网站建设优化公司/邯郸今日头条最新消息
一、集合概述
1、简介
什么是集合?
它其实就是一个容器,容器主要是存储对象
集合作用
存储
对象
2、集合特点
集合存储对象的最大特点:存储对象的个数是动态的
数组最大的缺点:存储数据的个数是固定,不可被修改,也就是说当数组初始化完成之后,此数组长度,就已经固定。
举例
//动态数组初始化int []arrays=new int[10]//静态数组初始化int []arrays=new int[]{1,2,3};//定义一个存储对象的数组Object []arrays=new Object[10];
集合比数组存储数据,更加灵活
3、集合分类
针对java集合
它能够存储两个对象
key-value映射关系
队列集合
FIFO
双端队列
不能存储可重复的对象
无序
A,100,CC,A,100能存储可重复的对象
有序
1,2,31,2,3List集合
Set集合
Queue集合
Map集合
二、分析集合类图
1、类图
类图如下:
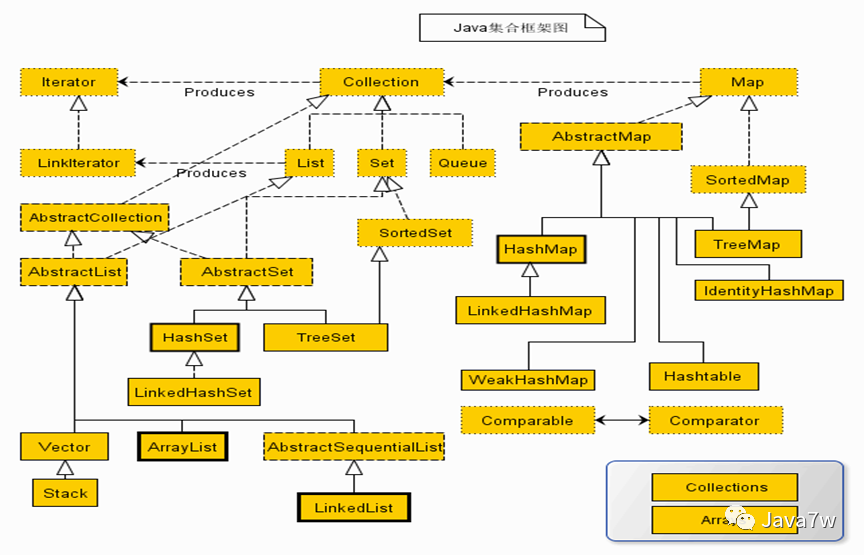
分析上述类图
迭代器
只给List集合使用
迭代器
通过Collection,获取迭代器对象
HashMap
TreeMap
LinkedHashMap
HashTable
HashSet
TreeSet
LinkedHashSet
Vector
ArrayList
LinkedList
Stack
Collection是List、Set、Queue的父接口
List的实现类
Set的实现类
Map的实现类
通过Map接口,可以产生Collection接口对象
Iterator
ListIterator
三、Collection和Iterator接口
1、Collection的简介
Collection接口是List、Set和Queue接口的父接口,该接口里定义的方法既可用于操作Set集合,也可用于操作List和Queue集合
2、Collection的主要方法
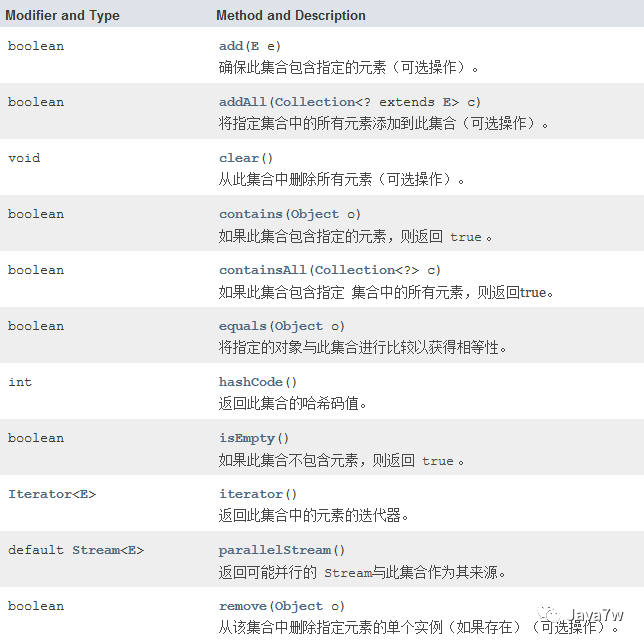
代码实例
package collection用法;import java.util.ArrayList;import java.util.Collection;import java.util.Iterator;public class MainTest {public static void main(String[] args) {/* * interface Collection { * * } * * interface List extends Collection { * * } * * class ArrayList implements List { * * } * * Collection t=new ArrayList(); */// 体现使用Collection接口Collection<String> collections = new ArrayList<>();collections.add("aaa");collections.add("bbb");collections.add("ccc");collections.add("ddd");collections.add("eee");System.out.println("集合容器存储对象的个数=" + collections.size());System.out.println("通过迭代器遍历输出");// 如何遍历集合数据// 可以使用迭代器Iterator<String> iter = collections.iterator();// 循环遍历while (iter.hasNext()) {String itemValue = iter.next();System.out.println(itemValue);}System.out.println("-------------");iter = collections.iterator();// 循环遍历while (iter.hasNext()) {String itemValue = iter.next();System.out.println(itemValue);}System.out.println("foreach-----------");for(String v:collections){System.out.println(v);}System.out.println("lambda表达式的forEachRemaining");iter = collections.iterator();//iter.forEachRemaining(s->System.out.println(s));iter.forEachRemaining(System.out::println);System.out.println("将bbb对象数据删除");collections.remove("bbb");iter = collections.iterator();//iter.forEachRemaining(s->System.out.println(s));iter.forEachRemaining(System.out::println);System.out.println("将批量删除数据");Collection<String> remveCollections = new ArrayList<>();remveCollections.add("ccc");remveCollections.add("ddd");collections.removeAll(remveCollections);iter = collections.iterator();//iter.forEachRemaining(s->System.out.println(s));iter.forEachRemaining(System.out::println);}}
四、Set集合用法
1、概述
Set集合复用了Collection的方法,同时也扩展自身的特点:
不能添加相同的对象数据
数据是无序的
2、HashSet的用法
a、HashSet的特点
以哈希码方式存储对象
HashSet是线程不安全
不能存储相同的对象
判断对象是否相同的标准:根据
hasCode方法的返回值及equals方法来决定对象是否相同的标准
如果hasCode方法的返回值相同,还有equals方法的返回值为true,则认为对象相同
举例
package HashSet实例;import java.util.HashSet;class R{private int count;public R() {}public R(int count) {this.count = count;}public int getCount() {return count;}public void setCount(int count) {this.count = count;}@Overridepublic String toString() {return "R [count=" + count + "]";}//重写hashCode@Overridepublic int hashCode() {// TODO Auto-generated method stubreturn count;}@Overridepublic boolean equals(Object obj) {if(obj instanceof R){R otherR=(R) obj;if(this.getCount()==otherR.getCount()){return true;}}return false;}}public class MainTest {public static void main(String[] args) {//新建HashSet的对象HashSet<R> set=new HashSet<>();set.add(new R(10));set.add(new R(2));set.add(new R(50));set.add(new R(40));set.add(new R(90));set.add(new R(90));R r100=new R(100);set.add(r100);set.add(r100);System.out.println("遍历输出set集合");//遍历输出set集合for(R r:set){System.out.println(r);}R r101=new R(101);System.out.println(r101.hashCode());R r102=new R(101);System.out.println(r102.hashCode());}}
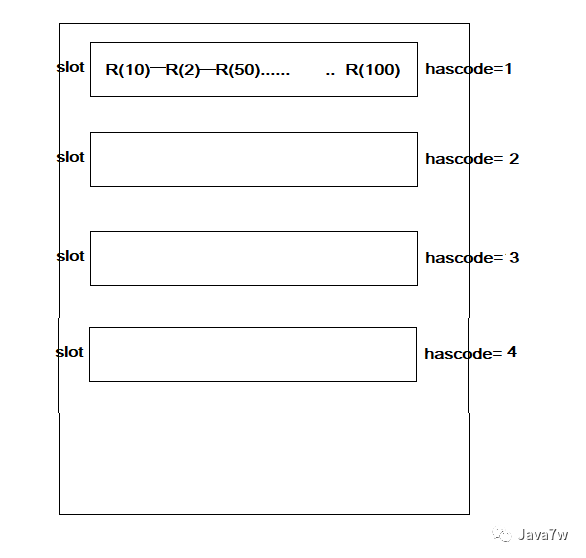
3、HashSet的存储方式
HashSet存储对象以哈希码存储
每个hascode的值,分配一个槽(slot),同一个槽的对象,以链表方式存储
存储方式如下:
五、TreeSet集合用法
1、简介
TreeSet可以确保集合元素处于
排序状态
2、TreeSet特点
TreeSet也是属于Set集合类别一种
不能存储相同的对象
保证集合对象以
排序状态显示自然排序实现
定制排序实现
3、TreeSet的排序规则
a、自然排序
自然排序是TreeSet排序的默认规则
如何实现自然排序
重写compareTo方法
如果该方法返回0,则表明这两个对象相等;如果该方法返回一个正整数,则表明obj1大于obj2;如果该方法返回一个负整数,则表明obj1小于obj2。
此类必须要实现Comparable接口
举例
package TreeSet实例.自然排序;import java.util.TreeSet;class R implements Comparable<R>{private int count;public R() {}public R(int count) {this.count = count;}public int getCount() {return count;}public void setCount(int count) {this.count = count;}@Overridepublic String toString() {return "R [count=" + count + "]";}@Overridepublic int compareTo(R o) {return o.getCount()>this.getCount()?-1:(o.getCount()==this.getCount()?0:1);}}public class MainTest {public static void main(String[] args) {//定义一个TreeSet//TreeSet默认的排序规则:自然排序// 判断对象是否相同的标准://TreeSet<R> set=new TreeSet<>();//将R对象存储set集合set.add(new R(100));set.add(new R(50));set.add(new R(60));set.add(new R(20));set.add(new R(30));set.add(new R(15));set.add(new R(15));System.out.println("当前TreeSet的个数="+set.size());System.out.println("遍历TreeSet集合");set.forEach(System.out::println);TreeSet<Integer> set2=new TreeSet<>();//new Integer(100);set2.add(100);set2.add(50);set2.add(80);set2.add(70);set2.add(2);set2.forEach(System.out::println);}}
b、定制排序
此类不需要实现Comparable接口
如果需要实现定制排序,则需要在创建TreeSet集合对象时,提供一个Comparator对象与该TreeSet集合关联,由该Comparator对象负责集合元素的排序逻辑。
举例
要实现存储Integer数据,按降序实现排序,显然使用自然排序无法实现,则必须使用定制排序
package TreeSet实例.定制排序;import java.util.Comparator;import java.util.TreeSet;public class MainTest {public static void main(String[] args) {// 定义一个局部内部类class LocalComparator implements Comparator<Integer> {@Overridepublic int compare(Integer o1, Integer o2) {if (o1 > o2) {return -1;} else if (o1 < o2) {return 1;} elsereturn 0;}}LocalComparator t1 = new LocalComparator();// TreeSet存储Integer对象// TreeSet set=new TreeSet<>(t1);// 定义一个匿名内部类/*TreeSet set = new TreeSet<>(new Comparator() {@Overridepublic int compare(Integer o1, Integer o2) {// TODO Auto-generated method stubif (o1 > o2) {return -1;} else if (o1 < o2) {return 1;} elsereturn 0;}});*///使用lambda表达式实现//Comparator c=(o1,o2)->o1>o2?-1:(o1==o2?0:1);TreeSet<Integer> set = new TreeSet<>((o1,o2)->o1>o2?-1:(o1==o2?0:1));set.add(100);set.add(200);set.add(150);set.add(300);set.add(250);set.add(50);set.forEach(System.out::println);}}
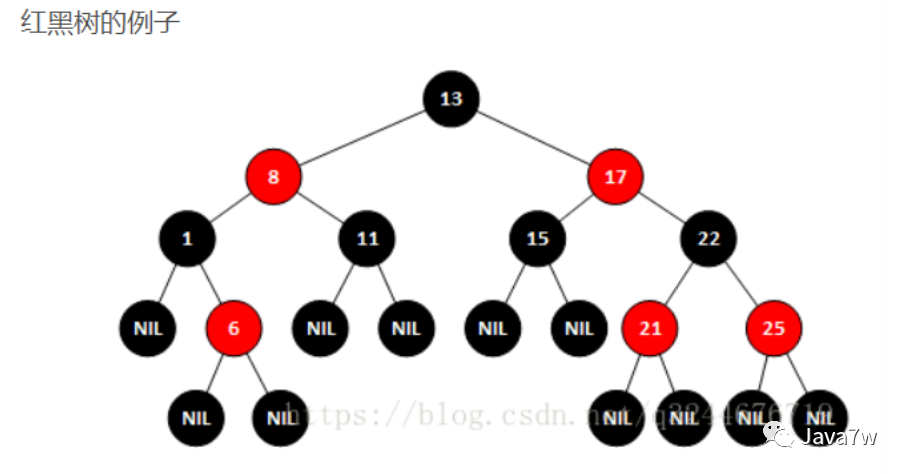
c、实现TreeSet低层算法
实现红黑树数据结构实现排序功能
1.节点是红色或黑色。
2.根节点是黑色。
3.每个叶子节点都是黑色的空节点(NIL节点)。
4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
六、LinkedHashSet集合用法
1、简介
lLinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,但它同时使用
链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
2、分析存储数据原理
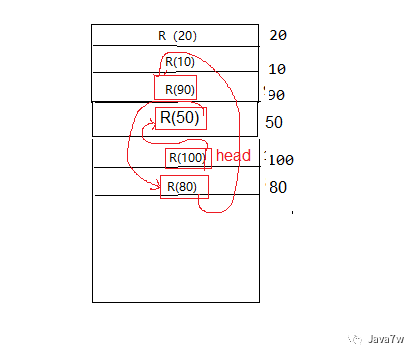
以哈希码存储数据
数据与数据之间使用链表维护,因此数据是有序输出
3、举例
package LinkedHashSet实例;import java.util.HashSet;import java.util.LinkedHashSet;class R{private int count;public R() {}public R(int count) {this.count = count;}public int getCount() {return count;}public void setCount(int count) {this.count = count;}@Overridepublic String toString() {return "R [count=" + count + "]";}}public class MainTest {public static void main(String[] args) {HashSet<R> set=new HashSet<>();set.add(new R(100));set.add(new R(50));set.add(new R(80));set.add(new R(90));set.add(new R(20));set.add(new R(10));set.forEach(System.out::println);System.out.println("使用LinkedHashSet集合-------");LinkedHashSet<R> set2=new LinkedHashSet<>();set2.add(new R(100));set2.add(new R(50));set2.add(new R(80));set2.add(new R(90));set2.add(new R(20));set2.add(new R(10)); //有序输出set2.forEach(System.out::println);}}七、Set集合的性能分析
对比HashSet与TreeSet
随机读取能力
添加数据能力
遍历数据能力
从性能角色:HashSet>TreeSet
对比HashSet与LinkedHashSet
针对读取、写入HashSet要比LinkedHashSet性能要好
针对整体遍历,LinkedHashSet要比HashSet性能要好
八、List集合用法
1、简介
List集合存储有序的数据
List集合能够存储可重复的对象
List集合每个元素都有对应的一个索引值(下标值)
2、ArrayList实现类用法
方法分析
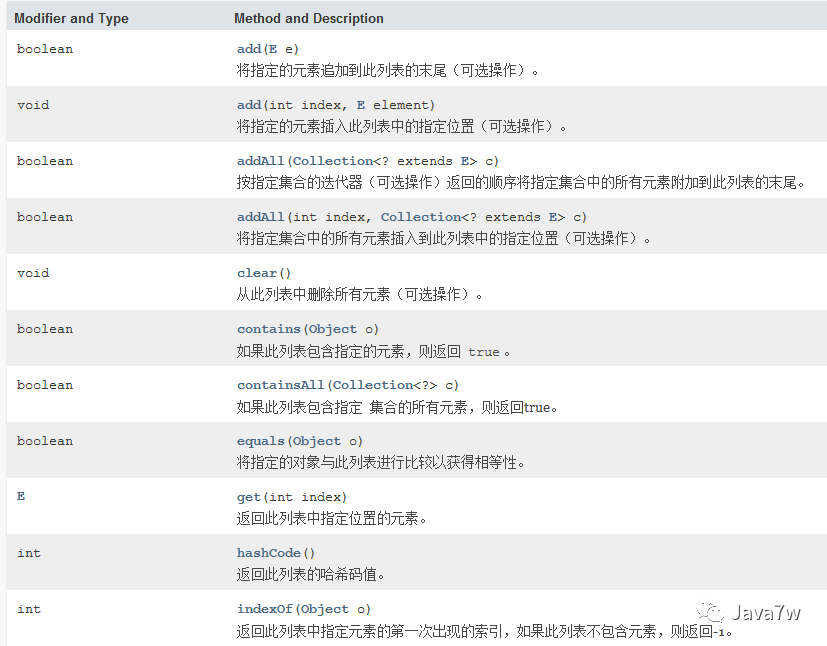
代码实现
package ArrayList用法;import java.util.ArrayList;import java.util.Iterator;import java.util.ListIterator;public class MainTest {public static void main(String[] args) {//创建ArrayList对象ArrayList<String> books=new ArrayList<>();books.add("thinking in java");books.add("thinking in c++");books.add("thinking in python");books.add("thinking in c");System.out.println("写法一:如何遍历list集合");//如何遍历list集合books.forEach(System.out::println);System.out.println("写法二:如何遍历list集合");for(String v:books){System.out.println(v);}System.out.println("写法三:如何遍历list集合");Iterator<String> iter=books.iterator();while(iter.hasNext()){String value=iter.next();System.out.println(value);}System.out.println("写法四:如何遍历listIterator集合");ListIterator<String> iterList=books.listIterator();while(iterList.hasNext()){String value=iterList.next();System.out.println(value);}System.out.println("listIterator支持反向遍历输出");while(iterList.hasPrevious()){String value=iterList.previous();System.out.println(value);}System.out.println("写法五:通过下标值遍历list集合");for(int index=0;index<books.size();index++){//根据index,获取对象数据String book=books.get(index);System.out.println(book);}System.out.println("写法六:将ArrayList转换成数组");Object []objectArrays=books.toArray();for(Object o:objectArrays){if(o instanceof String)System.out.println((String)o);}System.out.println("删除index=2");books.remove(2);books.forEach(System.out::println);}}
九、ArrayList的底层代码实现
1、分析代码
针对jdk1.8版本ArrayList
底层是使用对象类型的
数组存储当第一次add方法调用,才实现数组长度的初始化,默认长度10
当调用add方法,首先判断 size+1与数组当前的长度的大小,来决定是否扩容
if( size+1>数组.length()){ //数组扩容处理 grow();}如何扩容数组
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }扩容数组后的数组长度=原先数组的长度*1.5倍
如何实现删除
public E remove(int index) { rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work return oldValue; }实现原理:
根据下标,添加数据
public void add(int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; }
十、Map集合
1、Map集合特点
存储key,value的具有映射有关系的集合对象
key、value都是对象类型,其实就是引用
key其实就是Set集合类型
key不能重复存储相同的对象
value就是Collection类型
允许可重复的对象
key与value之间存在映射关系
一个key,只能映射一个value对象
但同一个value对象,可以被多个key映射
十一、HashMap实现类
1、特点
HashMap线程不安全
HashMap可以使用null作为key和value
HashMap与HashSet一样,判断key的存储对象是否相同的标准:根据hasCode方法的返回值和equals方法的返回值决定此对象是否相同
2、HashMap的具体用法
a、主要方法
b、举例
package 课堂练习.HashMap集合;import java.util.HashMap;class Product{private String productNo;private String productName;public Product() {}public Product(String productNo, String productName) {this.productNo = productNo;this.productName = productName;}public String getProductNo() {return productNo;}public void setProductNo(String productNo) {this.productNo = productNo;}public String getProductName() {return productName;}public void setProductName(String productName) {this.productName = productName;}@Overridepublic String toString() {return "Product [productNo=" + productNo + ", productName=" + productName + "]";}@Overridepublic boolean equals(Object obj) {// TODO Auto-generated method stubif(obj instanceof Product){Product otherProduct=(Product) obj;if(otherProduct.getProductNo().equals(this.getProductNo())){return true;}}return false;}@Overridepublic int hashCode() {// TODO Auto-generated method stubreturn getProductNo().hashCode();}}class Consumer{private String name;private Integer age;public Consumer() {}public Consumer(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Consumer [name=" + name + ", age=" + age + "]";}}public class MainTest {public static void main(String[] args) {HashMap<Product, Consumer> map=new HashMap<>();//分别新建5个商品对应5个顾客map.put(new Product("sn001", "手机"), new Consumer("李5", 34));map.put(new Product("sn002", "平板电脑"), new Consumer("李1", 34));map.put(new Product("sn003", "茅台"), new Consumer("李2", 34));map.put(new Product("sn004", "apple电脑"), new Consumer("李3", 34));map.put(new Product("sn005", "电视"), new Consumer("李4", 34));map.remove(new Product("sn003", "茅台"));System.out.println("helloworld".hashCode());System.out.println("helloworld".hashCode());//遍历map集合map.forEach((k,v)->System.out.println("key="+k+" value="+v));}}十二、TreeMap实现类用法
1、主要特点
TreeMap存储key-value对(节点)时,需要根据key对节点进行排序。TreeMap可以保证所有的key-value对处于有序状态。
2、TreeMap两种排序方式
自然排序:TreeMap的所有key必须实现Comparable接口,而且所有的key应该是同一个类的对象,否则将会抛出ClassCastException异常。
定制排序:创建TreeMap时,传入一个Comparator对象,该对象负责对TreeMap中的所有key进行排序。采用定制排序时不要求Map的key实现Comparable接口中。
举例
package 集合实例二.TreeMap集合;import java.util.Comparator;import java.util.TreeMap;public class MainTest {public static void main(String[] args) {//创建一个TreeMap对象集合//自然排序TreeMap<Integer, String> map=new TreeMap<>();map.put(100, "李一");map.put(10, "李二");map.put(20, "李三");map.put(15, "李四");map.put(2, "李五");map.put(200, "李六");map.forEach((k,v)->System.out.println("k="+k+" v="+v));System.out.println("定制排序-------------");//定制排序TreeMap<Integer, String> map2=new TreeMap<>(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o1>o2?-1:(o1<o2)?1:0;}});map2.put(100, "李一");map2.put(10, "李二");map2.put(20, "李三");map2.put(15, "李四");map2.put(2, "李五");map2.put(200, "李六");map2.forEach((k,v)->System.out.println("k="+k+" v="+v));}}
十三、LinkedHashMap集合
简介
HashSet有一个子类是LinkedHashSet,HashMap也有一个LinkedHashMap子类;LinkedHashMap也使用双向链表来维护key-value对的次序(其实只需要考虑Key的次序),该链表负责维护Map的迭代顺序,迭代顺序与key-value对的插入顺序保持一致。
十四、Properties集合
简介
Properties类是Hashtable类的子类,正如它的名字所暗示的,该对象在处理属性文件时特别方便。
Properties类可以把Map对象和属性文件关联起来,从而可以把Map对象中的key-value对写入属性文件中,也可以把属性文件中的“属性名=属性值”加载到Map对象中。
由于属性文件里的属性名、属性值只能是字符串类型,所以Propertites里的key、value都是字符串类型。
十五、HashMap底层源码分析
1、构造HashMap对象
public HashMap() { //负载因子=0.75 //当数据达到3/4,则进行扩容处理 this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted }2、分析put方法
a、生成hash值
作用:主要获取数组的下标使用
static final int hash(Object key) {
int h;
//取hashcode方法数据值的高16位与低16位异或操作:就会生成一个均衡的hash值
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}b、put方法
参数一:hash:通过上述方法生成(均衡的hash值)
参数二:key:添加的key值
参数三:value:添加的value值
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//定义一个数组,数组类型:Node(链表的对象)
Node[] tab; Node p; int n, i;
//如果数组为空,则进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//通过hash值获取一个数组单元(桶)
if ((p = tab[i = (n - 1) & hash]) == null)
//如何此数组单元为空对象,则直接添加一个节点对象进来
tab[i] = newNode(hash, key, value, null);
else {
//数组单元已经存在节点对象
Node e; K k;
//就比较数组单元已经存在的节点对象与将要添加的key的equals方法和hash值,如果返回true及hash值相同,则认为两者的对象相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//将数组单元已经存在的节点对象赋值给e
e = p;
else if (p instanceof TreeNode)
//数组单元已经存在的节点对象如果是树节点,则将节点添加到红黑树
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
//遍历已经存在的链表节点,将节点添加到链接
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果此链接节点的个数>=7,则构建成一颗红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}