网站建设市场多大百度seo优化排名客服电话
Spark 应用程序非常依赖用于执行的集群配置。重要的是事先了解集群大小,以提高效率,为处理提供足够的资源。
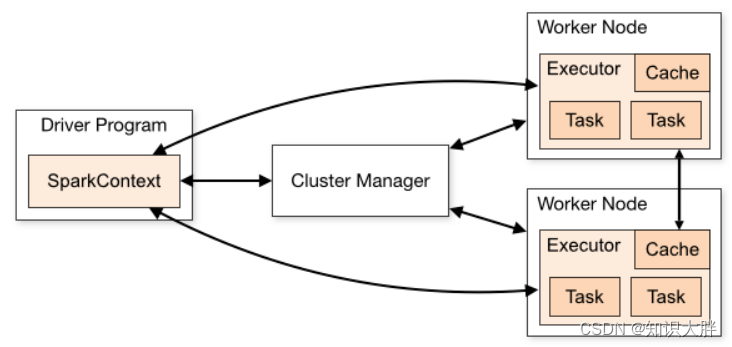
Spark 通过分布式并行处理能力实现其强大功能。为了获得更好的结果,我们总是必须从所有可能性中调整和估计正确的配置。
Spark确定并行度=执行器数量X每个执行器的核心数

让我们考虑以下示例:我们有一个包含10 个节点、26 个核心/节点和256GB 内存/节点的集群。

Fat Executors:如果我们分配所有核心来为每个节点创建一个执行器,即 1 个执行器/节点,每个节点有 26 个核心。缺点——它会产生很多垃圾收集(GC)问题,导致性能下降。
Tiny/Slim Executors:如果我们分配 1 个核心/执行器并从上述配置创建 26 个执行器/节点。缺点——执行器之间的数据移动过多,使应用程序始终处于忙碌状态,从而导致性能下降。
那么,有什么可能更好的配置呢?从几项测试来看,4 到 5 个内核/执行器提供了最佳性能,并避免了胖或小执行器的问题。
在我们运行最终配置之前,让我们考虑一下开销。
开销 1:总内存/执行器 = 内存开销 +