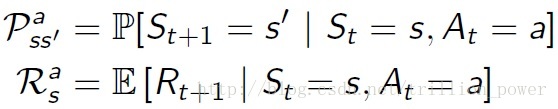二级域名网站建设百度竞价代运营托管
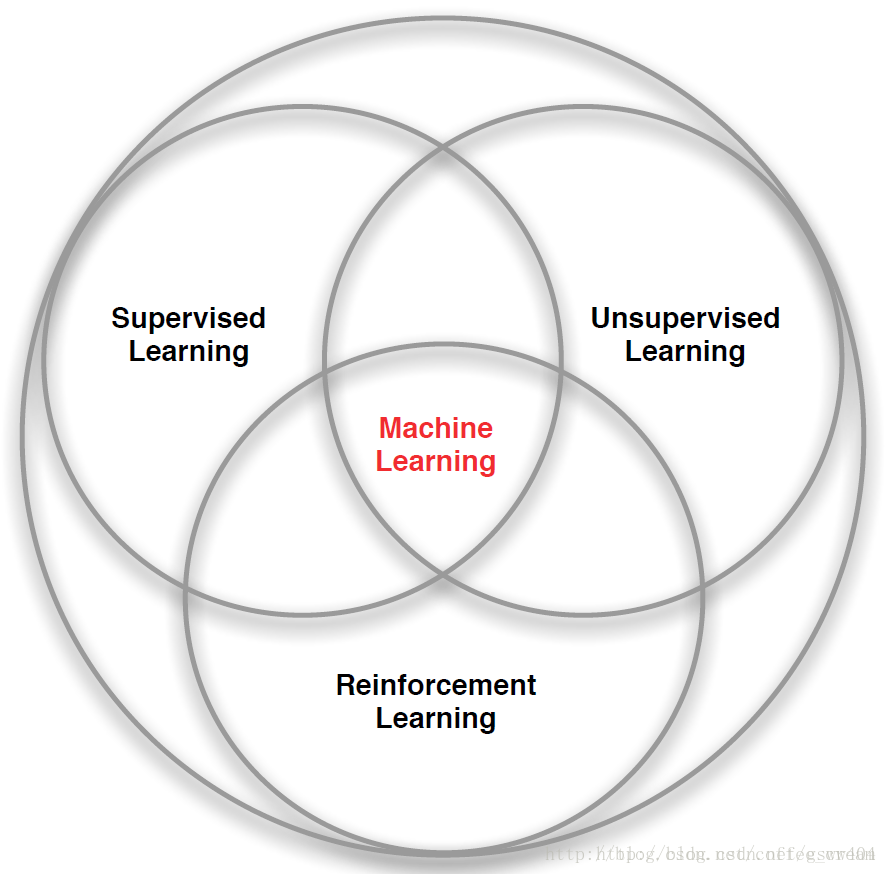
机器学习可以分为三类,分别是 supervised learning,unsupervised learning 和reinforcement learning。
强化学习与监督学习,非监督学习之间的关系
强化学习是机器学习的一种方法,同样类似于深度学习,他们之间的关系可以用一幅图简单明了的描述:
RL与有监督学习、无监督学习的比较:
(1)有监督的学习是从一个已经标记的训练集中进行学习,训练集中每一个样本的特征可以视为是对该situation的描述,而其label可以视为是应该执行的正确的action,但是有监督的学习不能学习交互的情景,因为在交互的问题中获得期望行为的样例是非常不实际的,agent只能从自己的经历(experience)中进行学习,而experience中采取的行为并一定是最优的。这时利用RL就非常合适,因为RL不是利用正确的行为来指导,而是利用已有的训练信息来对行为进行评价。
(2)因为RL利用的并不是采取正确行动的experience,从这一点来看和无监督的学习确实有点像,但是还是不一样的,无监督的学习的目的可以说是从一堆未标记样本中发现隐藏的结构,而RL的目的是最大化reward signal。
(3)总的来说,RL与其他机器学习算法不同的地方在于:其中没有监督者,只有一个reward信号;反馈是延迟的,不是立即生成的;时间在RL中具有重要的意义;agent的行为会影响之后一系列的data。
强化学习与其他机器学习不同之处为:
没有教师信号,也没有label。只有reward,其实reward就相当于label。
反馈有延时,不是能立即返回。
相当于输入数据是序列数据。
agent执行的动作会影响之后的数据。
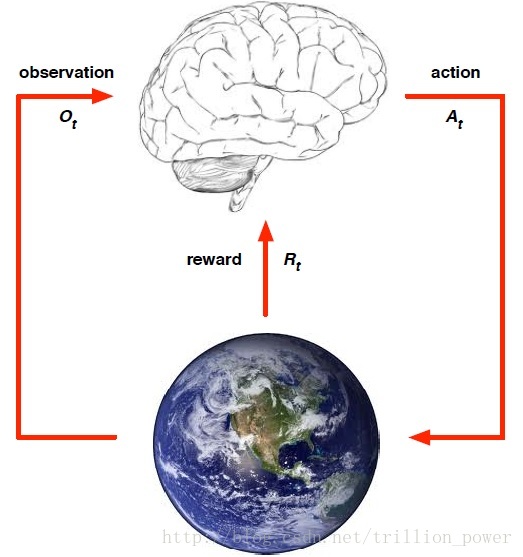
强化学习的关键要素有:environment,reward,action 和 state。有了这些要素我们就能建立一个强化学习模型。
强化学习解决的问题是,针对一个具体问题得到一个最优的policy,使得在该策略下获得的reward最大。所谓的policy其实就是一系列action。也就是sequential data。
强化学习可用下图来刻画,都是要先从要完成的任务提取一个环境,从中抽象出状态(state) 、动作(action)、以及执行该动作所接受的瞬时奖赏(reward)。
reward
reward通常都被记作,表示第t个time step的返回奖赏值。所有强化学习都是基于reward假设的。reward是一个scalar。
action
action是来自于动作空间,agent对每次所处的state用以及上一状态的reward确定当前要执行什么action。执行action要达到最大化期望reward,直到最终算法收敛,所得的policy就是一系列action的sequential data。
state
就是指当前agent所处的状态。
policy
policy就是只agent的行为,是从state到action的映射,分为确定策略和与随机策略,确定策略就是某一状态下的确定动作, 随机策略以概率来描述,即某一状态下执行这一动作的概率。
value function
因为强化学习今本上可以总结为通过最大化reward来得到一个最优策略。但是如果只是瞬时reward最大会导致每次都只会从动作空间选择reward最大的那个动作,这样就变成了最简单的贪心策略(Greedy policy),所以为了很好地刻画是包括未来的当前reward值最大(即使从当前时刻开始一直到状态达到目标的总reward最大)。因此就构造了值函数(value function)来描述这一变量。表达式如下:
是折扣系数(取值在),就是为了减少未来的reward对当前动作的影响,然后就通过选取合适的policy使value function最大。著名的bellman方程是强化学习各大算法(e.g. 值迭代,策略迭代,Q-learning)的源头。
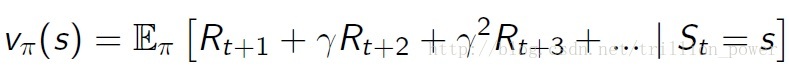
model
model就是用来预测环境接下来会干什么,即在这一状态的情况下执行某一动作会达到什么样的状态,这一个动作会得到什么reward。所以描述一个模型就是用动作转移概率与动作状态reward。具体公式如下:
学习资料:
书籍:
1、Sutton的书《Reinforcement learning: an introduction》,网上电子版(这点国外的非常良心,都是把手稿版放出来)
2、郭宪博士2017年写的《深入浅出强化学习:原理入门》,这是一本入门级别的书,语言通俗易懂
3、《Algorithm for reinforcement learning》,Morgan&Claypool的书推荐大家看
4、《Reinforcement learning and dynamic programming using function approximators》