廊坊高端网站制作3小时百度收录新站方法
文/晗灵
1.词向量是什么
正如下图所示:语谱图带有语音信号丰富的特征;图片天然的矩阵密集表示直接可供计算机理解;词向量的意义正在于,将计算机不可直接理解的文字信息表示为可理解的数字向量,并内蕴文字本身的语法语义信息。
2.词向量怎么做
通常来说,可以分为离散化以及分布式两个大类。
2.1.离散化表式
one-hot representation,独热表示,又称一位有效表示,其方法是使用N位状态寄存器来对N个有效值进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效,设置为1,其余置0。它有着易于理解易于生成等有点。相对的,所带来的维度灾难以及各向量两两正交,不保留任何语法语义信息,也使得该方法逐渐被取代。
举个栗子:有如下文本: I
like deep learning.I like NLP. I enjoy flying.
首先生成词表{I,like,deep,learning,NLP,enjoy,flying}
继而每个词的表示如下:I = [1,0,0,0,0,0,0]; like = [0,1,0,0,0,0,0] ...
2.2.分布式表式
离散化表示丢弃了文本的语义信息,使得语义理解的任务在一段时间内处于停滞不前的阶段。分布式表示的大类方法,期望将语义信息融入到向量编码,作出了一系列的尝试。
2.2.1.基于统计
基于统计的方法,尝试通过考虑字词间的位置关系来保留语义信息,基于共现矩阵的方法是其中的代表作。
2.2.1.1.基于共现矩阵
设定一个窗口大小,以该窗口大小进行文本扫描,记录其中出现的匹配对。同样以2.1中的文本为例,假定窗口大小为2,下图中第一行的0,2分别代表着:I I 在文本中出现0次,I like分别出现了2次,以此类推。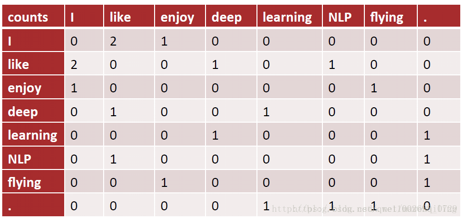
2.2.1.2.基于奇异值分解
基于奇异值分解的方法,出发点主要是为了缓解基于共现矩阵方法依旧带来的数据高维问题。希望通过奇异值分解的方式,映射到低维空间,以便后续处理。
2.2.2.基于语言模型
对于语言序列W1,W2,...,Wn,语言模型就是计算该序列的概率,由链式法则得:
2.2.2.1.word2vec
word2vec,2013年由谷歌提出,基于浅层神经网络求解词向量。存在CBOW和Skip-gram两种设计模式。CBOW采取利用上下文预测中间词的策略;Skip-gram恰恰相反,利用中间词预测上下文。针对训练语料的多少,对生僻字的重视程度,灵活选取相应策略。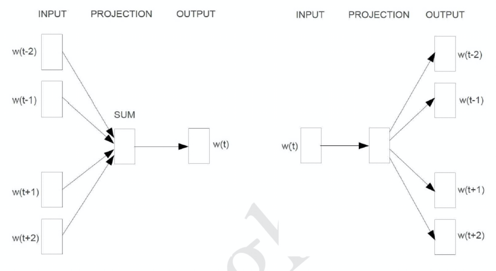
2.2.2.2.bert
再经历了word2vec,GPT,ELMo等模型之后,BERT模型以Transformer模型为基础,利用双向上下文信息,创新性提出masked lm loss 以及 next sentence loss,在11项nlp下游任务中取得了最佳成绩。下面左图表示文本embedding由单词,段,位置信息三部分构成,然后送入右图Transformer结构进行文本编码。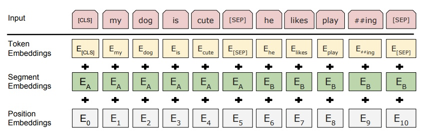
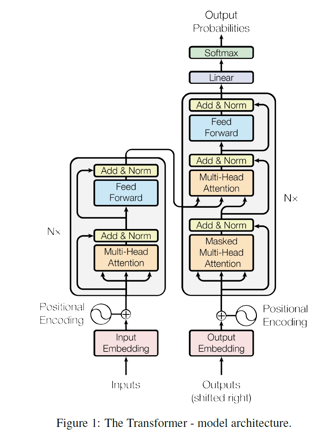
针对loss部分,举个例子:
masked lm loss :
原句:今天天气好晴朗
随机mask其中的字:今[mask]天气好晴[mask]
目标:正确预测出掩码字: 天 and 朗
next sentence loss : 二分类任务
这道题太难了;我不会做; True -》表示两句话是上下文关系
这道题太难了;618了,准备剁手; False -》表示两句话非上下文关系
3.在前端智能化中的初步应用
3.1 问题描述
在目前的智能化代码生成任务P2C中,我们希望通过需求文档直接生成对应代码,以其中局部一个小例子展示nlp在其中发挥的作用。如下图所示,我们首先将问题进行抽象。问题1,获取该句话的说话意图;问题2,提取出一句话中所有的实体关系,即SPO三元组。
3.2 方案描述
3.2.1. 层次多标签分类
采用Transformer作为模型的编码层,采用BCELossWithLogits作为多标签分类任务的常用损失函数。同时,采取Recursive
regularization正则项措施,对标签的层级信息加以约束。
3.2.2. 实体关系提取
以Bert模型作为主框架,将文本作为sentence A, 将需要预测的关系作为sentence B, 以此构成Bert模型的输入。将关系预测的分类任务和实体提取的序列化标注任务统一在一个模型结构中,期冀将已有的关系信息作为第三方知识进行输入,也能为实体提取的准确性带来效果增益。

关于找一找教程网
本站文章仅代表作者观点,不代表本站立场,所有文章非营利性免费分享。
本站提供了软件编程、网站开发技术、服务器运维、人工智能等等IT技术文章,希望广大程序员努力学习,让我们用科技改变世界。
[浅谈自然语言处理中的词向量]http://www.zyiz.net/tech/detail-137593.html