贸易公司做网站有用吗软件开发

本节将主要介绍InnoDB中涉及的文件类型,以及InnoDB对应的底层存储表的结构。
文件
MySQL数据库中涉及到的文件类型有:
- 参数文件:告诉MySQL实例启动时在哪里可以找到数据库文件,并且指定某些初始化参数,这些参数定义了某些内存结构的大小等设置。
- 日志文件:用来记录MySQL实例对某种条件作出响应时写入的文件,如错误日志、二进制日志文件、慢查询日志文件、查询日志文件等。
- socket文件:当用UNIX域套接字方式进行连接时需要的文件。
- pid文件:MySQL实例的进程ID文件。
- MySQL表结构文件:用来存放MySQL表结构定义文件。
- 存储引擎文件:因为MySQL表存储引擎的关系,每个存储引擎都会有自己的文件来保存各种数据。这些存储引擎真正存储了记录和索引等数据。
上面介绍了6种MySQL数据库中使用到的文件,每种文件的作用大致已经介绍,这里展开介绍一下其中的一些重要文件。
二进制日志文件
二进制日志(binary log)记录了对MySQL数据库执行更改的所有操作,但是不包括select和show这类操作,因为这类操作对数据本身并没有修改。注意,这并非绝对的。在某些情况下,即使操作本身并没有导致数据库发生变化,而该操作页可能会被写入二进制日志中。
二进制日志主要有以下几种作用:
- 恢复(recovery):某些数据的恢复需要二进制日志,例如,在一个数据库全备份文件恢复后,用户可以通过二进制日志进行point-in-time恢复。
- 复制(replication):其原理与恢复类似,通过复制和执行二进制日志使一台远程的MySQL数据库(一般为slave或standby)与一台MySQL数据库(一般称为master或primary)进行实施同步。
- 审计(audit):用户可以通过二进制日志中的信息来进行审计,判断是否有对数据库进行注入的攻击。
二进制日志文件在默认情况下并没有启动,需要手动指定参数来启动。通过配置参数log-bin [ =name ] 可以启动二进制日志。如果不指定name,则默认二进制日志文件名为主机名,后缀名为二进制日志的序列号,所在路径为数据库所在目了(datadir)。
以下配置文件的参数影响着二进制日志记录的信息和行为:
- max_binlog_size:指定单个二进制日志文件的最大值,如果超过该值,则产生新的二进制日志文件。默认大小是1G。
- binlog_cache_size:当使用事务的表存储引擎时,所有未提交的二进制日志会被记录到一个缓存中,等该事务提交时直接将缓存中的二进制日志写入二进制日志文件中,该缓冲的大小由binlog_cache_size决定。
- sync_binlog:默认情况下,二进制日志并不是每次写的时候同步到磁盘(可以理解为缓冲写)。参数sync_binlog=[ N ]表示每写缓冲多少次就同步到磁盘。
- binlog-do-db和binlog-ignore-db 表示需要写入或忽略写入哪些库的日志。默认为空,表示需要同步所有库的日志到二进制日志。
- log-slave-update:如果当前数据库是复制中的slave角色,则它不会将从master取得并执行的二进制日志写入自己的二进制日志文件中去。如果需要写入,要设置log-slave-update。
- binlog_format:该参数十分重要,它影响着记录二进制日志的格式。可取的值有:
- STATEMENT:该格式表示二进制日志文件记录的是日志的逻辑SQL语句。
- ROW:在ROW格式下,记录的是表的行更改情况。
- MIXED:在该格式下,MySQL默认采用STATEMENT格式进行日志文件的记录,但是在一些情况下会使用ROW格式,可能的情况有:
- 表的存储引擎为NDB,这时对表的DML操作都会以ROW格式记录。
- 使用了UUID()、USER()、CURRENT_USER()、FOUND_ROWS()、ROW_COUNT()等不确定函数。
- 使用了 insert delay语句。
- 使用了用户定义函数(UDF)。
- 使用了临时表(temporary table)。
在通常情况下,我们将参数binlog_format设置为ROW,这可以为数据库的恢复和复制带来更好的可靠性。但是有一点需要注意:有些语句下ROW格式可能需要更大的容量,所以对磁盘空间要求有一定的增加,在复制的时候,网络开销也将增大。
MySQL表结构定义文件
因为MySQL插件式存储引擎的体系结构的关系,MySQL数据库的存储是根据表进行的,每个表都会有与之对应的文件。但是不论表采用何种存储引擎,MySQL都会有一个以frm为后缀名的文件,这个文件记录了该表的表结构定义。
InnoDB存储引擎文件
表空间文件 InnoDB采用将存储的数据按表空间进行存放的设计。在默认配置下会有一个初始化大小为10MB,名为ibdata1的文件。该文件就是默认的表空间文件,用户可以通过参数innodb_data_file_path对其进行设置,用户可以通过对个文件组成一个表空间,同时制定文件的属性,如下:
[上例将/db/ibdata1和/dr2/ibdata2两个文件用来组成表空间。若这两个文件位于不同的磁盘上,磁盘的负载可能会被平均,因此提高数据库的整体性能。其中,文件ibdata1的大小为200MB,文件ibdata2大小为200MB,如果用完了这200MB,该文件可以自动增长(autoextend)。
如果设置了innodb_data_file_path参数后,所有基于InnoDB存储引擎的表的数据都会记录到该共享表空间中。
若设置了参数innodb_file_per_table,则用户可以将每个基于InnoDB存储引擎的表产生一个独立表空间。独立表空间的命名规则为:表名.ibd。通过这样的方式,用户不用将所有的数据都存放于默认的表空间中。
下图显示了InnoDB存储引擎对于文件的存放方式。由于设置了参数innodb_file_per_table=ON,因此产生了单独的 .ibd 独立表空间文件。*需要注意的是:这些单独的表空间文件仅存放该表的数据、索引和插入缓冲Bitmap等信息,其余信息还是存放在默认的表空间中,比如回滚(undo)信息、插入缓冲索引页、系统事务信息、二次写缓冲等。
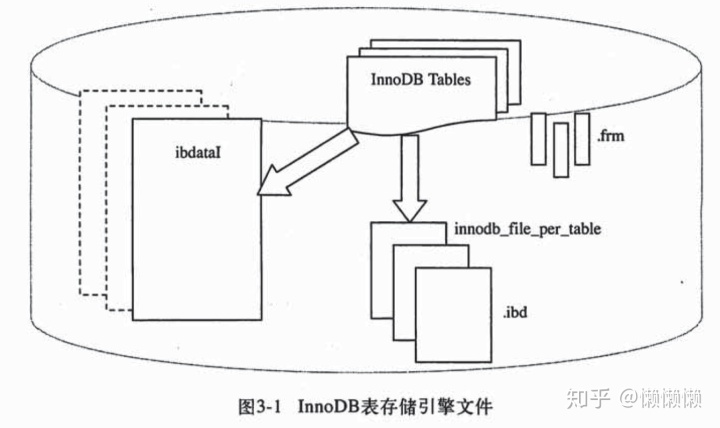
重做日志文件 在默认情况下,在InnoDB存储引擎的目录下会有两个名为ib_logfile0 和 ib_logfile1的文件。每个InnoDB存储引擎至少有1个重做日志文件组,每个文件组下至少有两个重做日志文件。InnoDB存储引擎先写重做日志文件0,当达到文件的最后时,会切换到重做日志文件1,当日志文件1写满时,会再切换到日志文件0中。
重做日志文件对于InnoDB存储引擎至关重要,它们记录了对于InnoDB存储引擎的事务日志,当实例或介质失败时,InnoDB存储引擎会使用重做日志文件回到到失败前的数据库状态,以此来保证数据的完整性。
其与之前介绍的二进制日志的区别是什么呢?
首先,二进制日志文件会记录所有与MySQL数据库有关的日志,包括InnoDB、MyISAM、Heap等其他存储引擎的日志。而InnoDB存储引擎的重做日志文件只记录与该存储引擎本身的事务日志。
其次,记录的内容不同。二进制日志记录的是关于一个事务的具体操作内容,即该事务的逻辑日志,而InnoDB存储引擎的重做日志文件记录的是关于每个页(Page)的更改物理情况。
此外,写入的时间也不同。二进制日志文件仅在事务提交前进行提交,即只写磁盘一次,不论该事务多大。而在事务进行过程中,却不断有重做日志条目被写入到重做日志文件中。
关于重做日志在后面的章节会有详细介绍,现在只做一个大致了解。
表
接下来将从InnoDB存储引擎表的逻辑存储及实现进行介绍。简单来说,表就是关于特定实体的数据集合,这也是关系型数据库模型的核心。
索引组织表
在InnoDB存储引擎中,表都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table)。在InnoDB存储引擎表中,每张表都有个主键(Primary key),如果在创建时没有显示定义主键,则会按照如下方式选择或创建主键: 首先判断表中是否有非空的唯一索引(unique not null),如果有,则该列即为主键。当表中有多个非空唯一索引时,选择建表时第一个定义的非空唯一索引为主键。 如果不符合上述条件,InnoDB存储引擎自动创建一个6字节大小的指针。
InnoDB逻辑存储结构
如下图所示:
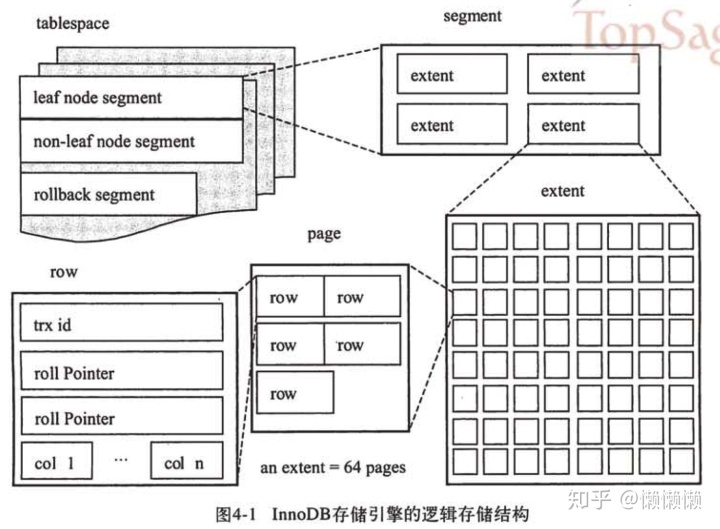
从InnoDB存储引擎的逻辑结构看,所有的数据都被逻辑地存放在一个空间中,称为表空间(tablespace)。表空间又由段(segment)、区(extent)、页(page)组成。页在一些文档中有时也称为块(block)。
1. 表空间
表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。前面提到过,默认情况下,InnoDB存储引擎有一个共享的表空间ibdata1,即所有数据都存放在这个表空间中。如果用户启用了参数innodb_file_per_table,即每张表内的数据可以单独放到一个表空间内。
2. 段
常见的段有数据段、索引段、回滚段等。
前面已经介绍了InnoDB存储引擎表是索引组织的,因此数据即索引,索引即数据。那么数据段即为B+树的叶子节点,索引段即为B+树的非叶子节点,回滚段比较特殊,将在后面的章节介绍。
在InnoDB中,对段的管理是由引擎自身所完成,DBA不能也没有必要对其进行控制。
3. 区
区由连续页组成的空间,在任何情况下每个区的大小都是1MB。为了保证区中页的连续性,InnoDB存储引擎一次从磁盘申请4~5个区。在默认情况下,InnoDB存储引擎页的大小为16KB,即一个区中一共有64个连续的页。
4. 页
页是InnoDB磁盘管理的最小单位,在InnoDB存储引擎中,默认的每个页大小为16KB。从InnoDB 1.2.x版本开始,可以通过参数innodb_page_size将页的大小设置为4K、8K、16K。若设置完成,则所有表中页的大小都为innodb_page_size。不可以对其再次进行修改。
5. 行
InnoDB存储引擎记录是以行的形式存储的,这意味着页中保存着表中一行行的数据。在InnoDB 1.0.x版本之前,InnoDB存储引擎提供了Compact和Redundant两种格式来存放行记录数据,这也是目前使用最多的一种格式。
Compact 行记录格式
Compact行记录格式在MySQL 5.0中引入,其设计目标是高效地存储数据,简单来说,一个页中存放的行数据越多,其性能越高。其存储方式如下:

从上图可知,Compact行记录格式的首部是一个非NULL变长字段长度列表,并且是按照列的顺序逆序放置的,其长度为: 若列的长度小于255字节,用1字节表示 若大于255字节,用2字节表示
变长字段的长度最大不可以超过2字节,这是因为MySQL数据库中varchar类型的最大长度限制为65535。
第二部分是NULL标志位,该位指示了该行记录中是否有NULL值,有则用1表示。该部分占1字节。
记录头信息(record header),固定占用5字节(40位),每一位的含义是:
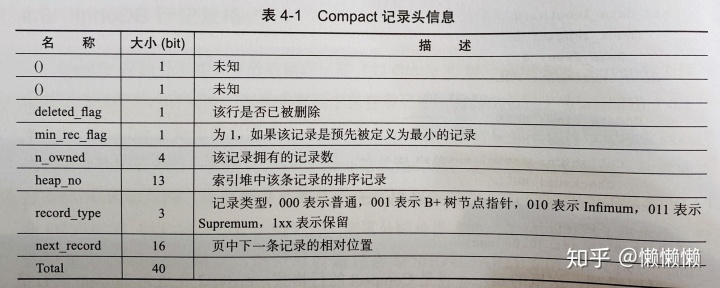
最后是实际每个列的存储数据。需要注意的是:NULL除了占有NULL标志位,实际存储不占有任何空间。每一行除了用户定义的列外,还有两个隐藏列:事务ID列和回滚指针列,分别为6字节和7字节大小。若用户没有定义主键,每行还会增加一个6字节的rowid列。
InnoDB数据页结构
前面已经提到,页是InnoDB存储引擎管理数据库的最小磁盘单元,而常见的页类型有:
- 数据页(B-tree Node)
- undo页(undo log page)
- 系统页(system page)
- 事务数据页(transaction system page)
- 插入缓冲位页图(insert buffer bitmap)
- 插入缓冲空闲列表页(insert buffer free list)
- 未压缩的二进制大对象页(uncompressed blob page)
- 压缩的二进制大对象页(compressed blob page)
数据页中存放的是表中行的实际数据。因此,看下数据页的组成:
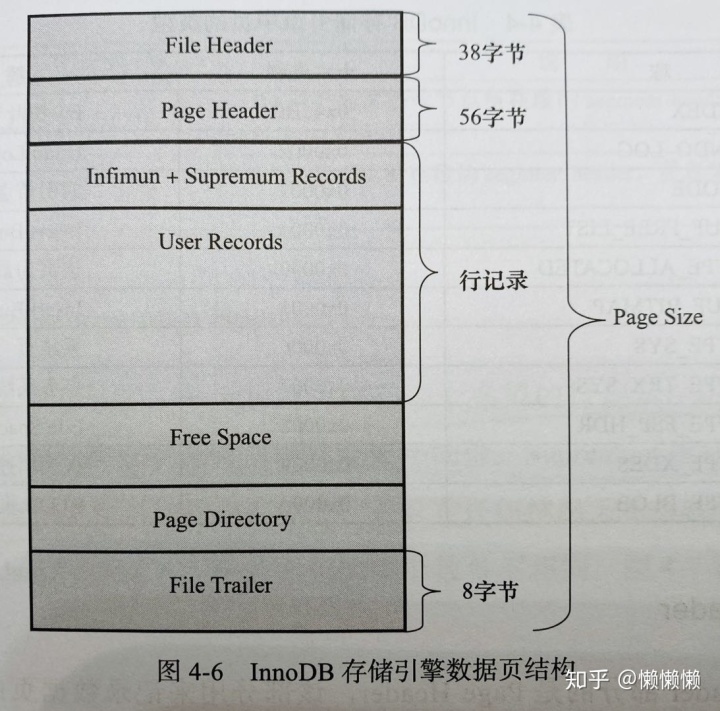
如图,一共有7个部分:
- file header,文件头
- page header,页头
- Infimun 和 supremum records
- user records,用户记录,即行记录
- free space,空闲空间
- page directory,页目录
- file trailer,文件结尾信息
File Header用来记录页的一些头信息,固定占用38字节。
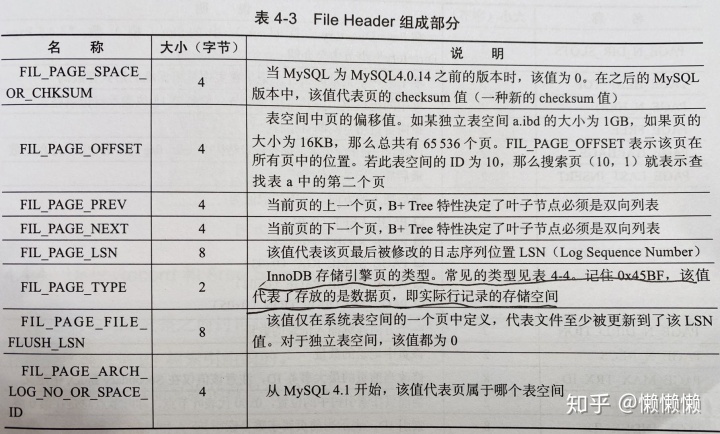
Page Header用来记录数据页的状态信息,由14个部分组成,共占用56字节。

在InnoDB存储引擎中,每个数据页中都有两个虚拟的行记录,用来限定记录的边界。Infimum记录是比该页中任何主键值都要小的值,Supremum指比任何可能大的值还要大的值。这两个值在页创建时被建立,在任何情况下都不会被删除。
User Records就是前面讨论过的部分,即实际存储行记录的内容。再次强调,InnoDB存储引擎表总是以B+树索引组织的。 Free Space指空闲空间,同样也是个链表数据结构,在一条记录被删除后,该空间会被加入到空闲链表中。
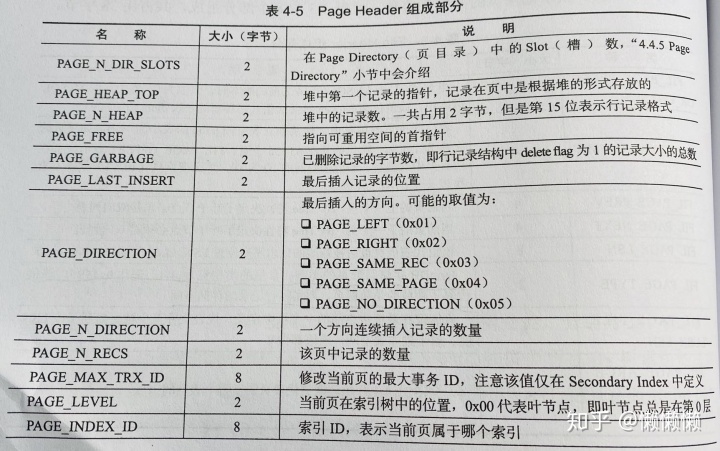
Page Directory(页目录)中存放了记录的相对位置(注意,这里存放的是页相对位置,而不是偏移量)。有些时候这些记录指针称为Slots(槽)或目录槽。
在InnoDB中并不是每一个记录拥有一个槽,InnoDB存储引擎的槽是一个稀疏目录,即一个槽中可能包含多个记录。伪记录infimum的n_owned值总是1(n_owned为Compact行记录Record Header中的字段)。记录Supremum的n_owned的取值范围是[1, 8],其他用户记录o_owned的取值范围为[4, 8]。当记录被插入或删除时,需要对槽进行分裂或平衡的维护操作。
由于InnoDB存储引擎中Page Directory是稀疏目录,二叉查找的结果只是一个粗略的结果,因此,InnoDB存储引擎必须通过recorder header中的next_record来继续查找相关记录。需要牢记:B+树索引本身并不能找到具体的一条记录,能找到的只是该记录所在的页。数据库把页载入内存,然后通过Page Directory再进行二叉查找,只不过二叉查找的时间复杂度很低,同时在内存中查找很快,所以通常忽略这部分查找所用的时间。
File Trailer:只有一个FIL_PAGE_END_LSN部分,占用8字节。前4字节代表该页的checksum值,最后4字节和File Header中的FIL_PAGE_LSN相同。将这两个值与File Header中的FIL_PAGE_SPACE_OR_CHKSUM和FIL_PAGE_LSN的值比较,看是否一致,以此来保证页的完整性。checksum的比较不是简单的等值比较,而是通过InnoDB的checksum函数来进行比较。
约束
关系型数据库和文件系统的一个不同点是:关系型数据库本身能保证存储数据的完整性,不需要应用程序的控制,而文件系统一般需要在程序端进行控制。
一般来说,数据完整性由以下三种形式:
- 实体完整性保证表中只有一个主键。在InnoDB存储引擎表中,用户可以通过定义Primary key和Unique key约束来保证实体的完整性。用户还可以通过编写一个触发器来保证数据完整性。
- 域完整性保证每列的值满足特定条件。在InnoDB存储引擎表中,域完整性可以通过以下几种途径来保证:
- 选择合适的数据类型确保一个数据值满足特定条件
- 外键(foreign key)约束
- 编写触发器
- 可以考虑用default约束作为强制域完整性的一个方面。
- 参照完整性保证两张表之间的关系。InnoDB存储引擎支持外键,因此允许用户定义外键以强制参照完整性,也可以通过编写触发器以强制执行。
约束的创建可以采用以下两种方式:
- 表建立时就进行约束定义
- 利用Alter table命令来进行创建约束
对Unique key(唯一索引)的约束,用户还可以通过命令create unique index来建立。对于主键约束而言,其默认约束名为primary。对于unique key约束而言,默认约束名和列名一样,当然也可以人为指定unique key的名字。
约束和索引由什么区别呢? 约束是一个逻辑的概念,用来保证数据的完整性,而索引是一个数据结构,既有逻辑上的概念,在数据库中还代表着物理存储的方式。
总结
以上就是关于InnoDB存储引擎表的逻辑存储和实现的相关介绍。
本节主要先介绍了MySQL中比较中要的文件类型,然后重点介绍了二进制日志文件和InnoDB存储引擎的重做日志文件。
随后,介绍了InnoDB存储的引擎的逻辑存储结构,从表空间,到数据页,以及行记录的具体存储形式,针对其中比较关键的部分都做了详细介绍。当然不能把所有细节都讲清楚,感兴趣的可以阅读《MySQL技术内幕:InnoDB存储引擎》。关于本系列InnoDB的相关知识笔者均是参考此书,然后挑取其中部分重点内容,形成了系列文章。
本系列文章最主要的目的,一是作为知识积累,二是希望在行文过程中多看书中没有吃透的细节再深究一下。希望整理完这系列的文章后,对InnoDB存储引擎的理解,可以更近一步。
学习完本节之后,再来看看InnoDB存储引擎是个什么东西呢?
- 首先,它是一个基于磁盘存储的存储引擎,所有的数据都是存放在磁盘上的。数据最小管理单元是页,默认为16KB。
- 然后由于磁盘速度的限制,它引入了一个缓冲池来提速。缓冲池中使用了三个链表来管理池中的页。分别为free list、lru list、flush list。其中lru list在使用的lru算法在传统基础上加入了midpoint策略,其具体值可由相关参数控制。
- 同时引入了Insert Buffer做为辅助索引插入或更新时的优化,doublewrite保证数据刷新回磁盘时的可靠性。
- 再看具体存储。从逻辑上看,从上到下是,表空间,段,区,页,行。而表空间默认有一个共享的表空间ibdata1,所有表都存储在这个空间。但是开启一个参数后,每张表都可以独立存储在一个表空间文件中。但是独立的表空间文件只存表的数据和索引等信息,其他的事务或控制信息等仍然存在共享表空间。
- 段分为数据段和索引段,回滚段。对应的是数据节点,索引节点等。
- 再看页,一个数据页分好几个部分,每页有自己的控制信息,page directory在页内搜索时提速。数据库依靠B+树索引只能找到对应的页,把具体页加载到内存后,依靠页上面的page directory信息,进行二叉查找具体的行记录。
以上,就是学到此刻时,我脑海中的InnoDB存储引擎。还是很模糊,不要紧,继续往下看。下一节将介绍InnoDB存储引擎的索引和算法。