做网站获取手机号码/谷歌优化培训
此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。
本文章纯野生,无任何借鉴他人文章及抄袭等。坚持原创!!
前言
你好。这里是Python爬虫从入门到放弃系列文章。我是SunriseCai。
本文章主要介绍利用爬虫程序下载 英雄联盟的 所有英雄的皮肤。
1. 文章思路
看看英雄联盟网站,如下多图所示:
首页(一级页面)
皮肤页面(二级页面)
图片(三级页面)
通过上面几张图片可以看出,这一套下来依旧是个俄罗斯套娃!!!
访问 首页(一级页面) 获取 所有英雄链接(二级页面)
访问 英雄链接(二级页面) 获取 图片链接(三级页面)
访问 图片链接(三级页面),保存图片。

那么,接下来的就是用代码实现下载图片了。
2. 请求 + 分析 网页
上面有说到,本文章的需请求的首页为https://lol.qq.com/data/info-heros.shtml。
2.1 请求首页
浏览器打开 网站首页,点击F12,进入开发者模式。看看页面结构,发现了二级页面的链接就在
标签里面。perfect !!!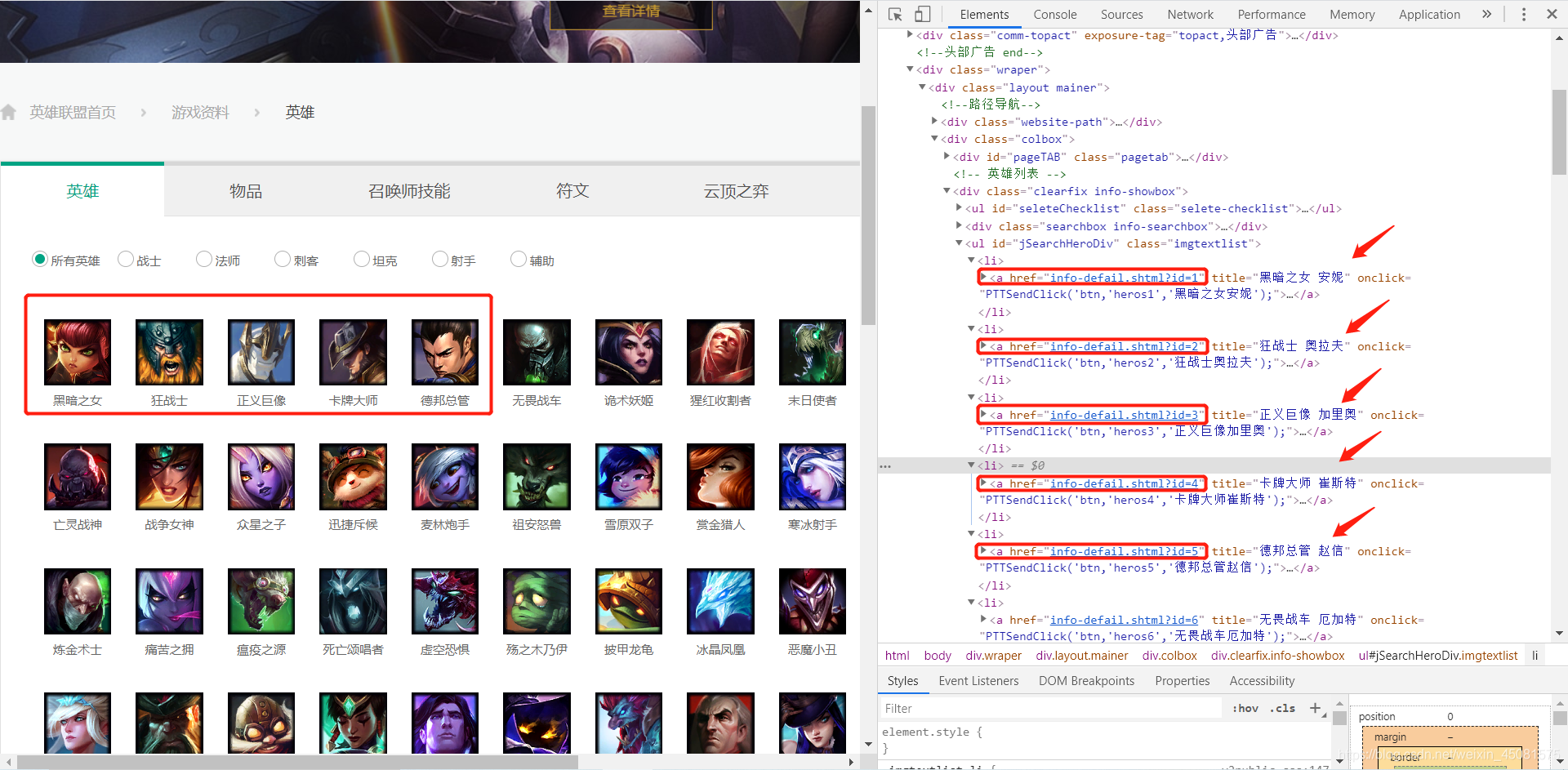
相信细心的你已经发现,二级页面url的规律为:https://lol.qq.com/data/info-defail.shtml?id= 这一串字符后面跟一个数字,那这个数字是如何而来的呢?下面会讲解到。
首页请求代码:
import requests
url = 'https://lol.qq.com/data/info-heros.shtml'
headers = {
'User-Agent': 'Mozilla/5.0'
}
def get_hero_list():
res = requests.get(url, headers=headers)
if res.status_code == 200:
print(res.text)
else:
print('your code is fail')
!!!
执行上述代码之后,发现并没有上图中的
标签的内容,这是怎么回事呢?标签的内容极有可能是通过xhr异步加载出来的的文件,咱们来抓包看看!!再次请求首页时候发现,在xhr这里,有一个hero_list.js文件,翻译过来就是英雄列表。
看到hero_list.js的url为 :https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js
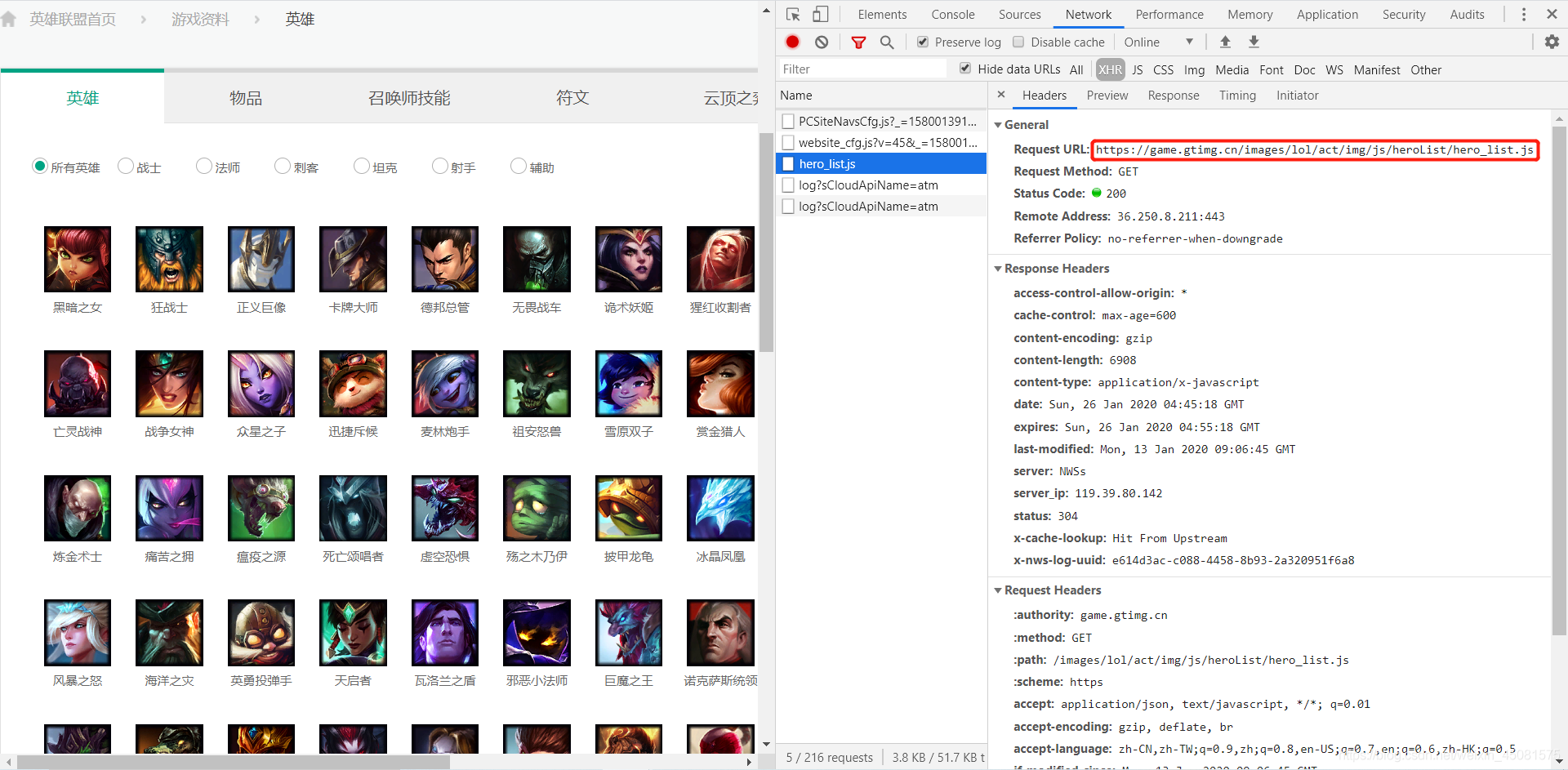
点击之后,发现这正是我们需要的内容!!!
就是这里,注意看画框红色的地方有一个heroId,这个就是上面说的二级页面url屁股的Id
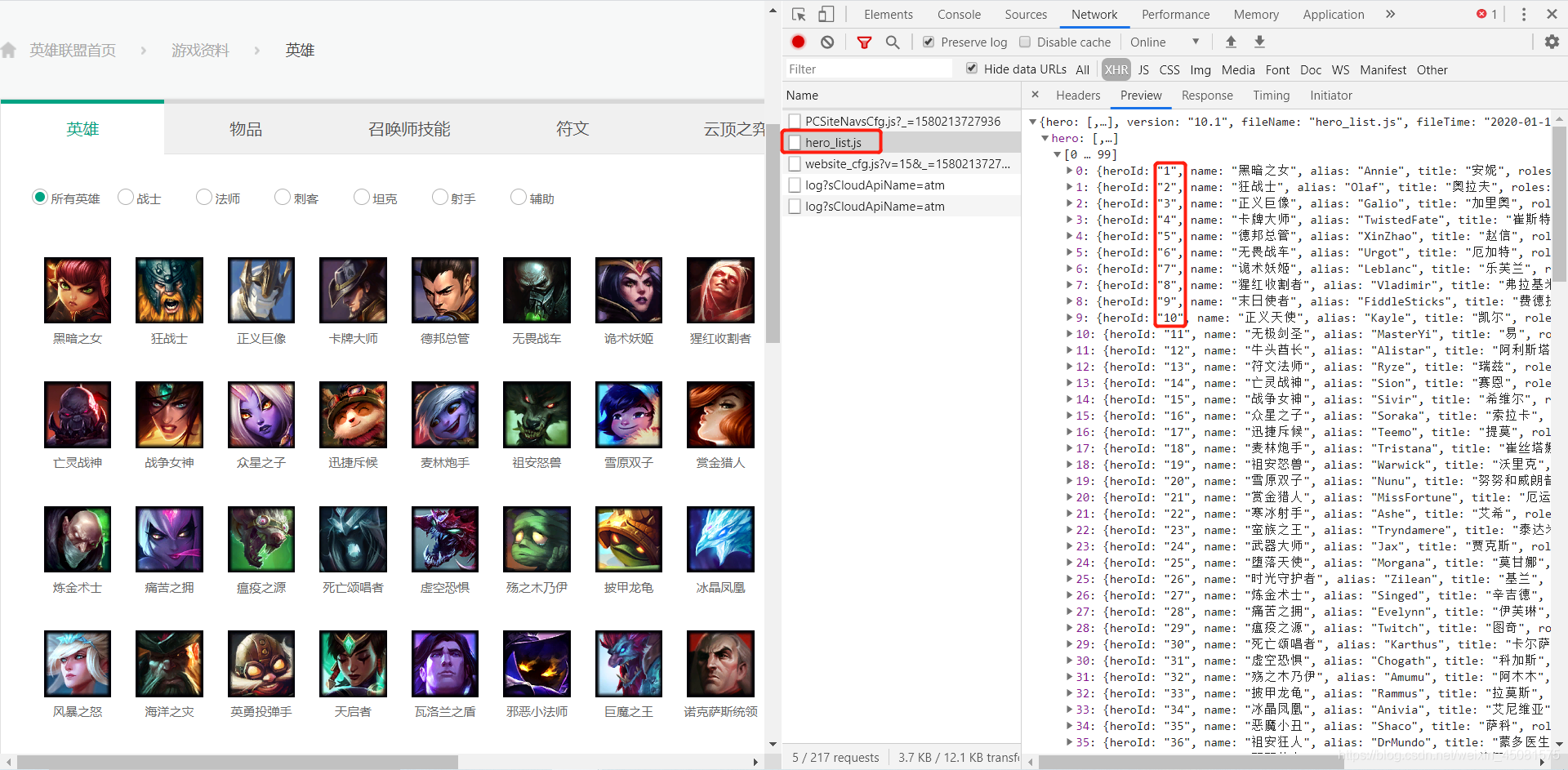
在浏览器输入hero_list.js文件的地址,如下图:
非常好,请求代码也是很简单,只需要将上面代码的url替换为https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js 即可。
2.2 请求二级页面(皮肤页面 )
这里以黑暗之女–安妮 为例,看到安妮共有13个皮肤。
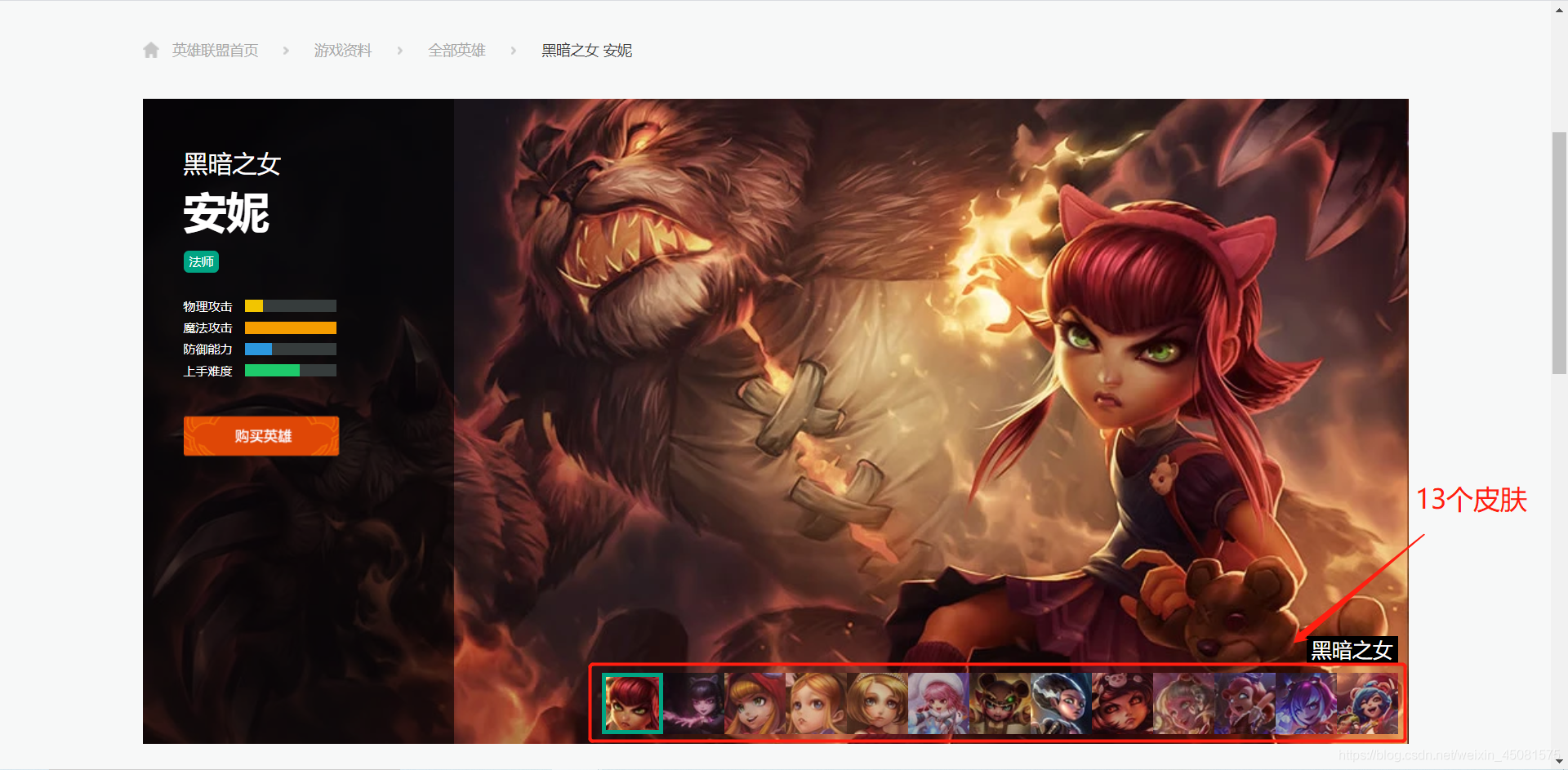
抓包发现,有个1.js文件的数据刚好对应了安妮的13个皮肤。
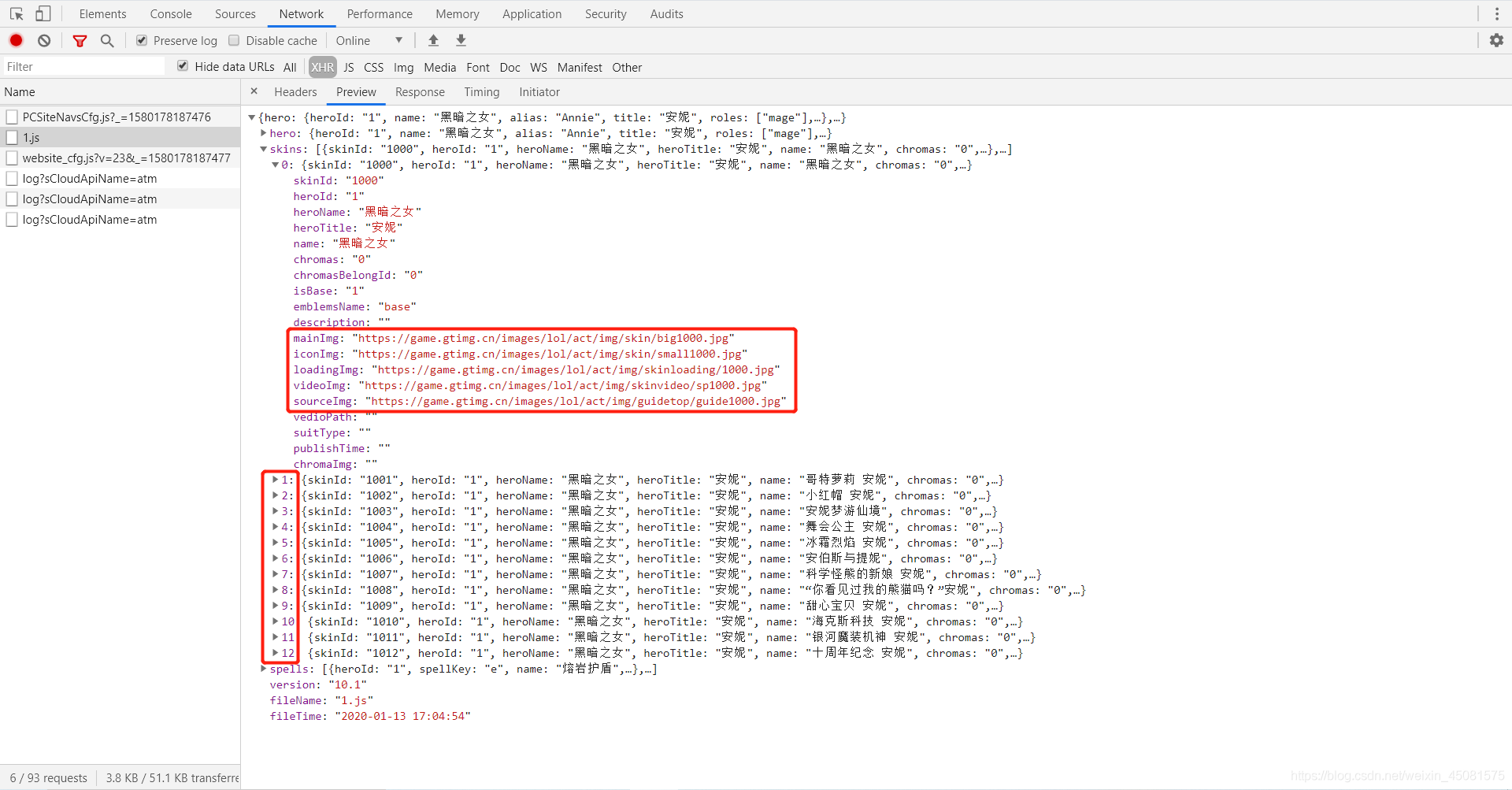
1.js文件的url为:https://game.gtimg.cn/images/lol/act/img/js/hero/1.js
2.js文件的url为:https://game.gtimg.cn/images/lol/act/img/js/hero/2.js
当然了,这个后面的Id就是每个英雄的heroId。
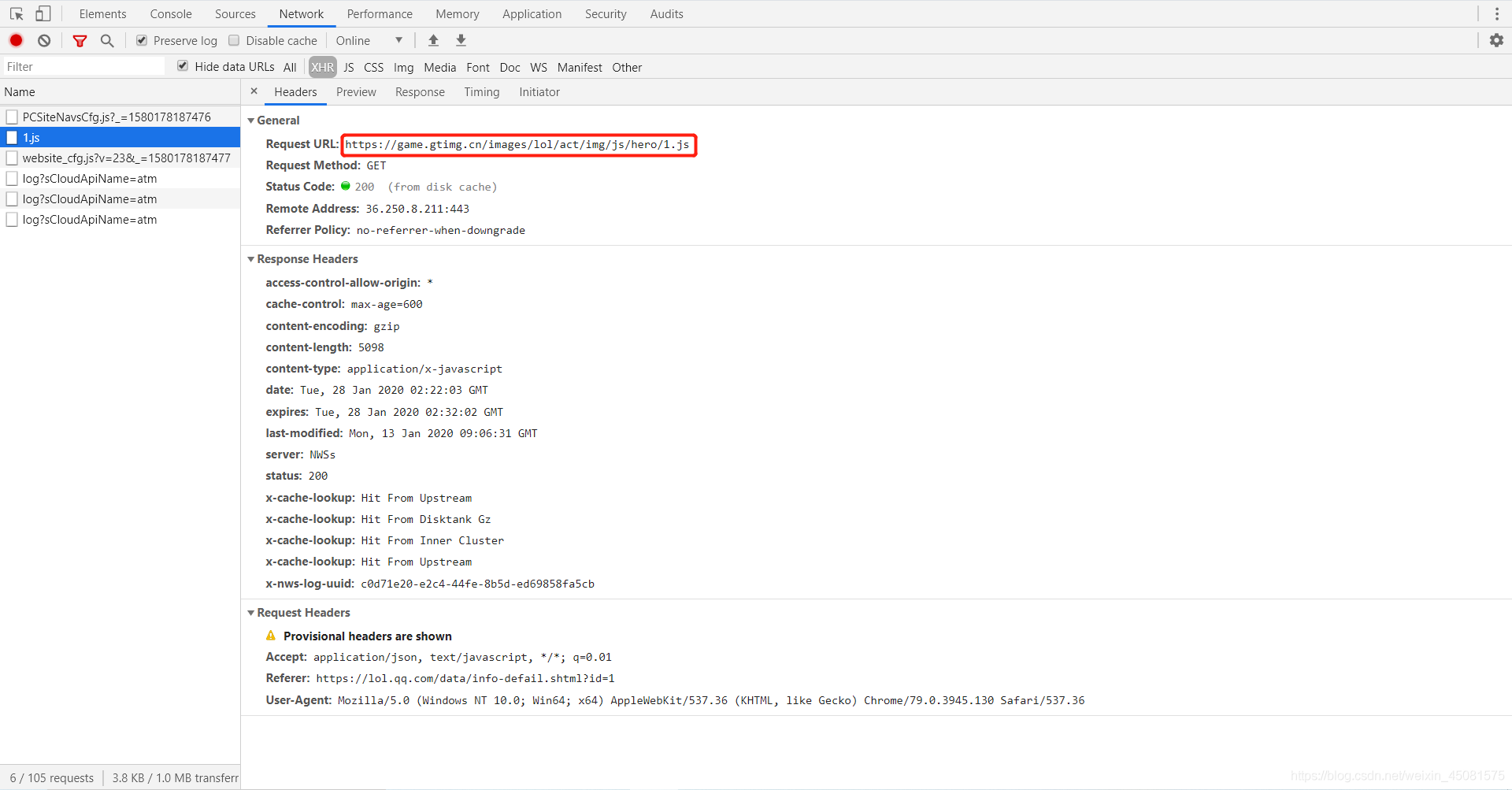
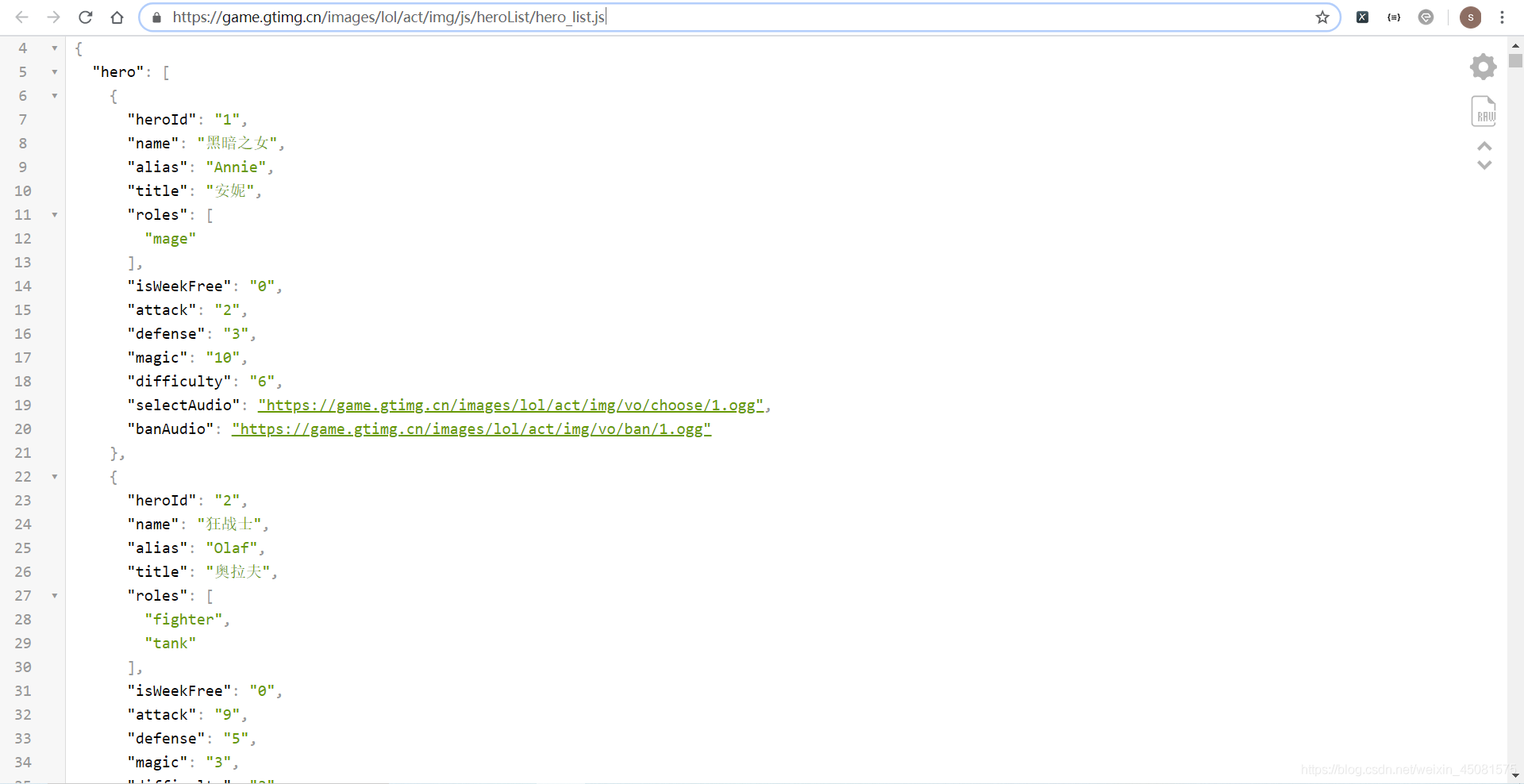
用浏览器打开1.js文件的url,如下图所示:

看到1.js文件有几个img的url,他们所表示图片的像素比如下:
名称
像素比mainImg
980x500
iconImg
60x60
loadingImg
308x560
videoImg
130x75
sourceImg
1920x470
本次文章用mainImg做下载演示。
在这里,捋一下思路:
请求https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js 获取英雄名称、Id。
根据Id去拼接英雄皮肤的url:https://game.gtimg.cn/images/lol/act/img/js/hero/1.js(Id替换数字1)
上述请求后可以得到图片的url了,请求图片url即可。
3. 代码部分
3.1 代码:首页
请求首页,获取二级页面(皮肤页面的链接)import requests
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
headers = {
'User-Agent': 'Mozilla/5.0'
}
def get_hero_list():
"""
:return: 获取英雄名称与heroId
"""
res = requests.get(url, headers=headers)
if res.status_code == 200:
data = json.loads(res.text)
for item in data['hero']:
id = item['heroId']
name = item['name']
title = item['title']
print(id, name, title)
else:
print('your code is fail')
get_hero_list()
结果如下:

3.2 代码:二级页面(皮肤页面)
import requests
skinUrl = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'
headers = {
'User-Agent': 'Mozilla/5.0'
}
def get_skin_url(Id):
"""
:param Id: 英雄ID,用于拼接url
:return:
"""
res = requests.get(skinUrl.format(Id), headers=headers)
if res.status_code == 200:
data = json.loads(res.text)
for item in data['skins']:
url = item['mainImg']
name = item['name'].replace('/', '')
print(url, name)
else:
print('your code is fail')
get_hero_list()
结果如下:
值得注意的是,如果是一款皮肤有多个颜色的情况,则有可能不带mainImg的url。
3.3 完整代码
复制黏贴即可运行# -*- coding: utf-8 -*-
# @Time : 2020/1/28 21:12
# @Author : SunriseCai
# @File : YXLMSpider.py
# @Software: PyCharm
import os
import json
import time
import requests
"""英雄联盟皮肤爬虫程序"""
class YingXLMSpider(object):
def __init__(self):
self.onePageUrl = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
self.skinUrl = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'
self.headers = {
'User-Agent': 'Mozilla/5.0'
}
def get_heroList(self):
"""
:return: 获取英雄的heroId,和英雄名称
"""
res = requests.get(url=self.onePageUrl, headers=self.headers)
if res.status_code == 200:
data = json.loads(res.text)
for item in data['hero']:
Id = item['heroId']
title = item['title']
self.get_skin_url(Id, title)
else:
print('your code is fail')
def get_skin_url(self, Id, folder):
"""
:param Id: 英雄ID,用于拼接url
:param folder: 以英雄名称命名的文件夹
:return:
"""
url = self.skinUrl.format(Id)
res = requests.get(url, headers=self.headers)
if res.status_code == 200:
data = json.loads(res.text)
for item in data['skins']:
url = item['mainImg']
name = item['name'].replace('/', '')
self.download_picture(url, name, folder)
else:
print('your code is fail')
def download_picture(self, url, name, folder):
"""
:param url: 皮肤地址
:param name: 皮肤名称
:param folder: 文件夹
:return:
"""
# 判断如果文件夹不存在则创建
if not os.path.exists(folder):
os.makedirs(folder)
# 判断url不为空和 图片不存在本地则下载(主要用于断点重连)
if not url == '' and not os.path.exists('%s/%s.jpg' % (folder, name)):
time.sleep(1)
res = requests.get(url, headers=self.headers)
with open('%s/%s.jpg' % (folder, name), 'wb') as f:
f.write(res.content)
print('%s.jpg' % name, '下载成功')
f.close()
def main(self):
self.get_heroList()
if __name__ == '__main__':
spider = YingXLMSpider()
spider.main()
来看看成果:


本篇文章很水,但是总体思路是正确的。建议各位通过复制黏贴代码去执行一番,有任何疑问请先自己动手解决,尽信书则不如无书
实在解决不了可以一起交流哟。
最后来总结一下本章的内容:
介绍了英雄联盟网站全英雄皮肤的爬虫思路
代码展示
无

感谢你的耐心观看,点关注,不迷路。
为方便菜鸡互啄,欢迎加入QQ群组织:648696280
下一篇文章,名为 《Python爬虫从入门到放弃 09 | Python爬虫实战–下载某音乐网–待定》。