b2b和b2c平台/沧州seo公司
1.sparkStreaming是什么?
sparkStreaming 其实是对RDD进行微批量处理,核心还是对RDD的操作。
只不过spark是线程级的应用,实现秒级的运算是可以的。
所以sparkStreaming并不是真正意义上的流处理,最多实现秒级响应,无法做到毫秒级。
所以sparksSreaming比较适合 实时和批量数据相结合的场景。
2.sparkStreaming工作机制
跟spark工作机制非常相似,因为本身就是spark对RDD的操作。
1.每个workerNode中会有一个 receiver

2.receiver 会对接一个input DStream,input DStream负责源源不断的输入数据。

receiver 主要任务就是负责对接input DStream ,接收并处理流数据。

input DStream 对接的数据流可以有多种,
套接字流:通过socket 不断发送数据。
文件流:监听文本,文件一旦发生改变就传输文本
KAFKA:接收kafka的数据流

3.sparkStreaming的编写步骤
3.1创建DStream 来定义输入源

和创建spark-shell的 sparkContext 简称 sc ,
sparkSQL的 sparkSession 简称 spark类似。
sparkStreaming 需要的 streamContext 简称ssc
ps:如果pom.xml中 没有配置sparkStreaming 依赖,需要先导入依赖。
可以参照下边添加sparkSession依赖的文章,添加sparkStreaming
在idea中pom.xml添加sparkSQL依赖_hzp666的博客-CSDN博客_idea添加spark依赖
第一步创建创建 spark的指挥所,

如果在spark-shell中编写的话,因为自动创建了 sparkContext ,即sc
所以创建StreamingContext时,只用 传递 sc 参数
val ssc = new StreamingContext(conf,Seconds(2))
如果在idea中编程,创建StreamingContext 时候,需要声明 SparkConf,并传入 conf, 而不是sc
//create spark commander
val ssc = new StreamingContext(conf,Seconds(2))
val conf = new SparkConf().setMaster("local[2]").setAppName("streamingTest")val ssc = new StreamingContext(conf,Seconds(2))
ps:另外注意 setMaster("local[2]") 中 至少要2个线程,一个负责接收数据,一个负责处理。直接写local 或者 local[1] 都不行。
第二步,生成input 输入流
下边案例是文本流:
//read
val lines = ssc.textFileStream("D:/doc/spark/streaming")

3.2 编写对流数据的转换和操作

//transfer
val countedRDD: DStream[(String, Int)] = lines.flatMap(_.split("/[\\s\\n]/")).map(x => (x, 1)).reduceByKey(_+_)
//print ,for visual the result countedRDD.print()
3.3 启动程序

//start ssc.start()
3.4 结束
发生错误时结束

//stop ssc.awaitTermination()
3.5 手动结束

ssc.stop()
4.文本流完整案例:
import org.apache.spark._
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}object sparkStreamingTest {def main(args: Array[String]): Unit = {//create spark commanderval conf = new SparkConf().setMaster("local[2]").setAppName("streamingTest")val ssc = new StreamingContext(conf,Seconds(5))//readval lines = ssc.textFileStream("D:/doc/spark/streaming")//transferval countedRDD: DStream[(String, Int)] = lines.flatMap(_.split(" ")).map(x => (x, 1)).reduceByKey(_+_)//printcountedRDD.print()//startssc.start()//stopssc.awaitTermination()}
}
运行效果:

5.
PS 注意事项:
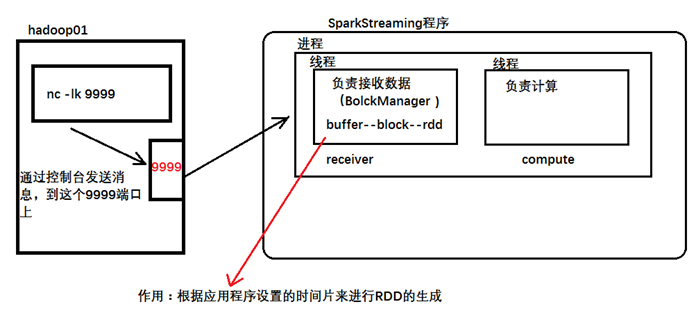
如果在计算的时候,指定--master时 使用的是local 并且只指定了一个线程,那么只有receiver线程工作,计算的线程不会工作,所以在指定线程数的时候,最少指定2个。
(2)通过输入源创建InputDStream:
在构建好StreamingContext之后,首先我们要读取数据源的数据进行实时处理:
InputDStreams指的是从数据流的源头接收的输入数据流,每个 InputDStream 都关联一个 Receiver 对象,该 Receiver 对象接收数据源传来的数据并将其保存在内存中以便后期 Spark 处理。
Spark Streaming 提供两种原生支持的流数据源和自定义的数据源:
- 直接通过 StreamingContext API 创建,例如文件系统(本地文件系统及分布式文件系统)、 Socket 连接及 Akka 的 Actor。
- Kafka, Flume, Kinesis, Twitter 等,需要借助外部工具类,在运行时需要外部依赖
-Spark Streaming 还支持用户自定义数据源,它需要用户定义 receiver
注意:
- 在本地运行 Spark Streaming 时,master URL 不能使用”local”或”local[1] ”,因为当 Input DStream 与 Receiver(如 sockets, Kafka, Flume 等)关联时,Receiver 自身就需要一个线程 来运行,此时便没有线程去处理接收到的数据。因此,在本地运行 SparkStreaming 程序时,要使用”local[n]”作为 master URL,n 要大于 receiver 的数量。
- 在集群上运行 Spark Streaming 时,分配给 Spark Streaming 程序的 CPU 核数也必须大于 receiver 的数量,否则系统将只接受数据,无法处理数据。
(3)对DStream进行transformation 和 output 操作,这样操作构成了后期流式计算的逻辑
(4)通过streamingContext.start()方法启动接收和处理数据的流程
(5)使用streamingContext.awaitTermination()方法等待程序结束(手动停止或出错停止)
(6)调用streamingContext.stop()方法来结束程序的运行。
在编写sparkStreaming时的注意点:
- streamingContext启动后,增加新的操作将不起作用,一定要在启动之前定义好逻辑,也就是说在调用start方法之后,在对sparkStreaming程序进行逻辑操作是不被允许的
- StreamingContext 是单例对象停止后,不能重新启动,除非重新启动任务,重新执行计算
- 在单个jvm中,一段时间内不能出现两个active状态的StreamingContext
- 当在调用 StreamingContext 的 stop 方法时,默认情况下 SparkContext 也将被 stop 掉, 如果希望 StreamingContext 关闭时,能够保留 SparkContext,则需要在 stop 方法中传入参 数 stop SparkContext=false
- 一个 SparkContext 可以用来创建多个 StreamingContext,只要前一个 StreamingContext 已经停止了。