网站图片 优化/hao123网址之家官网
Kafka为什么查询速度快
分段
Kafka解决查询效率的手段之一是将数据文件分片,数据文件以该段中最小的offset命名。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段(segment)中。
稀疏索引
为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。
索引包含两个部分(均为4个字节的数字),分别为相对offset和position。
index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。
这样避免了索引文件占用过多空间,从而可以将索引文件保留在内存中。
但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
示例:Kafka 查找message

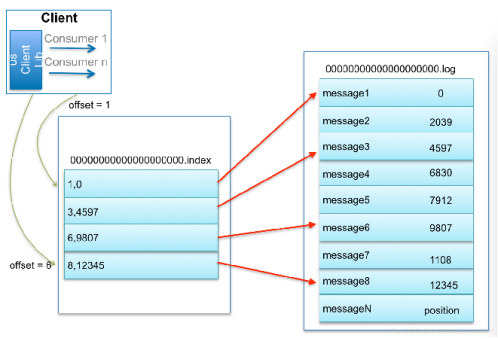
比如:要查找绝对offset为7的Message:
首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
这套机制是建立在offset是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。
一句话,Kafka的Message存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达到了高效性。
顺序读写
零拷贝
所谓的零拷贝是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之
手。零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换 ,对linux
操作系统而言,零拷贝技术依赖于底层的 se ndfile () 方法实现 对应于 Java 语言,
Fi eChannal.transferTo ()方法的底层实现就是 sendfile ()方法
零拷贝技术通过 DMA (Direct Memory Access )技术将文件内容复制到内核模式下的 Read
Buffer 。不过没有数据被复制到 Socke Buffer ,相反只有包含数据的位置和长度的信息的文
件描述符被加到 Socket Buffer DMA 引擎直接将数据从内核模式中传递到网卡设备(协议
引擎)。这里数据只经历了 2次复制就从磁盘中传送出去了 并且上下文切换也变成了2 次。
零拷贝是针对内 核模式而言的 数据在内核模式下实现了零拷贝
批量发送
生产者发送多个消息到同一个分区的时候,为了减少网络带来的系能开销,kafka会对消息进行批量发送
batch.size
通过这个参数来设置批量提交的数据大小,默认是16k,当积压的消息达到这个值的时候就会统一发送(发往同一分区的消息)
数据压缩。
Producer 端压缩、Broker 端保持、Consumer 端解压缩。