科技创新的重要性和意义/优化大师免费版下载
干就完了
- 第一章 多表查询
- 1.1 内连接查询
- 1.1.1 隐式内连接
- 1.1.2 显示内连接
- 1.2 外连接查询
- 1.2.1 左外连接
- 1.2.2 右外连接
- 1.3 子查询
- 1.3.1 概述
- 1.3.2 子查询的不同情况
- 子查询的结果是单行单列的
- 子查询的结果是多行单列的
- 子查询的结果是多行多列的
- 1.4 多表查询练习
- 第二章 事务
- 2.1 事务基本介绍
- 2.2 事务的四大特征(重点)
- 2.3 事务的隔离级别(了解)
- 第三章 DCL (Data control language)
- 3.1 管理用户_增删查
- 查看数据库的用户
- 创建用户
- 删除用户
- 3.2 管理用户_修改密码
- 3.3 管理权限
- 查询权限
- 授予权限
- 撤销权限
- 3.3 管理权限
- 查询权限
- 授予权限
- 撤销权限
第一章 多表查询
注意! 这里我们所有的举例都是基于下面的两个表例的
查询语法
select列名
from表名
where条件
这是两个表例
emp
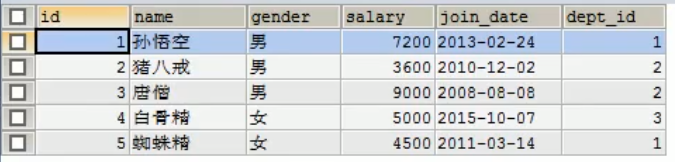
dept

其中dept_id是外键,它指向id
我们使用查询语句
select * from emp,dept ;
结果显示

我们会发现,搜索两个表的时候,我们就会遇到一些问题,数据默认是笛卡儿积,有很多冗余的错误的数据,两个表的id和dept_id对不上
笛卡尔积: 有两个集合A,B, 取这两个集合的所有组成情况
多表查询分类
- 内连接查询
- 外连接查询
- 子查询
1.1 内连接查询
基本查询思维逻辑
- 从哪些表中查询数据
- 条件是什么(确定外键约束,避免发生数据冗余)
- 查询哪些字段
1.1.1 隐式内连接
通过where条件来去除冗余的数据
例如:刚才的例子,我们使用
select * from emp, dept where dept.`id` = emp.`dept_id`; -- 引号加不加都行

我们会发现问题已经解决
再例如: 我们查询员工表的名称,性别,部门表的名称
select emp.name,emp.gender,dept.name from emp,dept where emp.dept_id = dept.id;
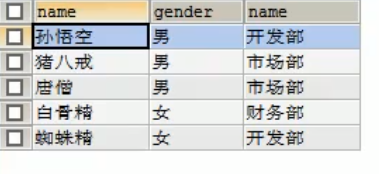
当然,这样有点麻烦,因为有可能表的名字很长,所以我们可以给表起别名,起到简化的效果
select t1.name,t1.gender,t2.name from emp t1,dept t2 where t1.dept_id = t2.id;
1.1.2 显示内连接
语法:
select 字段列表 from 表名1 [inner] join 表名2 on 条件;
这里inner是可选的
回到最初的例子,我们为了去除冗余的数据,我们用下列的语句
select * from emp inner join dept on emp.dept_id = dept.id;
这里得出的效果和我们上面用隐式内连接的出的效果是一样的
1.2 外连接查询
1.2.1 左外连接
作用: 查询的是左表所有数据,以及其两个表的交集的部分(满足条件的部分)
语法:
select 字段列表 from 表1 left [outer] join 表2 on 条件;
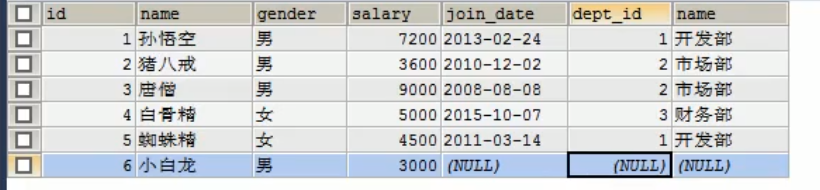
例如: 我们案例里面添加了一个小白龙,但是他没有加入任何部门,我们多表查询他的时候又不想让他不显示,因此,我们就使用左外连接
select t1.* , t2.name from emp t1 left join dept t2 on t1.dept_id = t2.id;
结果如图
1.2.2 右外连接
作用: 显示所有的右表的部分(join后面的那个表) 以及两个表的交集部分
select 字段列表 from 表1 right [outer] join 表2 on 条件;
其实就是和左表相反
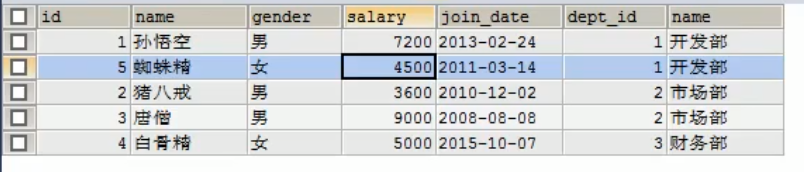
那么执行下面的代码(其实就是刚才左外连接的代码换了一个单词)
select t1.* , t2.name from emp t1 right join dept t2 on t1.dept_id = t2.id;
我们发现,小白龙不见了,原因很简单,因为小白龙和右表没有交集(不满足条件)
1.3 子查询
1.3.1 概述
概念: 查询中嵌套查询,称嵌套查询称为子查询。
例如: 我们要查询一个表中工资最高的人(用之前的emp表)
通常,如果我们不用子查询,我们就要分两步
select MAX(salary) from emp;-- 我们查出来最高工资是9000,然后select * from emp WHERE emp.salary = 9000;-- 至此,我们就找到了这个工资最高的人的所有信息
这里我们用子查询,就可以合并为一句
select * from emp WHERE emp.salary = (select MAX(salary) from emp);
我们会发现结果是一样的,所以说这里结果就显而易见了
1.3.2 子查询的不同情况
我们子查询得到的不同结果可以有多种不同的用途。
子查询的结果是单行单列的
-
作为条件使用:像上一个小节的例子,我们这里子查询的语句就作为条件使用 (运算符是: > < = 之类的算数运算符)
-
举例: 查询工资小于平均工资的员工
-
select * from emp where emp.salary < (select AVG(emp.salary) from emp);
-
子查询的结果是多行单列的
-
作为条件使用: (使用运算符 IN() 来作为条件判断)
-
例子: 查询在财务部门和市场部门的所有的员工的信息
-
select * from emp,dept where emp.dept_id in (select id from dept where name = "财务部" or name = "市场部");
-
子查询的结果是多行多列的
-
作为一张(虚拟)表来使用:
-
例子: 查询员工的入职日期在2011年11月11号11日之后的员工信息和部门信息
-
select * from dept t1,(select * from emp where join_date > '2011-11-11') t2 where t1.id = t2.dept_id; -
-- 其实用普通的内连接也可以写select * from emp t1, dept t2 where t1.id = t2.dept_id and t1.join_date > '2011-11-11';
-
1.4 多表查询练习
寻找资料中
第二章 事务
2.1 事务基本介绍
**概念: 如果一个包含多个步骤的业务操作被事务管理,那么这些操作要么同时成功,要么同时失败 **
举例:
//张三给李四转账500块//要经过下列的步骤
1 检测张三余额是否大于500
2 张三的余额-500
3 李四的余额+500//在这里,我们假设,步骤进行到3的时候失败了,但是2已经执行了,这样张三不就平白无故失去了500吗? // 因此, 为了避免这种情况,我们对"张三给李四转账500块"这个业务操作进行事务管理,这样,只要其中一步出错了,所有都会失败,这样就避免了莫名其妙的损失
事务的基本操作(sql语句)
- 开启事务: start transaction;
- 回滚(步骤执行失败的时候执行): rollback;
- 提交事务: commit
现在我们用sql来实现刚才张三李四的那些操作
CREATE TABLE account (id INT PRIMARY KEY AUTO_INCREMENT,NAME VARCHAR(10),balance DOUBLE -- 余额);-- 添加数据INSERT INTO account(NAME,balance) VALUES ('zhangsan',1000), ('lisi',1000);-- 开启事务
START TRANSACTION;-- 第一步跳过-- 第二步 张三账户 -500
update account set balance = balance -500 where name = "zhangsan";
啊啊啊我是错误
-- 第三步 李四账户 + 500
update account set balance = balance +500 where name = "lisi";执行完这个之后,我们发现数据变成了这样
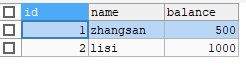
我们会发现李四的钱没有到账,语句出错了,但是不要担心,因为我们开启了事务其实这里显示的数据只是暂时数据(起到了一个提示你哪里出错的作用),数据库的实际数据没有被改变,我们可以在这个页面下使用回滚操作,就可以将这个暂时的数据回滚回我们使用开启事务那个语句时候的数据库的状态
-- 发现问题了,回滚事务
ROLLBACK;
执行这个语句之后,我们发现两个人的余额的数据恢复回了开启事务前的状态
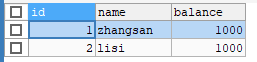
我们把错误去除之后,就应该提交事务,这里数据库的数据就真正改变了
commit;
注意!
-
MySQL数据库中事务默认自动提交 (一次DML语句之后回自动提交一次事务)
-
我们使用的(start transaction)语句其实就相当于开启一个手动提交(手动输入commit)的事务
-
顺口一提, oracle数据库是默认手动提交的
修改事务的默认提交方式
-
查看事务的默认提交方式
select @@autocommit; -- 1 代表自动提交 -- 0 代表手动提交 -
修改默认提交方式:
set @@autocommit = 0;
2.2 事务的四大特征(重点)
- 原子性: 事务是不可分割的最小操作单位(要么同时成功,要么同时失败)
- 持久性: 如果事务一旦提交或者回滚,那么数据库的数据将会持久更新(数据驻留到硬盘里)
- 隔离性: 多个事务之间. 相互独立.
- 一致性: 事务操作前后,数据总量不变
2.3 事务的隔离级别(了解)
概念: 多个事务之间是隔离的(相互独立的),但是如果多个事务操作同一批数据,则会引发一些问题,设置不同的隔离级别可以解决这些问题.
不设置隔离级别,存在的问题
- 脏读: 一个事务,读取到另一个事务中没有提交的数据
- 不可重复读 (虚读) : 在同一个事务中,两次读取到的数据不一样
- 幻读: 一个事务操作(DML)数据表中所有的记录,另一个事务添加了一条数据,则第一个事务查询不到自己的修改
隔离级别
- read uncommitted: 读未提交
- 产生的问题: 脏读,不可重复读,幻读
- read committed: 读已提交 (Oracle默认)
- 不可重复读, 幻读
- repeatable read : 可以重复读 (MySQL 默认)
- 幻读
- serializable: 串行化 (一个表在被一个事务操作的时候,其他事务不能访问这个表,直到事务使用完毕)
- 可以解决所有问题
注意: 隔离级别从限制低到限制高,他们的安全性越来越高,但是效率却会越来越低 ,因此我们要结合实际来选择隔离级别
数据库查询隔离级别
select @@tx_isolation;
数据库设置隔离级别
set global transaction isolation level 级别字符串(例如: repeatable read);
第三章 DCL (Data control language)
作用: 管理用户,授权
这里我们只需要了解就行了,因为公司有专门的数据库管理员
3.1 管理用户_增删查
查看数据库的用户
在mysql页面里面 查看"MySQL"这个数据库里面的"user"表
use mysql;select * from user;
Host列中 "%"符号的意思是,所有主机都可以访问这个用户
创建用户
create user '用户名'@'主机名' identified by '密码';
删除用户
drop user '用户名'@'主机名';
3.2 管理用户_修改密码
update user set password = PASSWORD("新密码") WHERE USER = "用户名";
PASSWORD()这个函数就是给我们设的密码加密,因为数据库user表里面保存的密码就是已经加密过的
还有简便语法
set password for '用户名'@'主机名' = PASSWORD('新密码');
忘记了root用户的密码怎么办?
-
在MySQL中,忘记了MySQL密码,
- 在cmd中输入 net stop mysql (以管理员权限运行)
- 使用无验证启动Mysql服务: mysqld --skip-grant-tables
- 然后我们就可以不用输入密码就进入Mysql
- 然后我们就用修改密码的语句修改密码
- 在任务管理器中手动关闭 mysqld 进程
- cmd中输入 net start mysql 启动sql服务
- 用新密码登录就行了
3.3 管理权限
查询权限
show grants for '用户名'@'主机名';
授予权限
grant 权限列表 on 数据库.表名 to '用户名'@'主机名';
所有权限的通配符是"ALL" 所有数据库的所有表的通配符是" * . * "
撤销权限
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';
cmd中输入 net stop mysql (以管理员权限运行)
2. 使用无验证启动Mysql服务: mysqld --skip-grant-tables
3. 然后我们就可以不用输入密码就进入Mysql
4. 然后我们就用修改密码的语句修改密码
5. 在任务管理器中手动关闭 mysqld 进程
6. cmd中输入 net start mysql 启动sql服务
7. 用新密码登录就行了
3.3 管理权限
查询权限
show grants for '用户名'@'主机名';
授予权限
grant 权限列表 on 数据库.表名 to '用户名'@'主机名';
所有权限的通配符是"ALL" 所有数据库的所有表的通配符是" * . * "
撤销权限
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';