qq浏览器直接打开网页seo的流程是怎么样的

小白的数据分析学习之路.我是小白.加油!
第一种情况:前几行比较脏
当excel的列名不在第一行,且第一行或前几行的数据比较脏,如下图

import pandas as pddata = pd.read_excel('C:/tmp/002/People.xlsx')
print('显示表格的列名:', data.columns) # 打印显示表格有哪些列名在python中读取的是这样,默认将第一行数据当作了列名

可以用python这样处理
import pandas as pd#python中默认的是从0开始的,第0行的数据比较脏,第二行为1,所以header=1
data = pd.read_excel('C:/tmp/002/People.xlsx' ,header=1)
print('显示表格的列名:', data.columns) # 打印显示表格有哪些列名结果显示为,如图

第二种情况:没有列名,但是我们自己知道每一列的含义是什么,如图

python读取结果,将excel数据的第一行当作了列名
import pandas as pddata = pd.read_excel('C:/tmp/002/People.xlsx' )
print('显示表格的列名:', data.columns) # 打印显示表格有哪些列名
我们可以这样处理,header=None,不显示columns.但是python默认给加上1,2,3,4,5,6作为列名。
import pandas as pddata = pd.read_excel('C:/tmp/002/People.xlsx',header=None )
print('显示表格的列名:', data.columns) # 打印显示表格有哪些列名
怎么处理呢?我们可以将我们自己知道的每列的含义,给各个列命名。
import pandas as pddata = pd.read_excel('C:/tmp/002/People.xlsx',header=None )
#加一个list
data.columns=['ID','Type','Title', 'FirstName','MiddleName','LastName']
print('显示表格的列名:', data.columns) # 打印显示表格有哪些列名显示结果为

第三:将编辑好列名的数据,存入excel
import pandas as pddata = pd.read_excel('C:/tmp/002/People.xlsx',header=None )
#加一个list
data.columns=['ID','Type','Title', 'FirstName','MiddleName','LastName']
data.to_excel('C:/tmp/002/data.xlsx')
print('OK')
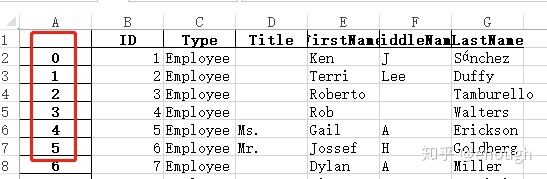
我们发现,新生成的excel文件,默认生成了索引。用set_index()重设索引 方法1
import pandas as pddata = pd.read_excel('C:/tmp/002/People.xlsx',header=None )
#加一个list
data.columns=['ID','Type','Title', 'FirstName','MiddleName','LastName']
data=data.set_index('ID')
data.to_excel('C:/tmp/002/data.xlsx')
print('OK')方法2
import pandas as pddata = pd.read_excel('C:/tmp/002/People.xlsx',header=None )
#加一个list
data.columns=['ID','Type','Title', 'FirstName','MiddleName','LastName']
#data=data.set_index('ID')#生成新的DataFrame
data.set_index('ID',inplace=True)#inplace=True 在原有的数据上改,不生成新的
data.to_excel('C:/tmp/002/data.xlsx')
第四:但是如果回过头来 我们重新用 python读取新生成的data文件时 我们会发现,id列重新变成了普通列。
import pandas as pddata = pd.read_excel('C:/tmp/002/data.xlsx' )
print(data.head())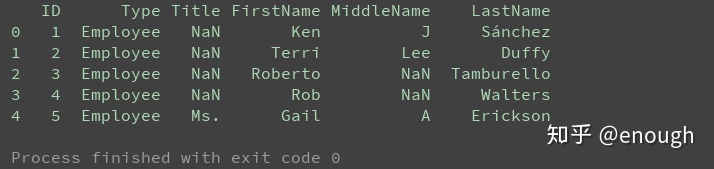
当我们把数据重新生成一个excel的时候 发现,索引又重新生成了
import pandas as pddata = pd.read_excel('C:/tmp/002/data.xlsx' )
data.to_excel('C:/tmp/002/data2.xlsx')
print('ok')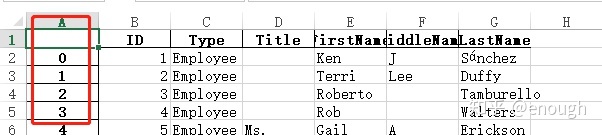
解决方法,当我们自己知道当前数据的索引是那一列的时候,用index_col=('ID'),指明一下 。
重新运行python,结果如下图显示,ok
import pandas as pddata = pd.read_excel('C:/tmp/002/data.xlsx',index_col='ID' )
data.to_excel('C:/tmp/002/data2.xlsx')
print('ok')
.