互联网有多少网站济南网站推广
在使用传统的RDBMS数据库(关系数据库),例如MySql时,对于一些大表,我们通常会进行分表操作,以提升查询效率。在Hive中也提供了类似的概念和操作,本文将对其进行讲述。
RDBMS中的分表操作
假设有一张订单表OrderInfo,简化一下,字段分别为:订单Id OrderId、卖家 Retailer、买家 Customer、订单金额 OrderAmount、下单日期 OrderDate。比较常见的做法有两种:一种是按年分表,例如建OrderInfo_2018、OrderInfo_2017。按年分表的问题是如果查询不基于时间,例如查询某个单号、查询某个买家/卖家的所有订单,则依然要全表查找(所有按年分的表都要查)。类似地,也可以按卖家进行分表。按卖家分表(或者类似的其他字段)的问题在于:数据分布不一致,会造成有的表数据极多,有的表数据极少。
可以实际地建两张表 OrderInfo_2018、OrderInfo_2017,也可以隐式地建,对数据库的上层应用不可见(表名仍然为OrderInfo)。隐式建表有时会有一些限制,也需要对数据库有更深一些的了解,因此,很多开发人员直接显式地创建多张不同表。
还有一种是按单号的Hash值取模进行分表,假设分4张表(OrderInfo_0~OrderInfo_3),那么具体某个订单存入哪张表,规则是 Hash(OrderId)%4,根据余数决定存入那张表。根据这种方式分表,优点是可以提升基于单号的查找速度,以及对于单号的join连接查询。但是如果针对某个买家或者时间段来查询,又需要全表查询。使用这种方式还有一个缺陷就是不好扩表,假设开始时设计了4张表(除4取余),后来单表数据仍然很多,想要重新改为8张表(除8取余),此时就需要将现有表中的记录重新进行计算并迁移到对应的表中。
这两种方式,第一种可以视为连续的(基于时间连续,或者基于某个列连续,比如卖家),第二种则为离散的。有一种间接的改进策略可以集成两种方式的优点,称为异构索引表。具体可以参看这里:企业IT架构转型之道。
Hive中的表分区
Hive中的表分区和上面RDBMS的第一种方式极为类似,用来对连续的数据进行分区。Hive中的表存储在HDFS上,HDFS是一个分布式文件系统,通过目录来对文件进行组织和管理。Hive中的一张表对应HDFS上的一个或者多个文件。创建一个Hive的表分区,相当于在HDFS上创建了几个目录,分别存储表中对应的数据。
继续通过上面订单的例子来查看一下,假设我们按照年(Year)和卖家(Retailer),使用下面的语句创建EShop库,并在该库中创建OrderInfo表:
关于HDFS和Hive环境的搭建,可以查看这两篇文章:安装和配置Hive, 安装和配置Hadoop(单节点)
CREATE DATABASE IF NOT EXISTS Eshop; CREATE TABLE IF NOT EXISTS Eshop.OrderInfo ( OrderId int, Customer string, OrderAmount int, OrderDate Timestamp ) PARTITIONED BY(Year string, Retailer string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ STORED AS TEXTFILE;
这里需要注意的是表的定义中没有了Retailer字段,因为同一个分表中的Retailer都是一样的,所以将它作为数据列存在表中也就没有了意义,只需要存在“表名”中就可以了。假设Retailer是Apple和XiaoMi,如果是RDBMS,可以这样建表 OrderInfo_Apple、OrderInfo_XiaoMi,此时就不需要再将Apple和XiaoMi的值存到表中,因为表中的值都一样。但这样会带来查询问题,当需要以select columns from table的方式统一获取时又不方便。Hive巧妙地解决了这个问题,即将Partition的列作为虚拟列,虽然实际上不存数据,但是在查询的时候却可以直接使用select来查询。
接下来,插入一些数据进行测试,假设有这样一批数据:
OrderId
Retailer
Customer
OrderAmount
OrderDate
1
Apple
Jimmy
5200
2017-10-01 00:00:00
2
Apple
Jack
3180
2017-11-01 00:00:00
3
XiaoMi
Jimmy
2010
2017-12-01 00:00:00
4
XiaoMi
Alice
980
2018-10-01 00:00:00
5
XiaoMi
Eva
1080
2018-10-20 00:00:00
6
XiaoMi
Ellie
680
2018-11-01 00:00:00
7
Apple
Alice
920
2018-12-01 00:00:00
那么再插入时,就需要提前分好组(实际应用中都是通过写代码来进行分组),然后分四次插入:
INSERT INTO TABLE EShop.OrderInfo PARTITION(Year=”2017″, Retailer=”Apple”) VALUES (1, ‘Jimmy’, 5200, ‘2017-10-01 00:00:00’), (2, ‘Jack’, 3180, ‘2017-11-01 00:00:00’); INSERT INTO TABLE EShop.OrderInfo PARTITION(Year=”2017″, Retailer=”XiaoMi”) VALUES (3, ‘Jimmy’, 2010, ‘2017-12-01 00:00:00’); INSERT INTO TABLE EShop.OrderInfo PARTITION(Year=”2018″, Retailer=”Apple”) VALUES (7, ‘Alice’, 920, ‘2018-12-01 00:00:00’); INSERT INTO TABLE EShop.OrderInfo PARTITION(Year=”2018″, Retailer=”XiaoMi”) VALUES (4, ‘Alice’, 980, ‘2018-10-01 00:00:00’), (5, ‘Eva’, 1080, ‘2018-10-20 00:00:00’), (6, ‘Ellie’, 680, ‘2018-11-01 00:00:00’);
插入完成后,执行下面的select查询:
hive > select OrderId, Retailer, Customer, OrderAmount, OrderDate, Year from EShop.OrderInfo; OK 1 Apple Jimmy 5200 2017-10-01 00:00:00 2017 2 Apple Jack 3180 2017-11-01 00:00:00 2017 3 XiaoMi Jimmy 2010 2017-12-01 00:00:00 2017 7 Apple Alice 920 2018-12-01 00:00:00 2018 4 XiaoMi Alice 980 2018-10-01 00:00:00 2018 5 XiaoMi Eva 1080 2018-10-20 00:00:00 2018 6 XiaoMi Ellie 680 2018-11-01 00:00:00 2018 Time taken: 0.26 seconds, Fetched: 7 row(s)
可以看到用作分区的虚拟列Year和Retailer也可以包含在Select当中。接下来查看一下HDFS:
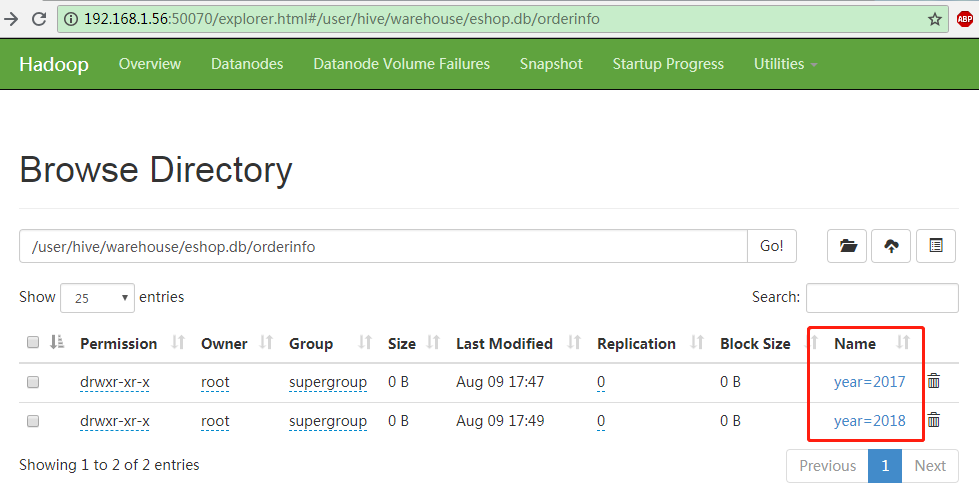 OrderInfo表下的Year分区
OrderInfo表下的Year分区
不管是EShop库,还是OrderInfo表,在HDFS上都只是一个目录,一个文件夹。而year分区和retailer分区也不过是在orderinfo下的子文件夹。
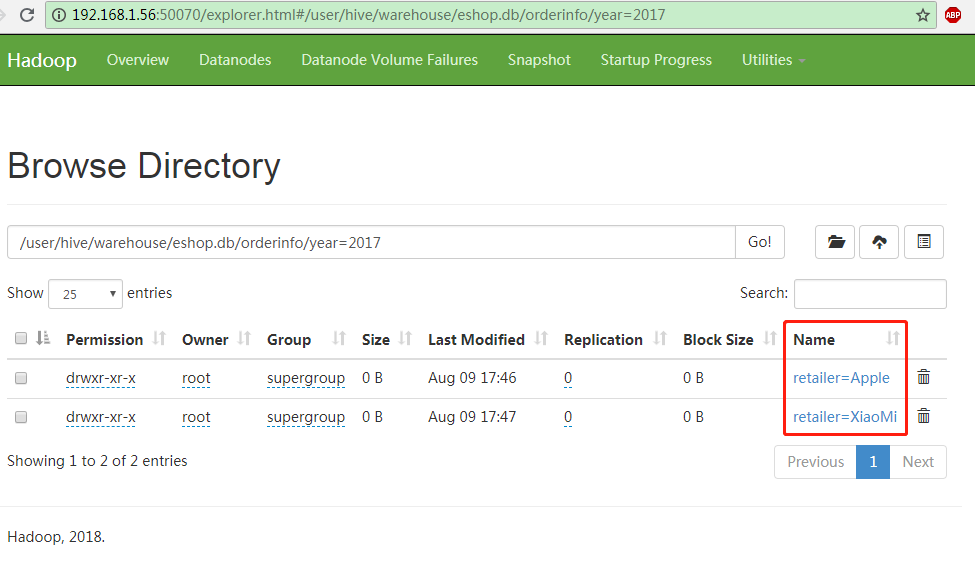 Year分区(目录)下的Retailer分区(目录)
Year分区(目录)下的Retailer分区(目录)
目录的最底层,是实际的数据文件,点击下载后,因为建表时设置的存储格式为TEXTFILE,所以是以纯文本的格式保存。可以使用文本编辑器打开,看到下面的数据:
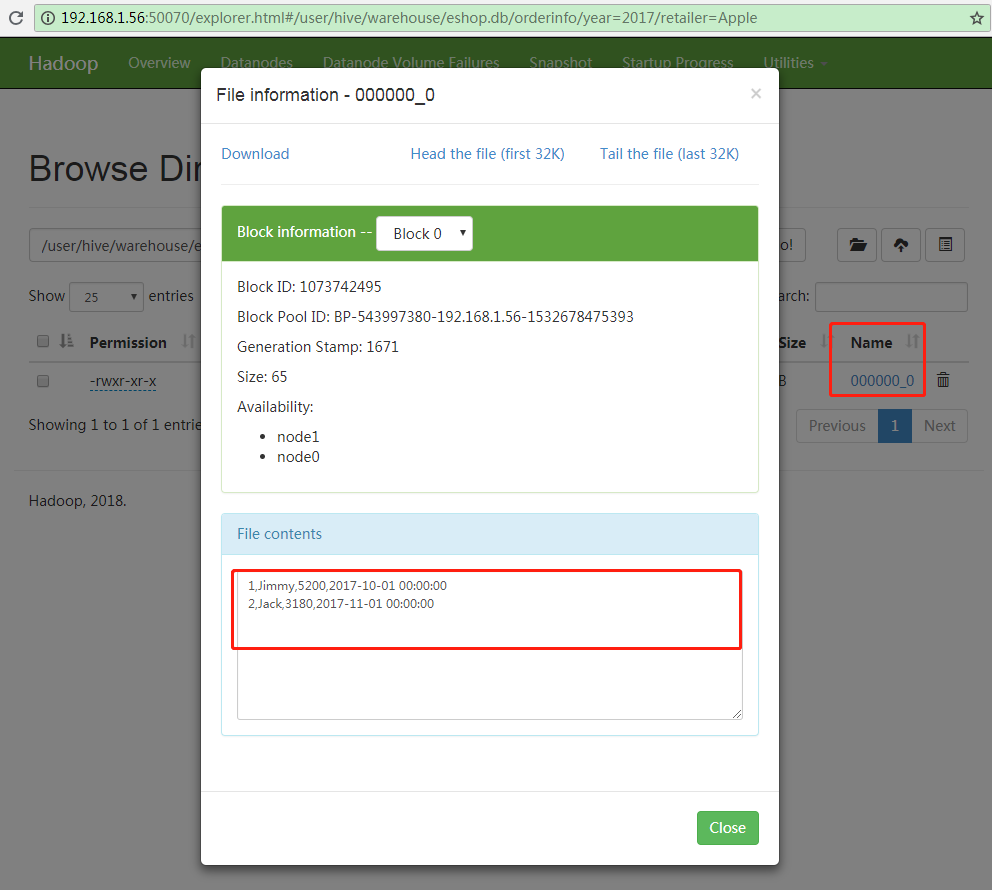 year=2017,retailer=apple分区下的数据文件内容
year=2017,retailer=apple分区下的数据文件内容
Hive中的表分桶
Hive中的分桶和第二种情况类似,它不会像分区那样创建独立的文件夹,而是直接按照桶数去拆分文件。而在插入时,也无需像分区那样指定到哪个桶中。如同上面所述,分桶会基于指定的列进行Hash运算,根据Hash的结果来自动进行分桶(数据归档)。分桶后基于分桶列所做的查询和join操作会有执行效率的优化和提升。
现将前面创建的OrderInfo表删除掉,然后再重新创建:
DROP TABLE EShop.OrderInfo; CREATE TABLE IF NOT EXISTS Eshop.OrderInfo ( OrderId int, Retailer string, Customer string, OrderAmount int, OrderDate Timestamp ) CLUSTERED BY (OrderId) INTO 2 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ STORED AS TEXTFILE;
因为没有分区,所以此时就需要将Retailer字段再加回去。
接下来执行插入操作:
INSERT INTO TABLE EShop.OrderInfo VALUES (1, ‘Apple’, ‘Jimmy’, 5200, ‘2017-10-01 00:00:00’), (2, ‘Apple’, ‘Jack’, 3180, ‘2017-11-01 00:00:00’), (3, ‘XiaoMi’, ‘Jimmy’, 2010, ‘2017-12-01 00:00:00’), (4, ‘XiaoMi’, ‘Alice’, 980, ‘2018-10-01 00:00:00’), (5, ‘XiaoMi’, ‘Eva’, 1080, ‘2018-10-20 00:00:00’), (6, ‘XiaoMi’, ‘Ellie’, 680, ‘2018-11-01 00:00:00’), (7, ‘Apple’, ‘Alice’, 920, ‘2018-12-01 00:00:00’);
继续查看HDFS,可以看到分为了2个文件,一个文件ID全是奇数1,3,5,7,另一个文件ID全是偶数2,4,6。可能因为OrderId为int型,所以没有Hash,就直接根据桶数2进行取模了吧。
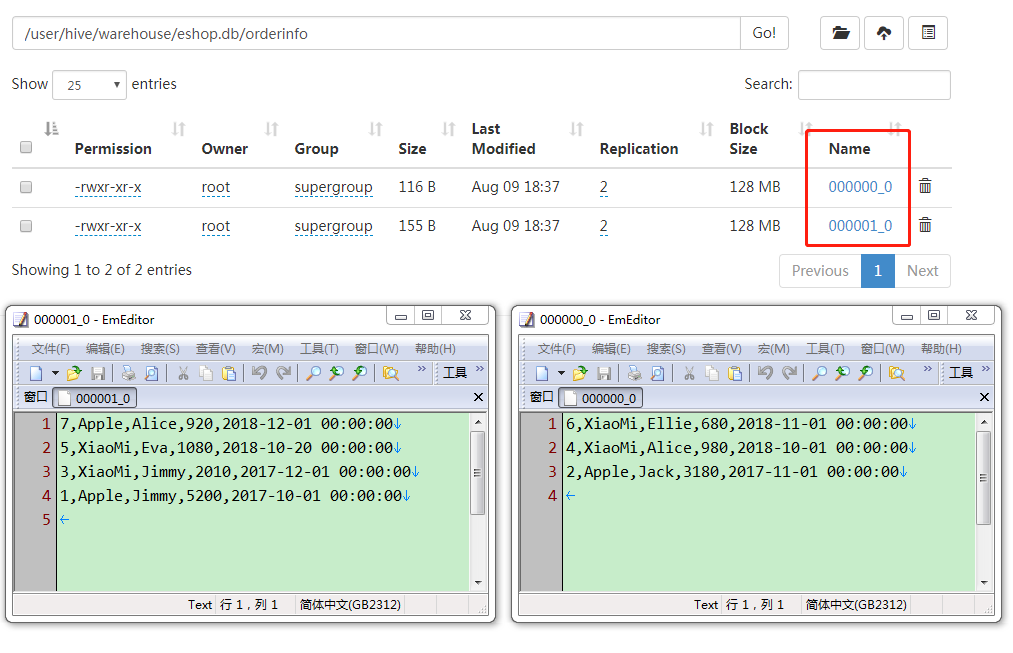 不分区,只进行分桶后的数据
不分区,只进行分桶后的数据
类似地,如果将桶数改为3,文件被分割为:(1,4,7)、(2,5)、(3,6)。
当把Id改为字符串类型,将值设为a~g,再进行分桶的测试,文件被分割为:(a,c,e,g)和(b,d,f)
感谢阅读,希望这篇文章能给你带来帮助!
注意:本文来源网络/媒体,本站无法对本文内容的真实性、完整性、及时性、原创性提供任何保证,
请您自行验证核实并承担相关的风险与后果!
CoLaBug.com遵循[CC BY-SA 4.0]分享并保持客观立场,本站不承担此类作品侵权行为的直接责任及连带责任。
如您有版权、意见、投诉等问题,请通过[eMail]联系我们处理,如需商业授权请联系原作者/原网站。