win2003 wordpress景德镇seo
快速搞定字符串提取1-两侧提取英文、数字
上篇最后留下的一个问题你做出来了吗?
我相信大部分小伙伴都做出来了,其实只需要LEFT和RIGHT换一下就能搞定的,我就不做演示了。
今天这篇涉及的知识量有点大,请小伙伴们多点耐心看下去,一个案例引发多个知识点,先来看一下今天的需求:
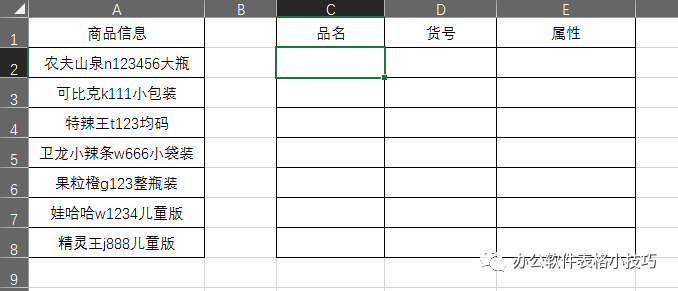
A列是包含“品名”“货号”及“商品属性”的信息源,规则是:
第一个英文之前的字符串是品名
第一个英文到最后一个数字为货号
最后一个数字之后为商品的属性
先来看结果,结果之后是讲解:
C2单元格输入:
=MIDB(A2,1,SEARCHB("?",A2)-1)
注:其中的问号是半角符号,很重要
下拉填充
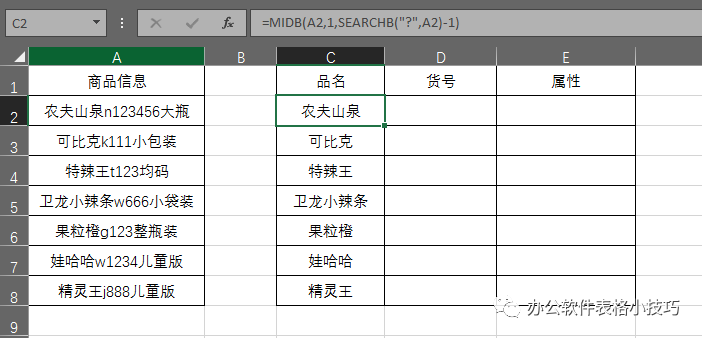
D2单元格输入:
=MID(A2,LEN(C2)+1,LOOKUP(1,0/MID(A2,ROW($1:$99),1),ROW($1:$99))-LEN(C2))
下拉填充
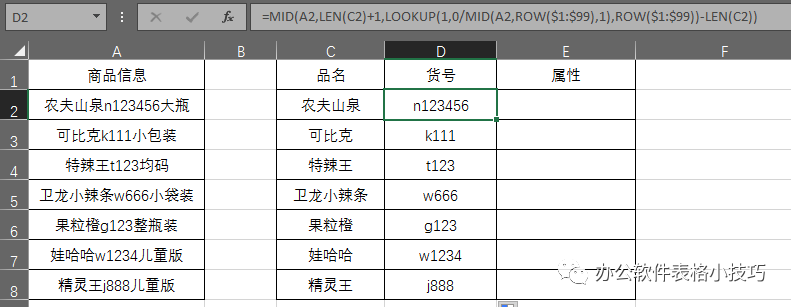
E2单元格输入:
=SUBSTITUTE(A2,C2&D2,""),下拉填充
先来了解几个函数:
LOOKUP(查找的值,查找的范围,返回值的范围)
MIDB/MID(字符串,截取开始位数,需截取位数)
其中MIDB,全角字符为2个字节,半角字符为1个字节,汉字为全角字符。mid则一概计数为1.
SUBSTITUTE(要替换的文本,旧文本,新文本,[替换第几个])
SEARCHB(要查找的文本,要在其中查找文本的文本,要开始查找的位置)
其中,全角字符占2个字节,半角字符占1个字节。
先来看C列获取品名的公式,以C2为例:
SEARCHB("?",A2),这一步半角的问号,起到通配符的作用代表查找第一个1个字节的字符所在位置,本例中半角问号代表的就是货号的"n"所在的位置,上篇讲到过汉字及全角符号是占2个字节,又因SEARCHB是按字节计数,所以一个汉字计数为2,4个汉字计数为8,那么"n"在第九个,所以结果返回9再减去1得到"n"前一位的位数。
把以上结果带入公式就等于MIDB("农夫山泉n123456大瓶",1,9-1),这样就很好理解了,midb函数中一个汉字占2位,四个汉字就占8位,结果返回"农夫山泉"。
当然这个公式也可以换成MID的写法:
=MID(A2,1,(SEARCHB("?",A2)-1)/2)
因为mid函数一概计数为1,所以我们把SEARCHB的结果除以2,转换成以1计数的形式供mid取值。
再来看D列获取货号的公式,以D2为例:
LOOKUP(1,0/MID(A2,ROW($1:$99),1),ROW($1:$99))
这个是lookup一个很经典的用法:查找最后一个数字所在的位数
首先MID(A2,ROW($1:$99),1)会将A2单元格拆分成包含99个元素的数组,无内容记为空(当然如果你知道你的数据源绝对不会超过多少位的时候你可以99换成那个“多少”,为了保险起见一般都会写的大一点)返回结果如下:

然后用0挨个除以数组中的每个元素,如果0除以汉字或者英文肯定返回错误值,而如果0除以数字则返回0,结果如下:

用LOOKUP查找1在这个数组中的位置,但始终查不到,于是返回最后一个0值的位置,从而得出最后一个数字的位置,即返回11
带入公式就好理解了
C2是品名,有4位,所以公式中的len(c2)全部换成4
=MID("农夫山泉n123456大瓶",4+1,11-4)
也就是提取"农夫山泉n123456大瓶"这个字符串第5位开始共7位的字符串,即返回值为"n123456"
最后来看E列获取商品属性的公式,以D2为例:
"&"是一个连接符,可以将两个字符串连接成一个,比如1&2,结果为12
C2&D2,就等于把C2和D2两个单元格的字符串连接起来,返回值便是"农夫山泉n123456"
SUBSTITUTE(A2,C2&D2,"")等同于SUBSTITUTE("农夫山泉n123456大瓶","农夫山泉n123456","")
意思就是将"农夫山泉n123456大瓶"中的"农夫山泉n123456"替换为空,返回值便是"大瓶"(两个连续半角双引号是空的意思)
今天这篇文章相对来说有点绕,可能基础比较差的小伙伴看的云里雾里的,没关系,只要你的原数据是汉字+英文+数字+汉字的格式,这几个公式尽管拿去用都可以实现结果的。
希望我的分享能给你节省出喝杯咖啡的时间,也感谢你的关注和支持!
本次的分享就到这里!
