0]),('奥斯卡金奖得住','奥斯卡得住提名'))
def autolabel(rects):
# attach some text labels
for rect in rects:
height = rect.get_height()
hcap = "$" + str(height) + "M"
ax.text(rect.get_x() + rect.get_width()/2. ,height, hcap,ha = 'center',va='bottom',rotation='horizontal')
autolabel(winners)
autolabel(nominees)
plt.show()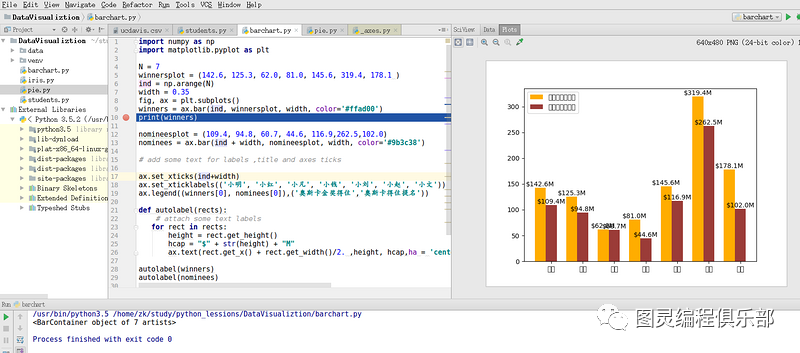
2.3.3 饼图
matplotlib.pyplot.pie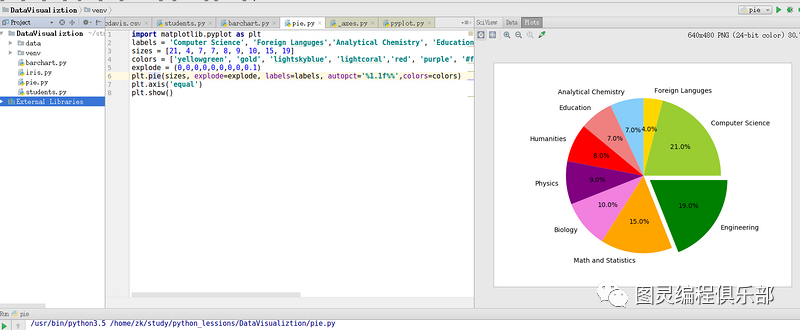
import matplotlib.pyplot as plt
labels = 'Computer Science', 'Foreign Languges','Analytical Chemistry', 'Education', 'Humanities', 'Physics', 'Biology', 'Math and Statistics', 'Engineering'
sizes = [21, 4, 7, 7, 8, 9, 10, 15, 19]
colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral','red', 'purple', '#f280de', 'orange', 'green']
explode = (0,0,0,0,0,0,0,0,0.1)
plt.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',colors=colors)
plt.axis('equal')
plt.show()2.3.4 散点图
散点图是同一组研究对象的两个变量间关系的可视化
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
students = pd.read_csv("data/ucdavis.csv")
g = sns.FacetGrid(students, palette="Set10",size=7)
g.map(plt.scatter, "momheight", "height",s=140, linewidth=.7,edgecolor = "#ffad40",color="#ff8000")
g.set_axis_labels("Mothers Heilsght", "Students Height")
plt.show()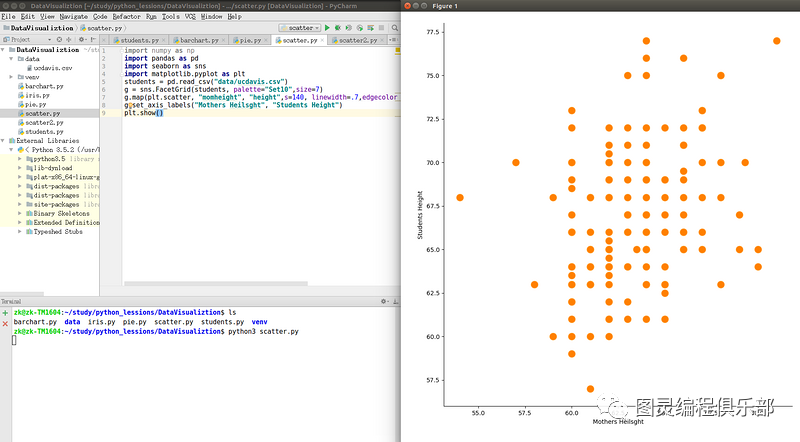
散点图最适合研究不同变量之间的关系:
男性与女性人群中不同年龄阶段得皮肤病的可能性
IQ测试得分和GPA之间的相关性
另外我们还要考虑:
添加一条趋势线或最佳拟合线(如果关系是线性的):添加趋势线可以展示数据之间的关联性
使用信息标记类型:信息标记类型适用于通过形状和颜色提高视觉效果来解读数据的情况
2.3.5 直方图
直方图(Histogram)又称质量分布图。是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据类型,纵轴表示分布情况。
import numpy as np
import pandas as pd
from scipy import stats, integrate
import matplotlib.pyplot as plt #导入
import seaborn as sns
sns.set(color_codes=True)#导入seaborn包设定颜色
np.random.seed(sum(map(ord, "distributions")))
x = np.random.normal(size=100)
sns.distplot(x, kde=False, rug=True);#kde=False关闭核密度分布,rug表示在x轴上每个观测上生成的小细条(边际毛毯)
plt.show()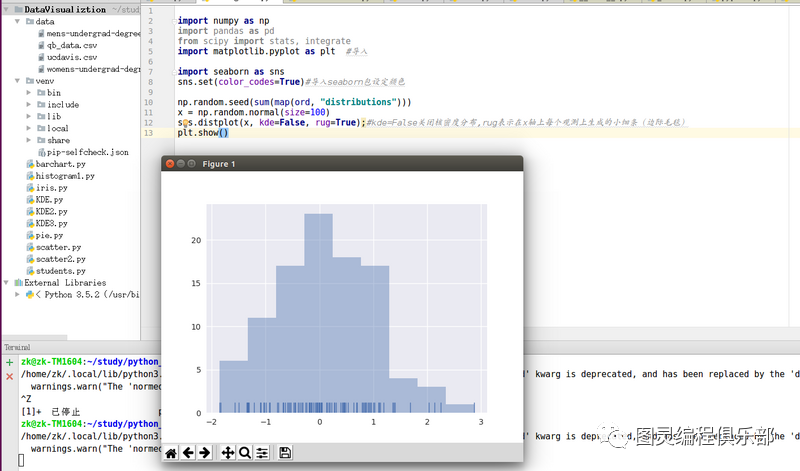
当绘制直方图时,你最需要确定的参数是矩形条的数目以及如何放置它们。利用bins可以方便设置矩形条的数量。如下所示:
sns.distplot(x, bins=20, kde=False, rug=True);#设置了20个矩形条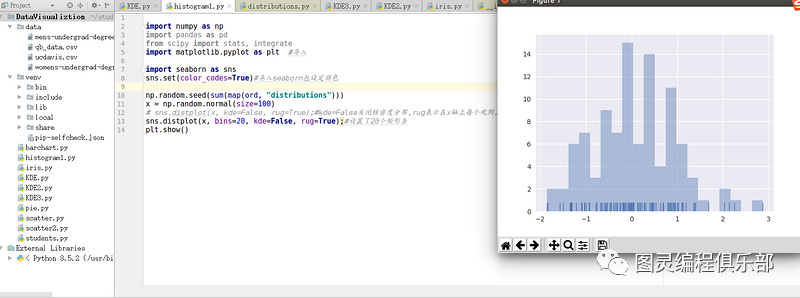
2.3.6 核密度估计图
核密度估计(Kernel Density Estimation, KDE)是一种用来估计概率密度函数的非参数方法。可以通过观测到的数据点取平均实现平滑逼近。
核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。.由于核密度估计方法不利用有关数据分布的先验知识,对数据分布不附加任何假定,是一种从数据样本本身出发研究数据分布特征的方法,因而,在统计学理论和应用领域均受到高度的重视。
核密度函数与直方图密切相关,但有时能够通过核概念用平滑性或连续性赋予实际含义。
概率密度函数(Probablity Density Function,PDF)的核是PDF的形式。这种形式不考虑非变量函数因素。
这里我们用一个鸢尾花数据集和seaborn包展示KDE图
使用seaborn 和matplotlib演示KDE图
seaborn.distplot
This function combines the matplotlib hist function (with automatic calculation of a good default bin size) with the seaborn kdeplot() and rugplot() functions. It can also fit scipy.stats distributions and plot the estimated PDF over the data.
seaborn的displot()集合了matplotlib的hist()与核函数估计kdeplot的功能,增加了rugplot分布观测条显示与利用scipy库fit拟合参数分布的新颖用途。具体用法如下:
seaborn入门(一):distplot与kdeplot
seaborn.kdeplot
distplot()
distplot 函数默认同时绘制直方图和KDE(核密度图)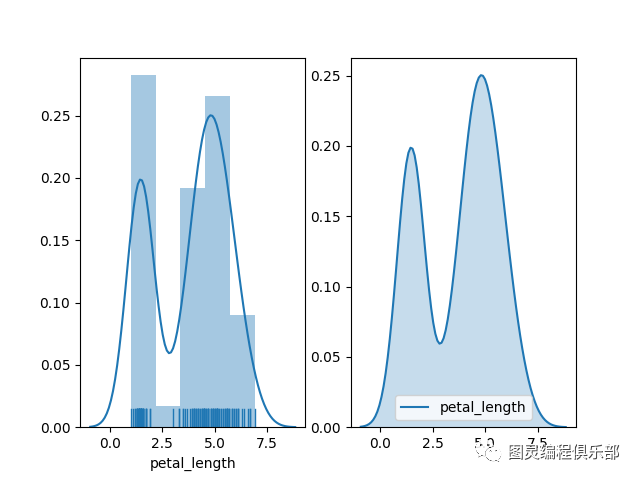
from numpy.random import randn
import matplotlib as mpl
import seaborn as sns
import matplotlib.pyplot as plt
#引入鸢尾花数据集
df_iris = sns.load_dataset("iris")
fig, axes = plt.subplots(1,2)
# print(df_iris['petal_length'])
# print(axes[0])
# distplot 函数默认同时绘制直方图和KDE(核密度图),开启rug细条
sns.distplot(df_iris['petal_length'], ax= axes[0], rug = True)
# shade 阴影
sns.kdeplot(df_iris['petal_length'], ax = axes[1], shade = True)
plt.show()如果不需要核密度图,可以将kde参数设置成False。
sns.distplot(df_iris['petal_length'], ax= axes[0], kde = False, rug = True)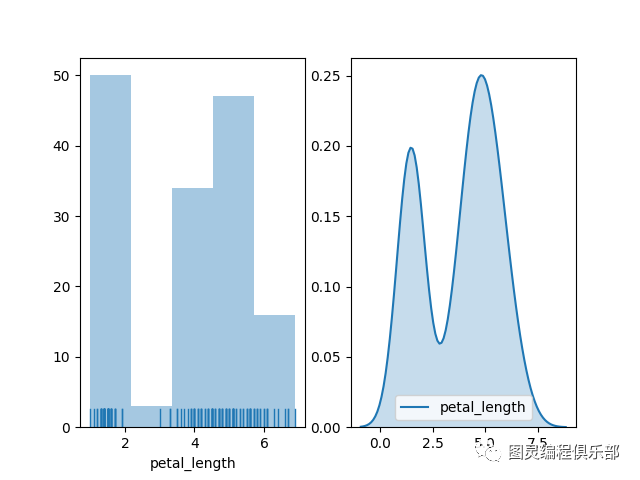
如果不需要核密度图,可以将hist参数设置成False。
sns.distplot(df_iris['petal_length'], ax= axes[0], hist = False, rug = True)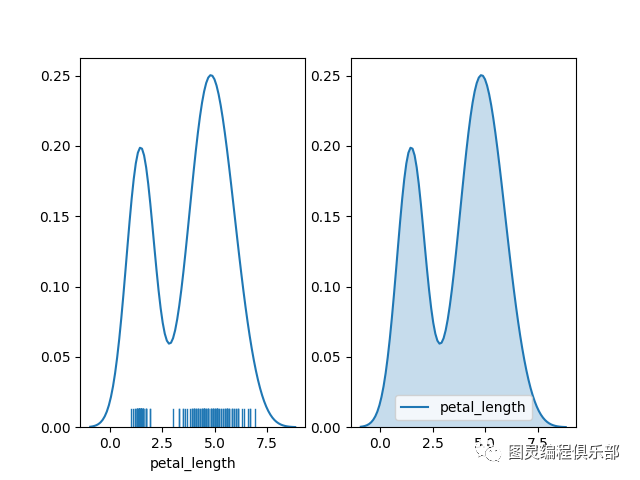
# Fitting parametric distributions拟合参数分布
# 可以利用distplot() 把数据拟合成参数分布的图形并且观察它们之间的差距,再运用fit来进行参数控制。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="white", palette="muted", color_codes=True)
rs = np.random.RandomState(10)
# Set up the matplotlib figure
f, axes = plt.subplots(2, 2, figsize=(7, 7), sharex=True)
sns.despine(left=True)
#引入鸢尾花数据集
df_iris = sns.load_dataset("iris")
# Plot a simple histogram with binsize determined automatically
sns.distplot(df_iris['petal_length'], ax= axes[0, 0], kde = False, color="b")
# Plot a kernel density estimate and rug plot
sns.distplot(df_iris['petal_length'], ax= axes[0, 1], kde = False, color="r", rug=True)
# Plot a filled kernel density estimate
sns.distplot(df_iris['petal_length'], ax= axes[1, 0], hist = False, color="g", kde_kws={"shade": True})
# Plot a historgram and kernel density estimate
sns.distplot(df_iris['petal_length'], color="m", ax=axes[1, 1])
plt.setp(axes, yticks=[])
plt.tight_layout()
plt.show()
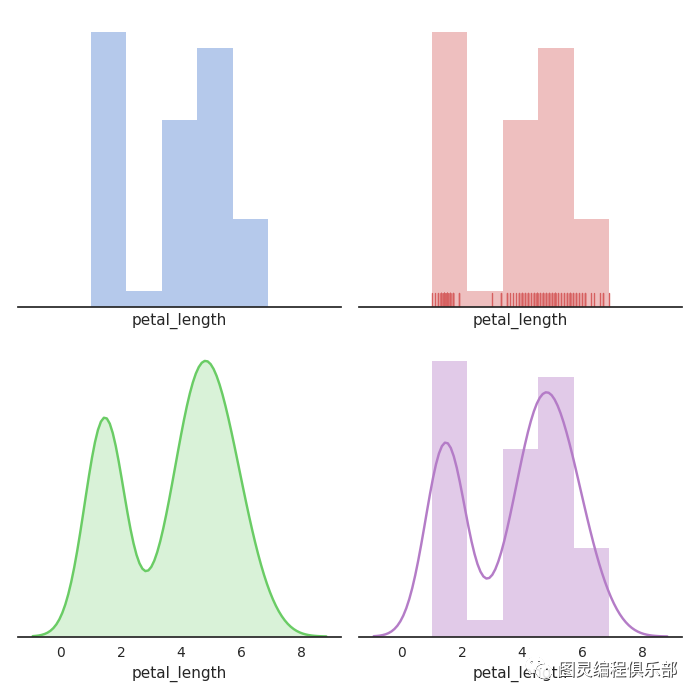
Fitting parametric distributions拟合参数分布
使用Scipy和Numpy演示KDE图
我们用Scipy 和 Numpy表明概率密度函数
首先用Scipy中的norm()创建正态分布样本
然后用Numpy中的hstack()进行水平方向上的堆叠
再用Scipy中的gaussian_kde()
from scipy.stats.kde import gaussian_kde
from scipy.stats import norm
from numpy import linspace, hstack
import matplotlib.pyplot as plt
from matplotlib.pylab import plot,show, hist
sample1 = norm.rvs(loc=-0.1,scale=1,size=320)
sample2 = norm.rvs(loc=2.0,scale=0.6,size=130)
sample = hstack([sample1,sample2])
probDensityFun = gaussian_kde(sample)
plt.title("KDE Demonstration using Scipy and Numpy",fontsize=20)
x = linspace(-5,5,200)
plot(x,probDensityFun(x),'r')
hist(sample,normed=1,alpha=0.45,color='purple')
show()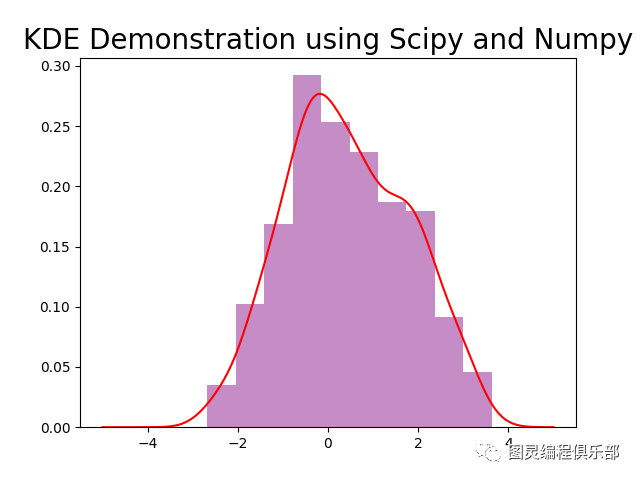
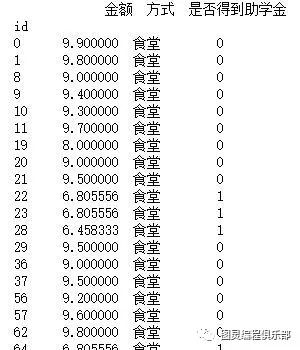
利用kdeplot探索某大学学生消费习惯与助学金获得关系
数据集如下所示:
拓展
下次我们讲解下数据分析和可视化的具体使用案例
】
❤️爱心三连击
1.看到这里了就点个在看支持下吧,你的「点赞,在看」是我们创作的动力。
2.关注公众号图灵编程俱乐部
回复「沙龙」参加线上线下技术沙龙; 回复「python」参加python训练营; 回复「java」参加2020版企业实战Java精英线下课程; 回复「图灵编程」了解图灵IT青年俱乐部;3.也可添加微信【17612567626】,一起成长。
