模块,是用一堆代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提高了代码的重用性和代码之间的耦合。对于一个复杂的功能开说,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个.py文件组成的代码集合就称为模块。
例如:os是系统相关的模块;file是文件操作相关的模块
模块分为三种:
1.自定义模块
2.第三方模块
3.内置模块
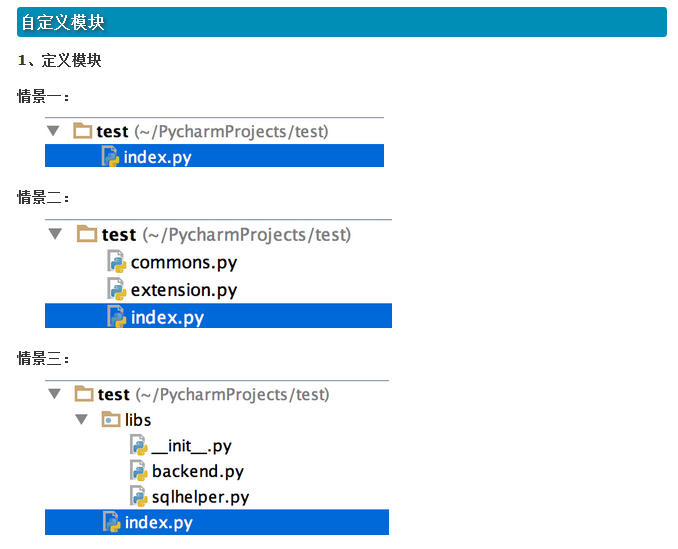
2.导入模块
python之所以应用越来越广泛,在一定程度上也依赖于其为程序猿提供了大量的模块供以使用,如果想要使用模块,则需要导入。导入模块有以下几种方法:
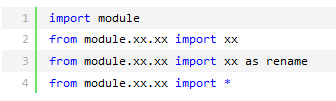
导入模块其实就是告诉python解释器去解释那个py文件
1.导入一个py文件,解释器解释该py文件
2.导入一个包,解释器解释该包下的__init__.py文件【py2.7】
那么问题来了,导入模块时是根据哪个路径做为基准来进行的呢?是根据sys.path
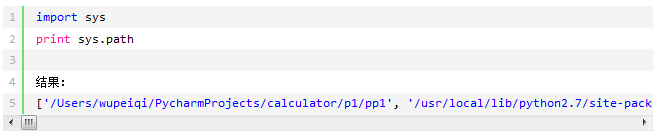
如果在sys.path路径列表里没有想要的路径,可以通过sys.path.append("路径")进行添加


内置模块是python自带的功能,在使用内置模块相应的功能时,需要【先导入】再【使用】
一、sys
用于提供对pytho解释器相关的操作:

进度条

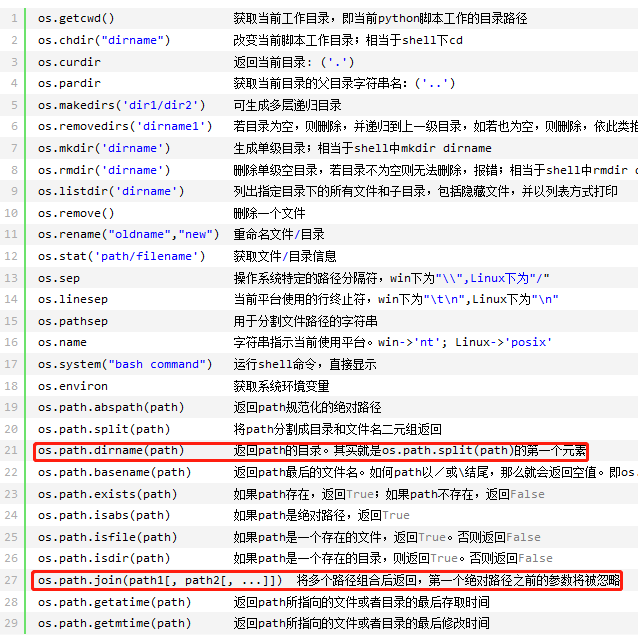
二、os
用于提供系统级别的操作
三、hashlib
用于加密相关的操作,代替了md5模块和sha模块,主要提供SHA1,SHA224,SHA256,SHA384,SHA512,MD5算法
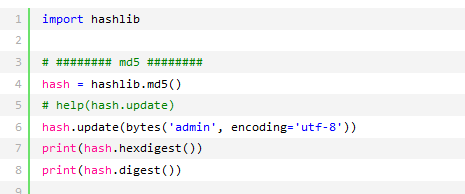
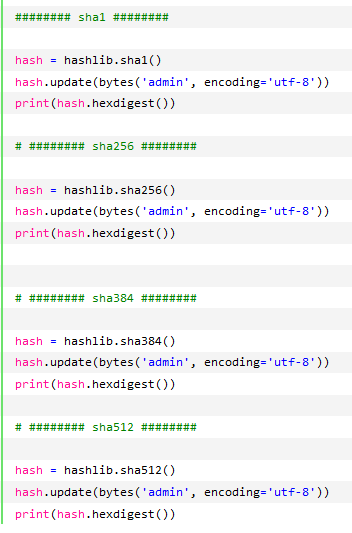
以上加密算法虽然非常厉害,但有时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
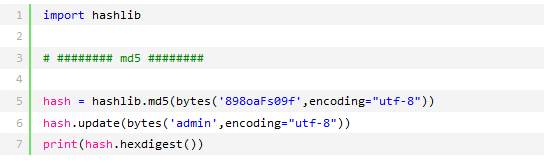
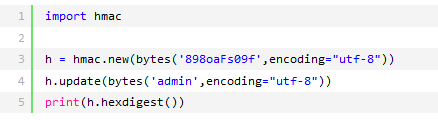
python内置还有一个hmac模块,它内部对我们创建key和内容 进一步的处理然后再加密
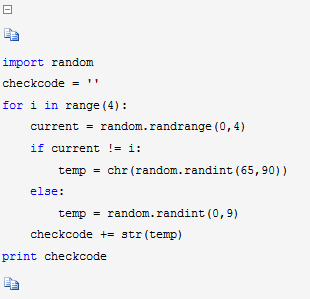
四、random

随机验证码
五、序列化
python中用于序列化的两个模块
- json 用于【字符串】和【python基本数据类型】之间进行转换
- pickle 用于【python特有的类型】和【python基本数据类型】之间进行转换
Json模块提供了四个功能:loads load dumps dump
pickle模块提供了四个功能:loads load dumps dump

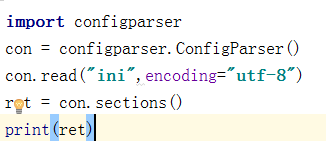
六、configparser
configparser用于处理特定格式的文件,其本质上是利用open来操作文件。
指定格式为

1.获取所有节点
2.获取指定节点下所有的键值对

3.获取指定节点下所有的键

4.获取指定节点下指定key的值

5.检查、删除、添加节点

6.检查、删除、设置指定组内的键值对

完整的设置一个节点以及属性

七、XML
XML是实现不同语言或程序之间进行数据交换的协议,XML文件格式如下:
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2026</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
1、解析XML
①利用ElementTree.XML将字符串解析成xml对象
from xml.etree import ElementTree as ET# 打开文件,读取XML内容
str_xml = open('xo.xml', 'r').read() # 将字符串解析成xml特殊对象,root代指xml文件的根节点 root = ET.XML(str_xml) _xml)
②利用ElementTree.parse将字符直接串解析成xml对象
from xml.etree import ElementTree as ET# 直接解析xml文件
tree = ET.parse("xo.xml") # 获取xml文件的根节点 root = tree.getroot() 2、操作XML
XML格式类型是节点嵌套节点,对于每一个节点均有以下功能,以便对当前节点进行操作:
查看
由于每一个节点都具有以上的方法,并且在上一步骤中解析时均得到了root(xml文件的根节点),so可以利用以上方法进行操作xml文件。
a、遍历XML文档的所有内容
from xml.etree import ElementTree as ET############ 解析方式一 ############
""" # 打开文件,读取XML内容 str_xml = open('xo.xml', 'r').read() # 将字符串解析成xml特殊对象,root代指xml文件的根节点 root = ET.XML(str_xml) """ ############ 解析方式二 ############ # 直接解析xml文件 tree = ET.parse("xo.xml") # 获取xml文件的根节点 root = tree.getroot() ### 操作 # 顶层标签 print(root.tag) # 遍历XML文档的第二层 for child in root: # 第二层节点的标签名称和标签属性 print(child.tag, child.attrib) # 遍历XML文档的第三层 for i in child: # 第二层节点的标签名称和内容 print(i.tag,i.text)
b、遍历XML中指定的节点
from xml.etree import ElementTree as ET############ 解析方式一 ############
""" # 打开文件,读取XML内容 str_xml = open('xo.xml', 'r').read() # 将字符串解析成xml特殊对象,root代指xml文件的根节点 root = ET.XML(str_xml) """ ############ 解析方式二 ############ # 直接解析xml文件 tree = ET.parse("xo.xml") # 获取xml文件的根节点 root = tree.getroot() ### 操作 # 顶层标签 print(root.tag) # 遍历XML中所有的year节点 for node in root.iter('year'): # 节点的标签名称和内容 print(node.tag, node.text) c、修改节点内容
由于修改的节点时,均是在内存中进行,其不会影响文件中的内容。所以,如果想要修改,则需要重新将内存中的内容写到文件中。
c.①解析字符串方式,修改,保存
from xml.etree import ElementTree as ET############ 解析方式一 ############# 打开文件,读取XML内容 str_xml = open('xo.xml', 'r').read() # 将字符串解析成xml特殊对象,root代指xml文件的根节点 root = ET.XML(str_xml) ############ 操作 ############ # 顶层标签 print(root.tag) # 循环所有的year节点 for node in root.iter('year'): # 将year节点中的内容自增一 new_year = int(node.text) + 1 node.text = str(new_year) # 设置属性 node.set('name', 'alex') node.set('age', '18') # 删除属性 del node.attrib['name'] ############ 保存文件 ############ tree = ET.ElementTree(root) tree.write("newnew.xml", encoding='utf-8') c.②解析文件方式,修改,保存
from xml.etree import ElementTree as ET############ 解析方式二 ############# 直接解析xml文件 tree = ET.parse("xo.xml") # 获取xml文件的根节点 root = tree.getroot() ############ 操作 ############ # 顶层标签 print(root.tag) # 循环所有的year节点 for node in root.iter('year'): # 将year节点中的内容自增一 new_year = int(node.text) + 1 node.text = str(new_year) # 设置属性 node.set('name', 'alex') node.set('age', '18') # 删除属性 del node.attrib['name'] ############ 保存文件 ############ tree.write("newnew.xml", encoding='utf-8') d、删除节点
d.①解析字符串方式打开、删除、保存
############ 解析字符串方式打开 ############# 打开文件,读取XML内容
str_xml = open('xo.xml', 'r').read() # 将字符串解析成xml特殊对象,root代指xml文件的根节点 root = ET.XML(str_xml) ############ 操作 ############ # 顶层标签 print(root.tag) # 遍历data下的所有country节点 for country in root.findall('country'): # 获取每一个country节点下rank节点的内容 rank = int(country.find('rank').text) if rank > 50: # 删除指定country节点 root.remove(country) ############ 保存文件 ############ tree = ET.ElementTree(root) tree.write("newnew.xml", encoding='utf-8') d.②解析文件方式打开,删除,保存
from xml.etree import ElementTree as ET############ 解析文件方式 ############# 直接解析xml文件 tree = ET.parse("xo.xml") # 获取xml文件的根节点 root = tree.getroot() ############ 操作 ############ # 顶层标签 print(root.tag) # 遍历data下的所有country节点 for country in root.findall('country'): # 获取每一个country节点下rank节点的内容 rank = int(country.find('rank').text) if rank > 50: # 删除指定country节点 root.remove(country) ############ 保存文件 ############ tree.write("newnew.xml", encoding='utf-8') 3、创建XML文档
- 创建方式一
from xml.etree import ElementTree as ET# 创建根节点
root = ET.Element("famliy") # 创建节点大儿子 son1 = ET.Element('son', {'name': '儿1'}) # 创建小儿子 son2 = ET.Element('son', {"name": '儿2'}) # 在大儿子中创建两个孙子 grandson1 = ET.Element('grandson', {'name': '儿11'}) grandson2 = ET.Element('grandson', {'name': '儿12'}) son1.append(grandson1) son1.append(grandson2) # 把儿子添加到根节点中 root.append(son1) root.append(son1) tree = ET.ElementTree(root) tree.write('oooo.xml',encoding='utf-8', short_empty_elements=False) - 创建方式二
from xml.etree import ElementTree as ET# 创建根节点
root = ET.Element("famliy") # 创建大儿子 # son1 = ET.Element('son', {'name': '儿1'}) son1 = root.makeelement('son', {'name': '儿1'}) # 创建小儿子 # son2 = ET.Element('son', {"name": '儿2'}) son2 = root.makeelement('son', {"name": '儿2'}) # 在大儿子中创建两个孙子 # grandson1 = ET.Element('grandson', {'name': '儿11'}) grandson1 = son1.makeelement('grandson', {'name': '儿11'}) # grandson2 = ET.Element('grandson', {'name': '儿12'}) grandson2 = son1.makeelement('grandson', {'name': '儿12'}) son1.append(grandson1) son1.append(grandson2) # 把儿子添加到根节点中 root.append(son1) root.append(son1) tree = ET.ElementTree(root) tree.write('oooo.xml',encoding='utf-8', short_empty_elements=False) - 创建方式三
from xml.etree import ElementTree as ET# 创建根节点
root = ET.Element("famliy") # 创建节点大儿子 son1 = ET.SubElement(root, "son", attrib={'name': '儿1'}) # 创建小儿子 son2 = ET.SubElement(root, "son", attrib={"name": "儿2"}) # 在大儿子中创建一个孙子 grandson1 = ET.SubElement(son1, "age", attrib={'name': '儿11'}) grandson1.text = '孙子' et = ET.ElementTree(root) #生成文档对象 et.write("test.xml", encoding="utf-8", xml_declaration=True, short_empty_elements=False) 由于原生保存的xml时默认无缩进,如果想要设置缩进的话,需要修改保存方式:
from xml.etree import ElementTree as ET
from xml.dom import minidom def prettify(elem): """将节点转换成字符串,并添加缩进。 """ rough_string = ET.tostring(elem, 'utf-8') reparsed = minidom.parseString(rough_string) return reparsed.toprettyxml(indent="\t") # 创建根节点 root = ET.Element("famliy") # 创建大儿子 # son1 = ET.Element('son', {'name': '儿1'}) son1 = root.makeelement('son', {'name': '儿1'}) # 创建小儿子 # son2 = ET.Element('son', {"name": '儿2'}) son2 = root.makeelement('son', {"name": '儿2'}) # 在大儿子中创建两个孙子 # grandson1 = ET.Element('grandson', {'name': '儿11'}) grandson1 = son1.makeelement('grandson', {'name': '儿11'}) # grandson2 = ET.Element('grandson', {'name': '儿12'}) grandson2 = son1.makeelement('grandson', {'name': '儿12'}) son1.append(grandson1) son1.append(grandson2) # 把儿子添加到根节点中 root.append(son1) root.append(son1) raw_str = prettify(root) f = open("xxxoo.xml",'w',encoding='utf-8') f.write(raw_str) f.close()
4、命名空间
详细介绍 请点这里
模块拾遗
_name_ #只有执行主py文件时,__name == "__main__",否则执行模块名
_file_ #本身自己的路径
_package_ #
#当前文件None
#导入的其他文件:指定文件所在包,用.分割
_doc_ #py文件的注释
_cached_ #
#当前文件None
#导入的其他文件
1.主文件
调用主函之前,必须加if __name__ == "__main__":
2.__file__
当前文件的路径
os.path.join/os.path.dirname
3.内置函数在builtins里面
json、pickle
1.主文件
调用主函数之前,必须加 if __name__="__main__"
2.__file__
#当前文件的路径
sys.path os.path.join os.path.dirname
import os,sys
os.path.dirnmae(__file__)
"""
temp = os.path.dirname(__file__)
b = "bin"
new_path = os.path.join(temp,b)
sys.path.append(new_path)
"""
=
"""
sys.path.append(os.path.join(os.path.dirname(__file__),"bin"))
3.json模块
loads -> 内部必须是双引号:字符串->列表、字典
dumps: 列表->字符串
load:打开文件=》读取内容=》列表、字典
dump:列表、字典=》字符串,然后写入文件
4.如何安装第三方模块
pip3
pip3 install xxx
源码
下载,解压
进入目录 python setup.py install
5.requests
res = requests.get("")
res.encoding = "utf-8"
result = res.text
6.xml
1.两种解析方式
解析一个字符串
str
文件
--》tree,ElementTree,type
-->root,Element,type
from xml.etree import ElementTree as ET
#打开文件,读取xml内容
str_xml = open("ox.xml","r").read()
#将字符串解析成xml特殊对象,root代指xml文件的根节点
root = ET.XML(str_xml)
解析一个文件路径
from xml.etree import ElementTree as ET
#直接解析xml文件
tree = ET.parse("ox.xml")
#获取xml文件的根节点
root = tree.getroot()
2.对于某个节点操作
Element:
tag:获取当前节点的标签名
attrib:获取当前节点的属性
find:
iter set get
3.两种方式:
都能读取 都能修改(内存数据)重新写入
重新写入文件
tree.write()
str->tree = ElementTree(root)
##tree.write(xxx,encoding = "utf-8")
4.创建XML
Element(xx,xx,)
三种方法:
son = ET.Element("family",{"age":""})
son = root.makeelement("family",{"age":"18"})
s = ET.SubElement(root,"family",{"age":"十八"})
5.缩进
6.命名空间
+++++++++++++++++重要++++++++++++++++++
1.一切皆对象
2.“s”,str,{},list
type(obj) Element
7.urllib,模块requests
发送http请求,获取请求返回值
#json xml html
#########################字符串格式化###########################
python的字符串格式化有两种方式:百分号方式、format方式
百分号的方式相对来说比较老,而format方式则是比较先进的方式,企图替换古老的方式,目前两者并存。
1、百分号方式
%[(name)][flags][width].[precision]typecode
- (name) 可选,用于选择指定的key
- flags 可选,可供选择的值有: + 右对齐;正数前加正号,负数前加负号
- + 右对齐;正数前加正好,负数前加负号;
- - 左对齐;正数前无符号,负数前加负号;
- 空格 右对齐;正数前加空格,负数前加负号;
- 0 右对齐;正数前无符号,负数前加负号;用0填充空白处
- width 可选,占有宽度
- .precision 可选,小数点后保留的位数
- typecode 必选
- s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置
- r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置
- c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置
- o,将整数转换成 八 进制表示,并将其格式化到指定位置
- x,将整数转换成十六进制表示,并将其格式化到指定位置
- d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
- e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)
- E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)
- f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
- F,同上
- g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)
- G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)
- %,当字符串中存在格式化标志时,需要用 %%表示一个百分号

2、Format方式
[[fill]align][sign][#][0][width][,][.precision][type]
- file 【可选】空白处填充的字符
- align 【可选】对齐方式(需配合width使用)
-
- <,内容左对齐
- >,内容右对齐(默认)
- =,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字
- ^,内容居中
- sign 【可选】 有无符号数字
- +,正号加正,负号加负;
- -,正号不变,负号加负;
- 空格 ,正号空格,负号加负;
- # 【可选】对于二进制、八进制、十六进制,如果加上#,会显示0b/0o/0x,否则不显示
- , 【可选】为数字添加分隔符,如:1,000,000
- width 【可选】格式化位所占宽度
- .precision 【可选】小数位保留精度
- type 【可选】格式化类型
- 传入” 字符串类型 “的参数
- s,格式化字符串类型数据
- 空白,未指定类型,则默认是None,同s
- 传入“ 整数类型 ”的参数
- b,将10进制整数自动转换成2进制表示然后格式化
- c,将10进制整数自动转换为其对应的unicode字符
- d,十进制整数
- o,将10进制整数自动转换成8进制表示然后格式化;
- x,将10进制整数自动转换成16进制表示然后格式化(小写x)
- X,将10进制整数自动转换成16进制表示然后格式化(大写X)
- 传入“ 浮点型或小数类型 ”的参数
- e, 转换为科学计数法(小写e)表示,然后格式化;
- E, 转换为科学计数法(大写E)表示,然后格式化;
- f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- g, 自动在e和f中切换
- G, 自动在E和F中切换
- %,显示百分比(默认显示小数点后6位)
- 传入” 字符串类型 “的参数
常用格式化:
