php在动态网站开发/新浪体育nba
2.3 数据导入
如果我们在一家公司做数据分析,那么我们可以容易访问公司数据库中已有的数据。但是对于一个刚学习SQL的新手来说,并没有现成的数据库供你学习,“巧妇难为无米之炊”,因此我们学习时的第一步就是学会数据导入。
在工作中我们经常接触到的数据格式有以下三种:
| 文件格式 | 行数限制 | 易处理性 |
|---|---|---|
| xlsx/xls | 有限制 | 难处理 |
| CSV | 无限制 | 容易处理 |
| TXT | 无限制 | 容易处理 |
在平时办公中,我们接触最多的就是xlsx或者xls格式的工作簿,但是一张工作表存储的数据最多也只有100多万行,同时将Excel工作表导入到数据库中相对来说难处理一点。而CSV和TXT两种文本格式数据没有行数限制,同时导入到数据库中也比较方便,因此我们尽量获取CSV、TXT两种格式的文本来进行数据分析。
我们要想将文件中的数据导入数据库一般可以用Navicat的导入向导或者语句导入。使用导入向导的优点是简单直观,缺点是速度慢。使用语句导入优点是速度快,尤其是导入几个G数据的时候,两者差距非常明显,当然缺点就是需要写语句。下面我们针对这两种方式分别进行演练。
2.3.1 导入向导
我们以Kaggle网站上下载的公开电商零售数据为例,利用Navicat的导入向导将CSV文件中的数据导入数据库。
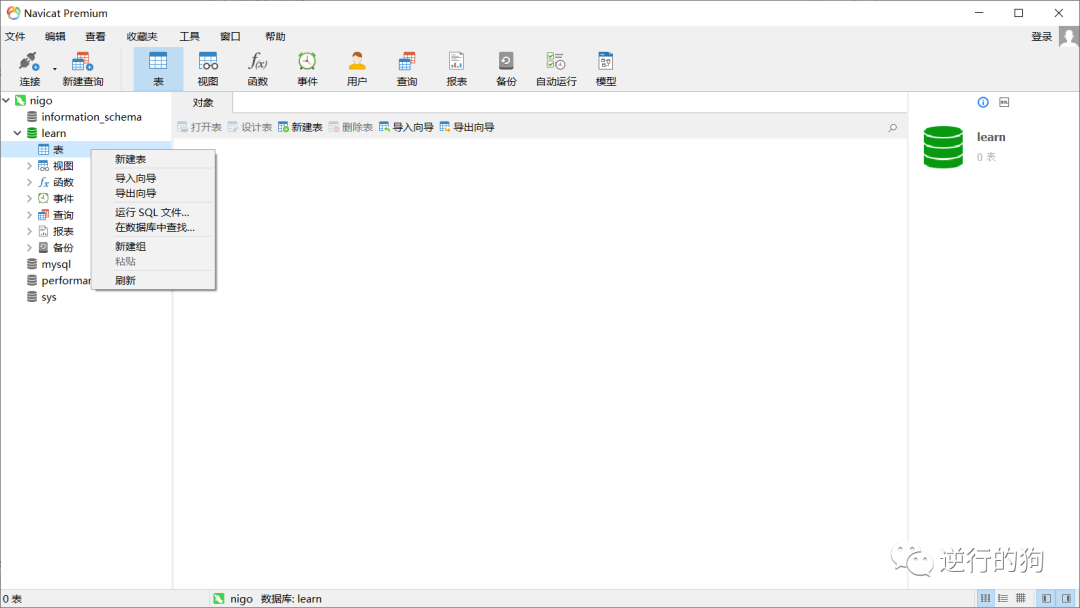
如图2.3.1-1所示,在“表”图标上右键后点击“导入向导”。
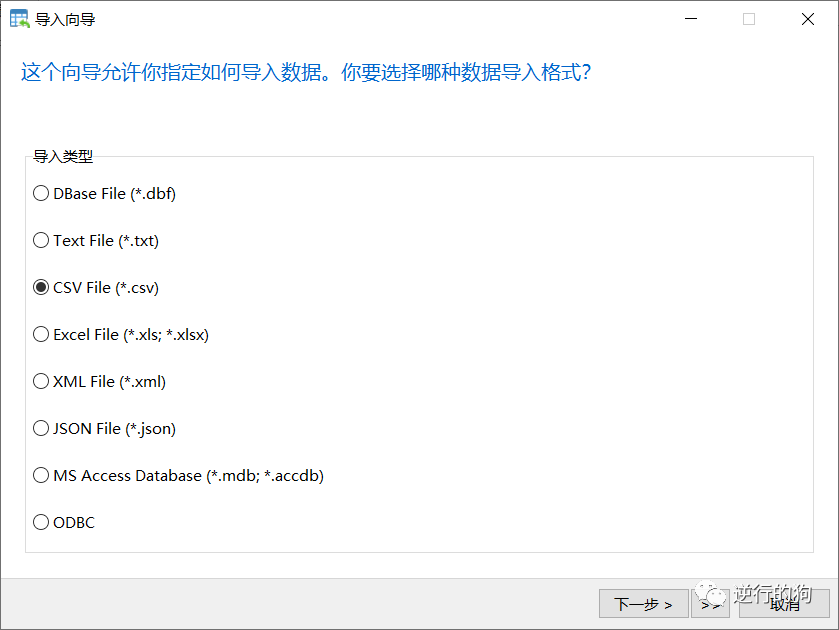
如图2.3.1-2所示,选择导入的文件数据格式。
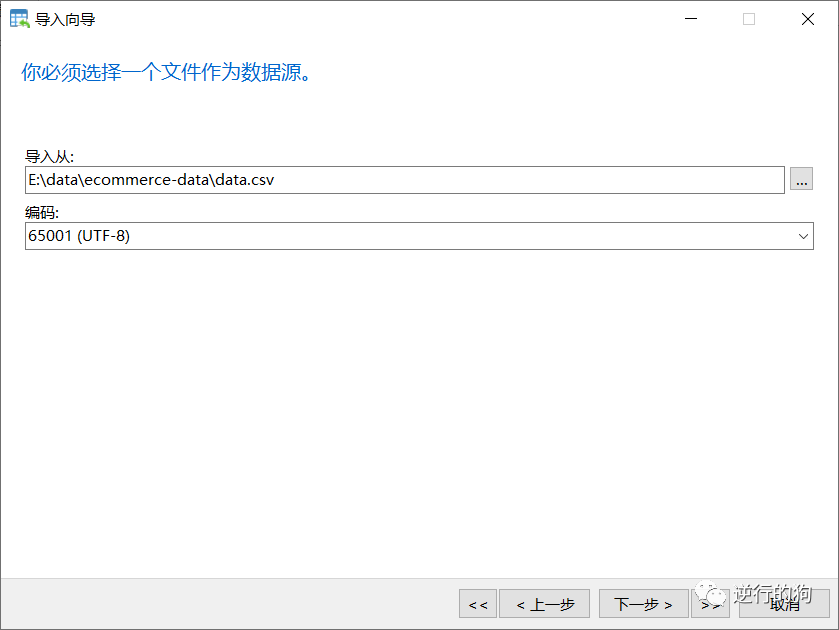
如图2.3.1-3所示,选择导入的文件路径。
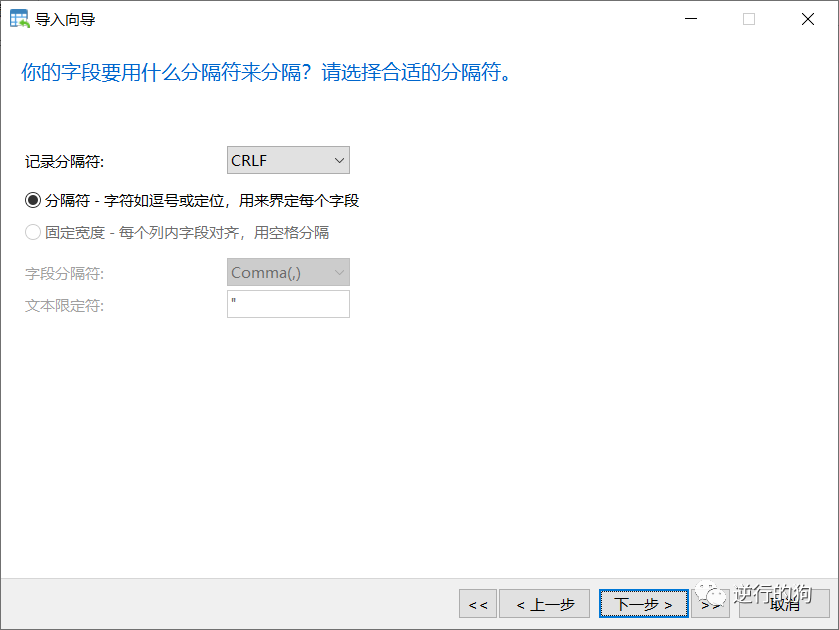
如图2.3.1-4所示,设置字段之间的分隔符,一般保持默认就可以。
如图2.3.1-5所示, 一般文件数据的第一行是字段名称,数据从第二行开始,一般保持默认设置就可以。
如图2.3.1-6所示,设置导入后目标表的名称,默认是导入文件名称,可能自定义修改。
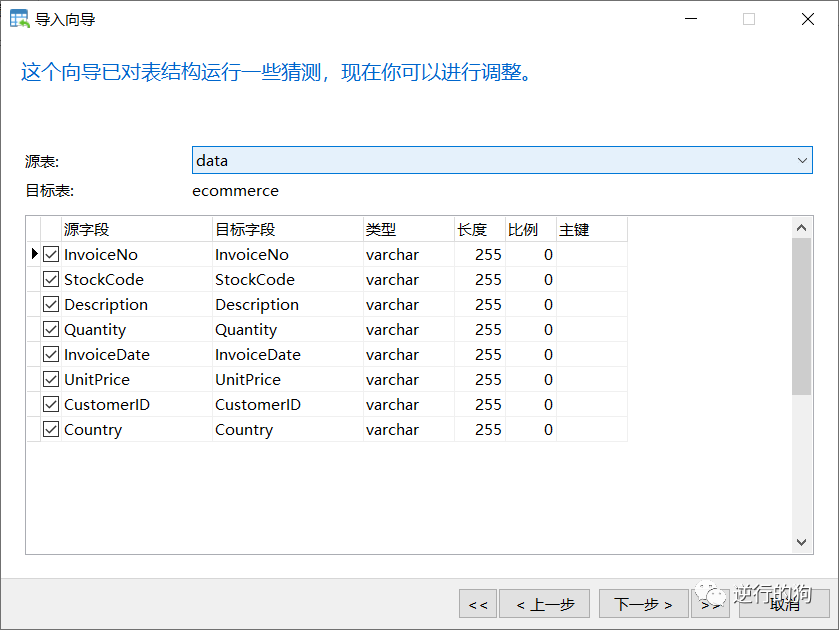
如图2.3.1-7所示,设置导入后的字段名称,数据类型。默认是原表数据名称,数据类型是varchar文本类型,最大长度为255字符。
/home/nigo/IT-Audit/pictures/2.3.1-8.png
如图2.3.1-8所示,保持默认设置。
如图2.3.1-9所示,点击“开始”进行数据导入。
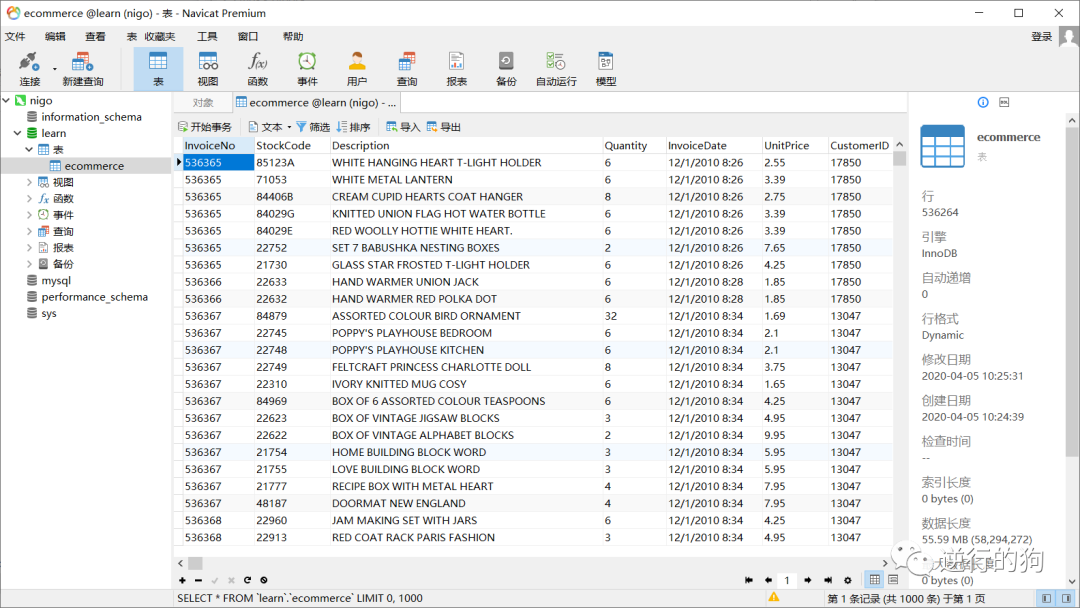
数据导入完成后,如图2.3.1-10所示,双击导入的“ecommerce”表,可以查看表中的字段和数据。
除了CSV外,我们常用的Excel,TXT格式的文件同样方法可以使用导入向导十分方便的导入,这里就不再赘述。需要注意的是如果Excel有时不能导入,可以先将其另存为CSV格式。如果文件中的数据包含有中文的时候,直接导入出现中文乱码,需要先将文件另存为utf-8编码格式。
2.3.2 语句导入
虽然导入向导非常简单,容易上手,但是有两种情况下,我们需要使用写SQL语句来导入数据:
- 导入向导导入失败。
- 导入数据很大,导入向导速度很慢。
采用语句导入的时候,我们需要分两步,首先创建一张空表,再将数据导入创建的空表。
首先在前言提到的GitHub或码云中链接的网盘下载示例数据“data.csv"。然后在Navicat中点击“新建查询”,如图2.3.2-1所示,在新建的查询界面,我们可以写第一条SQL语句了。
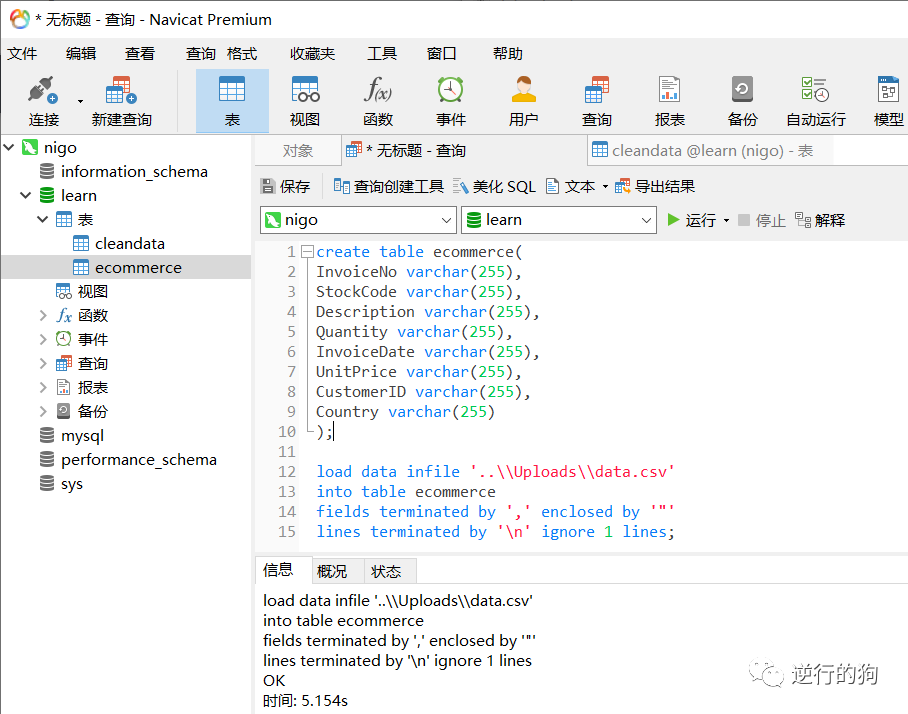
SQL语句是大小写不敏感的,也就是说你写“CREATE”和“create”都是相同的,而其他很多语言大写和小写是不同的。同时Navicat在你输入的时候会自动语句提示,比如当你输入“cr"的时候,系统就弹出了“CREATE”的提示,这个时候你不用输入完整的单词,只需要按一下“Tab”键,就可以将单词补全。这是对于新手十分友好的。
打开下载好的“data.csv"文件,我们可以看到表头的字段为”InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country“
接下来我们就用“create table"语句创建一个名字为“ecommerce”的表并且包含上面的八个字段:
「CREATE TABLE 语法」
CREATE TABLE 表名称
(
列名称1 数据类型,
列名称2 数据类型,
列名称3 数据类型,
....
)
我们按照语法填写好每个字段以及其数据类型:
create table ecommerce(
InvoiceNo varchar(255),
StockCode varchar(255),
Description varchar(255),
Quantity varchar(255),
InvoiceDate varchar(255),
UnitPrice varchar(255),
CustomerID varchar(255),
Country varchar(255)
);
这里的varchar(255)就表示数据类型为文本,且最大容纳位数为255。在MySQL中,有三种主要的数据类型:文本、数字和日期/时间类型。
「文本类型」
| 数据类型 | 描述 |
|---|---|
| CHAR(size) | 保存固定长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的长度。最多 255 个字符。 |
| VARCHAR(size) | 保存可变长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的最大长度。最多 255 个字符。注释:如果值的长度大于 255,则被转换为 TEXT 类型。 |
| TINYTEXT | 存放最大长度为 255 个字符的字符串。 |
| TEXT | 存放最大长度为 65,535 个字符的字符串。 |
| BLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 65,535 字节的数据。 |
| MEDIUMTEXT | 存放最大长度为 16,777,215 个字符的字符串。 |
| MEDIUMBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 16,777,215 字节的数据。 |
| LONGTEXT | 存放最大长度为 4,294,967,295 个字符的字符串。 |
| LONGBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 4,294,967,295 字节的数据。 |
| ENUM(x,y,z,etc.) | 允许你输入可能值的列表。可以在 ENUM 列表中列出最大 65535 个值。如果列表中不存在插入的值,则插入空值。注释:这些值是按照你输入的顺序存储的。可以按照此格式输入可能的值:ENUM('X','Y','Z') |
| SET | 与 ENUM 类似,SET 最多只能包含 64 个列表项,不过 SET 可存储一个以上的值。 |
「数字类型」
| 数据类型 | 描述 |
|---|---|
| TINYINT(size) | -128 到 127 常规。0 到 255 无符号*。在括号中规定最大位数。 |
| SMALLINT(size) | -32768 到 32767 常规。0 到 65535 无符号*。在括号中规定最大位数。 |
| MEDIUMINT(size) | -8388608 到 8388607 普通。0 to 16777215 无符号*。在括号中规定最大位数。 |
| INT(size) | -2147483648 到 2147483647 常规。0 到 4294967295 无符号*。在括号中规定最大位数。 |
| BIGINT(size) | -9223372036854775808 到 9223372036854775807 常规。0 到 18446744073709551615 无符号*。在括号中规定最大位数。 |
| FLOAT(size,d) | 带有浮动小数点的小数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DOUBLE(size,d) | 带有浮动小数点的大数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DECIMAL(size,d) | 作为字符串存储的 DOUBLE 类型,允许固定的小数点。 |
「日期/时间类型」
| DATE() | 日期。格式:YYYY-MM-DD注释:支持的范围是从 '1000-01-01' 到 '9999-12-31' |
|---|---|
| DATETIME() | *日期和时间的组合。格式:YYYY-MM-DD HH:MM:SS注释:支持的范围是从 '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59' |
| TIMESTAMP() | *时间戳。TIMESTAMP 值使用 Unix 纪元('1970-01-01 00:00:00' UTC) 至今的描述来存储。格式:YYYY-MM-DD HH:MM:SS注释:支持的范围是从 '1970-01-01 00:00:01' UTC 到 '2038-01-09 03:14:07' UTC |
| TIME() | 时间。格式:HH:MM:SS 注释:支持的范围是从 '-838:59:59' 到 '838:59:59' |
| YEAR() | 2 位或 4 位格式的年。注释:4 位格式所允许的值:1901 到 2155。2 位格式所允许的值:70 到 69,表示从 1970 到 2069。 |
上面的数据类型不用刻意去记忆,在具体使用的过程中可以查阅。其中文本类型常用的有varchar、longtext,数字类型常用的有int、decimal,日期/时间格式都常用。这里我们导入先不考虑数据类型,把所有数据认为是文本类型,设置成varchar(255)。完成建表后,就用语句将数据导入。
load data infile '../Uploads/data.csv'
into table ecommerce
fields terminated by ',' enclosed by '"'
lines terminated by '\n' ignore 1 lines;
load data infile '../Uploads/data.csv' into table ecommerce:将data.csv文件中的数据导入到ecommerce表中。这里的路径如果你填写本地的路径,可能会报错,告诉你没有处理权限。因此不简便起见,我们是把文件拷贝到具有MySQL处理权限的路径C:\ProgramData\MySQL\MySQL Server 8.0\Uploads中。
fields terminated by ',':字段间的分割符号,通常有逗号、制表符,制表符我们用'\t'来表示。
enclosed by '"':字段的包裹符号(可选)。如果我们每个字段是有符号包裹,而这个符号并不是我们需要的信息,那么就需要写这段语句。例如示例数据中不加这段语句时运行,会报错如下:
❝1262 - Row 110 was truncated; it contained more data than there were input columns
❞
意思是第110行被截断,原因是文件中数据列数超过表ecommerce的列数。我们打开文件查看第110行(排除表头)的第三列数据为:"AIRLINE LOUNGE,METAL SIGN",这个数据是由双引号包裹的,并且中间包含有字段的分割符:逗号。那么当我们不告诉系统enclosed by '"'时,系统会将这个字段以逗号分割,当成两个字段,导致报错。
lines terminated by '\n':行分割号,也相当于换行符。Windows系统中文件换行符为\n,Linux系统中文件换行符为\r\n。这里我们文件是Linux系统产生的,总之换行符可以两个都尝试下,能够找到正确的。
ignore 1 lines:忽略前几行(可选)。由于文件中第一行为表头,并不是我们需要的数据,因此需要忽略第一行。
导入语句从字面上很好理解,读者可以用示例数据尝试导入一次,就能够掌握。在SQL语句中分号代表一条语句的结束,前面语句虽然写成了4行,但只有最后结尾有一个分号,说明他还是一条语句。如果不用换行,将其写在一行,也是同样可以运行,因为SQL只识别分号作为结束,换行仅仅起到方便阅读的作用。
「LOAD DATA 语法」
LOAD DATA
[LOW_PRIORITY | CONCURRENT] [LOCAL]
INFILE 'file_name'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[CHARACTER SET charset_name]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number {LINES | ROWS}]
[(col_name_or_user_var
[, col_name_or_user_var] ...)]
[SET col_name={expr | DEFAULT}
[, col_name={expr | DEFAULT}] ...]
这是load data完整语法,中括号的语句为可选项,前面示例已详细讲解,这里不再赘述。
示例数据下载:
链接: https://pan.baidu.com/s/1do1O36sMD66k_yAgtvfMBQ 提取码: qjxt