有没有做网页接单的网站学it学费大概多少钱
近期,人工智能专家Animesh Karnewar提出FAGAN——完全注意力机制(Full Attention)GAN,实验的代码和训练的模型可以在他的github库中找到:
https://github.com/akanimax/fagan。
这个fagan示例使用了我创建的名为“attnganpytorch”的包,该包在我的另一个存储库中可以找到:
https://github.com/akanimax/attnganpytorch。

FAGAN: Full Attention GAN
介绍
在阅读了SAGAN (Self Attention GAN)的论文后,我想尝试一下,并对它进行更多的实验。由于作者的代码还不可用,所以我决定为它编写一个类似于我之前的“pro-gan-pth”包的一个package。我首先训练了SAGAN论文中描述的模型,然后意识到,我可以更多地使用基于图像的注意机制。此博客是该实验的快速报告。
SAGAN 论文链接:
https://arxiv.org/abs/1805.08318
Full Attention 层
SAGAN体系结构只是在生成器和DCGAN体系结构的判别器之间添加了一个self attention层。此外,为了创建用于self attention的Q、K和V特征库,该层使用(1 x 1)卷积。我立即提出了两个问题:注意力(attention)能否推广到(k x k)卷积? 我们能不能创建一个统一的层来进行特征提取(类似于传统的卷积层)并同时进行attention?
我认为我们可以使用一个统一的注意力和特征提取层来解决这两个问题。我喜欢把它叫做full attention层,一个由这些层组成GAN架构就是一个Full Attention GAN.。
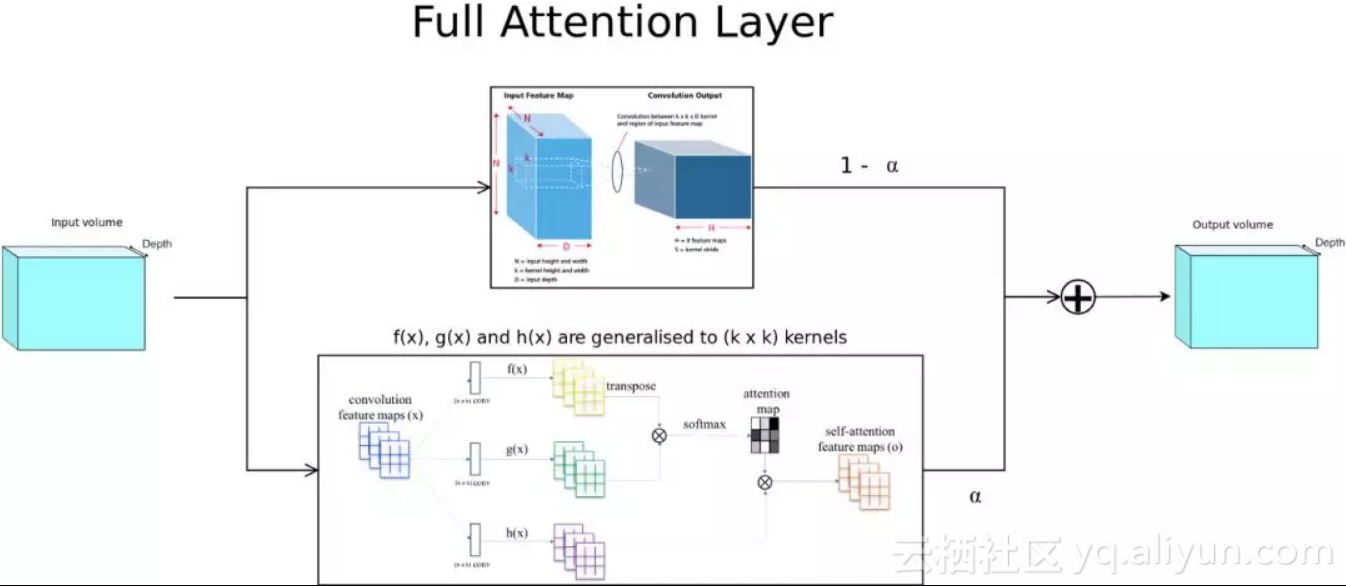
图2:我所提出的full attention层
图2描述了所提出的full attention层的体系结构。 正如您所看到的,在上面的路径中,我们计算传统的卷积输出,在下面的路径中,我们有一个注意力层,它泛化成(k x k)卷积滤波器,而不仅仅是(1 x 1)滤波器。残差计算中显示的alpha是一个可训练的参数。
现在为什么下面的路径不是self attention? 其原因在于,在计算注意力图(attention map)时,输入首先由(k×k)卷积在局部聚合,因此不再仅仅是self attention,因为它在计算中使用了一个小的空间邻近区域。 给定足够的网络深度和滤波器大小,我们可以将整个输入图像作为一个接受域进行后续的注意力计算,因此命名为:全注意力(Full Attention)。
我的一些想法
我必须说,当前的“Attention is all you need”的趋势确实是我这次实验背后的主要推动力。实验仍在进行中,但是我真的很想把这个想法说出来,并得到进一步的实验建议。
我意识到训练模型的alpha残差参数实际上可以揭示注意力机制的一些重要特征; 这是我接下来要做的工作。
attnganpytorch包中包含一个在celeba上训练的SAGAN示例,以供参考。该package包含了self attention、频谱归一化(normalization)和所提出的full attention层的通用实现,以供大家使用。所有这些都可以用来创建您自己的体系结构。
原文发布时间为:2018-08-14
本文来自云栖社区合作伙伴“专知”,了解相关信息可以关注“专知”。