开源网站推广sem竞价推广
背景
前面两篇文章介绍了 SimHash 算法流程、基于 SimHash 指纹分段的相似文本检索过程,本文来介绍具体的代码实现。
IT 同行都知道,编码是最没有难度的工作,不过是把前面的流程描述翻译成代码而已。本文就来翻译一下 SimHash 算法和检索工具吧。
流程回顾
SimHash 算法流程:
- 分词:对文本进行分词,得到 N 个 词 word_1word1,word_2word2,word_3word3 …… word_nwordn;
- 赋权重:对文本进行词频统计,为各个词设置合理的权重 weight_1weight1,weight_2weight2,weight_3weight3 …… weight_nweightn;
- 哈希:计算每个分词的哈希值 hash_ihashi,得到一个定长的二进制序列,一般是 64 位,也可以是 128 位;
- 加权重:变换每个分词 word_iwordi 的 hash_ihashi,将 1 变成正的权重值 weight_iweighti,0 变成 -weight_i−weighti,得到一个新的序列 weightHash_iweightHashi;
- 叠加权重:对每个 weightHash_iweightHashi 各个位上的数值做累加,最终得到一个序列 lastHashlastHash,序列的每一位都是所有分词的权重的累加值;
- 降维:再将 lastHashlastHash 变换成 01 序列 simHash ,方法是:权重值大于零的位置设置为 1,小于 0 的位置设置为 0,它就是整个文本的局部哈希值,即指纹。
基于 SimHash 的相似文本检索工具流程:
- 计算 SimHash :对目标文本计算 SimHash 值,长度为 64 位;
- 拆解 SimHash 值为 4 段,每一段 16 位存入数组 hashs;
- 遍历数组 hashs,以该段的值为 key ,调用 RedisUtil.get(key) 判断是否有缓存记录;
- matchedSimHash 为空,说明没有相似记录,则缓存目标文本的 SimHash 值,检索结束;否则,继续。
- 遍历 matchedSimHash 列表,计算当前 SimHash 与列表中每一个 SimHash 值的汉明距离,如果找到一个小等于 3 的值,则找到相似文本,流程结束;否则,继续。
- 外层每一段遍历结束、内存每个匹配列表遍历结束,仍然无相似记录,说明没有相似记录,则缓存目标文本的 SimHash 值,检索结束。
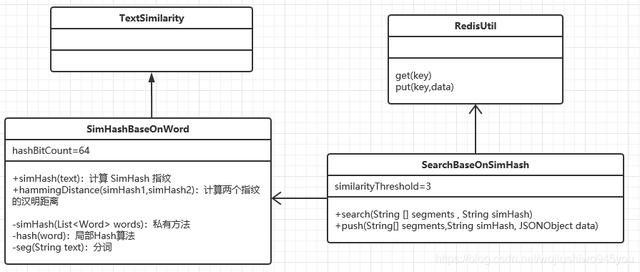
类图设计
SimHash 算法的实现主要难点在于分词和赋权重,本文使用 GitHub 上的一个分词工具 word ,继承它的 TextSimilarity 来实现,功能涉及的类图:
依赖准备
创建一个项目,pom.xml 添加两个依赖:
org.apdplat word 1.3.1com.alibaba fastjson 1.2.70需要注意的是,word 这个依赖不容易下载成功,可以直接将 word.1.3.1.jar 放入项目目录,手动添加依赖。
实现代码
根据 SimHash 算法流程,实现 SimHashBaseOnWord 这个类的代码如下:
public class SimHashBaseOnWord extends TextSimilarity { private static final Logger LOGGER = LoggerFactory.getLogger(SimHashBaseOnWord.class); // 生成 64 位的 SimHash private int hashBitCount = 64; public SimHashBaseOnWord(){ } public SimHashBaseOnWord(int hashBitCount) { this.hashBitCount = hashBitCount; } @Override protected double scoreImpl(List words1, List words2){ //用词频来标注词的权重 taggingWeightWithWordFrequency(words1, words2); //计算SimHash String simHash1 = simHash(words1); String simHash2 = simHash(words2); //计算SimHash值之间的汉明距离 int hammingDistance = hammingDistance(simHash1, simHash2); if(hammingDistance == -1){ LOGGER.error("文本1和文本2的SimHash值长度不相等,不能计算汉明距离"); return 0.0; } int maxDistance = simHash1.length(); double score = (1 - hammingDistance / (double)maxDistance); return score; } /** * 计算文本对应的 SimHash 值 * @param text * @return */ public String simHash(String text) { List words = seg(text); return this.simHash(words); } /** * 计算等长的SimHash值的汉明距离 * 如不能比较距离(比较的两段文本长度不相等),则返回 64 * @param simHash1 SimHash值1 * @param simHash2 SimHash值2 * @return 汉明距离 */ public int hammingDistance(String simHash1, String simHash2) { if (simHash1.length() != simHash2.length()) { return this.hashBitCount; } int distance = 0; int len = simHash1.length(); for (int i = 0; i < len; i++) { if (simHash1.charAt(i) != simHash2.charAt(i)) { distance++; } } return distance; } /** * 计算词列表的SimHash值,通过分词的时候已经统计了词的权重 * @param words 词列表 * @return SimHash值 */ private String simHash(List words) { float[] hashBit = new float[hashBitCount]; words.forEach(word -> { float weight = word.getWeight()==null?1:word.getWeight(); BigInteger hash = hash(word.getText()); for (int i = 0; i < hashBitCount; i++) { BigInteger bitMask = new BigInteger("1").shiftLeft(i); if (hash.and(bitMask).signum() != 0) { hashBit[i] += weight; } else { hashBit[i] -= weight; } } }); StringBuffer fingerprint = new StringBuffer(); for (int i = 0; i < hashBitCount; i++) { if (hashBit[i] >= 0) { fingerprint.append("1"); }else{ fingerprint.append("0"); } } return fingerprint.toString(); } /** * 计算文本的哈希值,很常见的一个 Hash 算法 * @param word 词 * @return 哈希值 */ private BigInteger hash(String word) { if (word == null || word.length() == 0) { return new BigInteger("0"); } char[] charArray = word.toCharArray(); BigInteger x = BigInteger.valueOf(((long) charArray[0]) << 7); BigInteger m = new BigInteger("1000003"); BigInteger mask = new BigInteger("2").pow(hashBitCount).subtract(new BigInteger("1")); long sum = 0; for (char c : charArray) { sum += c; } x = x.multiply(m).xor(BigInteger.valueOf(sum)).and(mask); x = x.xor(new BigInteger(String.valueOf(word.length()))); if (x.equals(new BigInteger("-1"))) { x = new BigInteger("-2"); } return x; } /** * 对文本进行分词 * @param text * @return */ private List seg(String text) { if(text == null){ return Collections.emptyList(); } Segmentation segmentation = SegmentationFactory.getSegmentation(SegmentationAlgorithm.MaxNgramScore); List words = segmentation.seg(text); if(filterStopWord) { //停用词过滤 StopWord.filterStopWords(words); } return words; }public static void main(String[] args) throws Exception{ String text1 = "我的兴趣爱好是看书"; String text2 = "看书是我的兴趣爱好"; String text3 = "我爱好看书"; SimHashBaseOnWord textSimilarity = new SimHashBaseOnWord(); double score1pk2 = textSimilarity.similarScore(text1, text2); double score1pk3 = textSimilarity.similarScore(text1, text3); double score2pk3 = textSimilarity.similarScore(text2, text3); String sim1 = textSimilarity.simHash("我的兴趣爱好是看书"); String sim2 = textSimilarity.simHash("看书是我的兴趣爱好"); LOGGER.info("我的兴趣爱好是看书"+"和看书是我的兴趣爱好的汉明距离是:"+textSimilarity.hammingDistance(sim1,sim2)); System.out.println(text1+" 和 "+text2+" 的相似度分值:"+score1pk2); System.out.println(text1+" 和 "+text3+" 的相似度分值:"+score1pk3); System.out.println(text2+" 和 "+text3+" 的相似度分值:"+score2pk3); }}运行结果, “我的兴趣爱好是看书” 和 “看书是我的兴趣爱好” 的汉明距离是 0 :

检索工具
基于 SimHashBaseOnWord 类实现的检索工具类 SearchBaseOnSimHash 的完整代码:
public class SearchBaseOnSimHash { // 常量定义:数据库中相似记录的 id public static final String idKey = "id"; // 常量定义:数据库中相似记录的 simHash 指纹 public static final String fingerKey = "finger"; // 日志记录类 private static final Logger LOGGER = LoggerFactory.getLogger(SearchBaseOnSimHash.class); // 相似的汉明距离阀值 private static int similarityThreshold = 3; /** * 根据 SimHash 值检索文本相似的记录编号,算法流程: * 1、将 SimHash 分成四段,以每一段为 Key 在 全局表中查找当前段的完整指纹 * 2、如果当前 SimHash 匹配到了缓冲中某一段的信息,则计算改匹配段的指纹和当前指纹的距离 * 3、如果距离小于相似度阀门值,则视为找到,返回对象; * 4、否则,视为无相似记录 * @param segments 分段 * @param simHash * @return */ public static JSONObject search(String [] segments , String simHash) { if(segments == null || segments.length != 4) { return null; } // 创建一个 SimHash 对象,用于计算汉明距离 SimHashBaseOnWord simHashByWord = new SimHashBaseOnWord(); // 逐段遍历,查找计算文本相似的记录 long start = System.currentTimeMillis(); for (int i= 0; i hashSets = RedisUtil.get(segments[i]); if(hashSets == null) { continue; } // 匹配到某一段,则计算汉明距离 String finger = hashSets.get(fingerKey); int hammingDistance = simHashByWord.hammingDistance(finger, simHash); if (hammingDistance <= similarityThreshold){ long end = System.currentTimeMillis(); JSONObject responseObj = new JSONObject(); responseObj.put(idKey, hashSets.get(idKey)); return responseObj; } } return null; } /** * 向索引中添加一个 SimHash 的记录,分段遍历,将各个段加入缓存 * @param segments 分段,因为分段信息在 search 和 push 是都会用到,为了避免重复操作,作为参数 * @param simHash * @param data */ public static void push(String[] segments,String simHash, JSONObject data) { if(segments == null || segments.length != 4) { return; } Map redisData = new HashMap<>(); redisData.put(fingerKey, simHash); redisData.put(idKey, data.getString(idKey)); for (int i= 0; i启示录
理论上,基于 SimHash 的文本相似度对于越长的文本,计算结果才会越精确,但是用 wrod 分词实现的算法,长文本和短文本都比较准确,为什么呢?
分析它的启动日志:
起始加载
词数

检索统计
可以得知一二:
- 资源词数量大;
- 分词过程中自动进行词频统计、自动计算权重;
- 属于“重量级”的工具,计算耗时相对其他分词工具,会长一些。