众筹网站功能百度识图在线使用一下
词集与词袋模型
算法的主要作用也就是对文本做单词切分,有点从一篇文章里提取关键词这种意思,旨在用向量来描述文本的主要内容,其中包含了词集与词袋两种。
词集模型 DictVectorizer:单词构成的集合,集合中每个元素只有一个,即词集中的每个单词都只有一个。
词袋模型 CountVectorizer:在词集的基础上加入了频率这个维度,即统计单词在文档中出现的次数(令牌化和出现频数统计),通常我们在应用中都选用词袋模型。
from sklearn.feature_extraction.text import CountVectorizer
#使用默认参数实例化分词对象
vec=CountVectorizer()
#查看词袋模型的参数
print(vec.get_params())# 结果
"""
{'analyzer': 'word','binary': False,'decode_error': 'strict','dtype': numpy.int64,'encoding': 'utf-8','input': 'content','lowercase': True,'max_df': 1.0,'max_features': None,'min_df': 1,'ngram_range': (1, 1),'preprocessor': None,'stop_words': None,'strip_accents': None,'token_pattern': '(?u)\\b\\w\\w+\\b','tokenizer': None,'vocabulary': None}"""
##让我们使用它对文本corpus进行简单文本全集令牌化,并统计词频:
corpus = ['This is the first document.','This is the second second document.', 'And the third one.','Is this the first document?']X = vec.fit_transform(corpus)
#在拟合期间发现的每个项都被分配一个与所得矩阵中的列对应的唯一整数索引#获取特征名称(列名)
print(vec.get_feature_names())
#获取词汇表(训练语料库),词汇表由特征名和出现频次构成
print(vec.vocabulary_)print(X.toarray())
# 结果
"""
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
{'this': 8, 'is': 3, 'the': 6, 'first': 2, 'document': 1, 'second': 5, 'and': 0, 'third': 7, 'one': 4}
[[0 1 1 1 0 0 1 0 1][0 1 0 1 0 2 1 0 1][1 0 0 0 1 0 1 1 0][0 1 1 1 0 0 1 0 1]]"""
TF-IDF
TF-IDF算法是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频,IDF意思是逆向文件频率,因此TF-IDF其实就是TF*IDF。
举个例子,下面有这么几句话:
我今天跑你家去偷吃了你家的大米,但是被你家狗咬了,你要赔我钱
我想下午找你玩,但是天气预报说下午要下雨,所以你还是自己玩泥巴去吧
从见到你老婆的第一天起,你这个兄弟我就交定了
假设以上三句话我们分别写在三张纸上,那么这个词频,也就是TF,代表的就是某个词在它所处的那张纸上的出现频率,比如“你”这个词,在第一张纸上出现的频率。

而IDF则代表这个词和所有文档整体的相关性,如果某个词在某一类别出现的多,在其他类别出现的少,那IDF的值就会比较大。如果这个词在所有类别中都出现的多,那么IDF值则会随着类别的增加而下降,比如例中的“你”,它的TF值可能很高,但由于其在三个文本中均有出现,所以IDF值就会比较低。IDF反映的是一个词能将当前文本与其它文本区分开的能力。
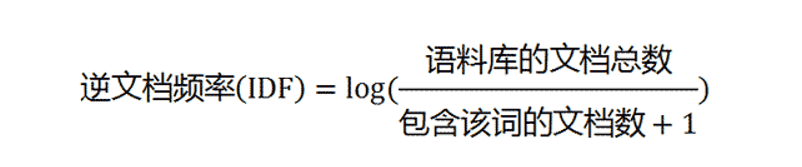
去除停用词
# 创建停用词列表def stopwordslist():stopwords = [line.strip() for line in open('停用词.txt',encoding='UTF-8').readlines()]return stopwords# 对句子进行中文分词def seg_depart(sentence):# 对文档中的每一行进行中文分词print("正在分词")sentence_depart = jieba.cut(sentence.strip())# 创建一个停用词列表stopwords = stopwordslist()# 输出结果为outstroutstr = ''# 去停用词for word in sentence_depart:if word not in stopwords:if word != '\t':outstr += wordoutstr += " "return outstr
TF-IDF例子
from sklearn.feature_extraction.text import TfidfVectorizer
# 文本文档列表
text = ['This is the first document.','This is the second second document.', 'And the third one.','Is this the first document?']
# 创建变换函数
vectorizer = TfidfVectorizer()
# 词条化以及创建词汇表
vectorizer.fit(text)
# 总结
print(vectorizer.vocabulary_)
print(vectorizer.idf_)
# 编码文档
vector = vectorizer.transform([text[0]])
# 总结编码文档
print(vector.shape)
print(vector.toarray())"""
{'this': 8, 'is': 3, 'the': 6, 'first': 2, 'document': 1, 'second': 5, 'and': 0, 'third': 7, 'one': 4}
[1.91629073 1.22314355 1.51082562 1.22314355 1.91629073 1.916290731. 1.91629073 1.22314355]
(1, 9)
[[0. 0.43877674 0.54197657 0.43877674 0. 0.0.35872874 0. 0.43877674]]
"""