网站不收录是什么原因/鞍山做网站的公司
定义:顾名思义就是整个聚类过程分为前后两个大的板块来完成。
第一步对所有记录进行距离考察,构建CF分类特征树,同一个树节点内的记录相似度高,相似度差的记录则会生成新的节点。第二步,在分类树的基础上,使用凝聚法对节点进行分类,每一个聚类结果使用BIC或者AIC进行判断,得出最终的聚类结果。
背景:样本数据聚类效果的好与坏,参与聚类的变量在其中的作用至关重要。而现实中,聚类变量可能是连续数据,也可能是类别数据,所以诸如层次聚类和K均值聚类这样的统计方法,它们在类别变量数据面前就显得不足够实用了。
二阶聚类法,则可以完美解决这个问题。它的优势至少表现在以下几个方面:
- 可同时基于类别变量和连续变量进行聚类;
- 可自动确定最终的分类个数;
- 可处理大型数据集;
前提假设:其实稍微违反假设条件其实也不要紧,结果很稳健,其会自动剔除异常值
- 变量间彼此独立
- 分类变量服从多项分布,连续变量服从正态分布
特点:
- 处理对象:分类变量和连续变量
- 自动决定最佳分类数
- 快速处理大数据集
1.问题描述:
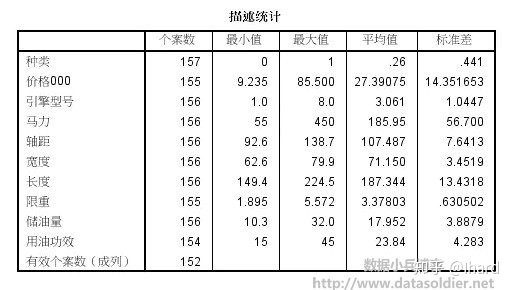
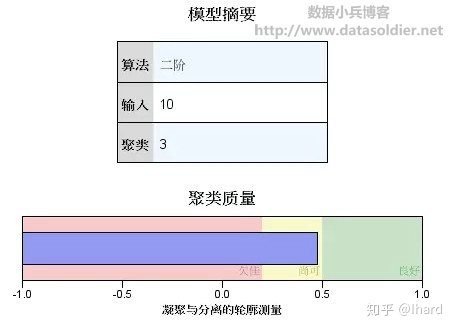
汽车生产厂商需要有效的方法评价当前市场情况,了解市场需要,找到受市场欢迎的,有市场竞争力的车型配置。案例将采用种类、价格、引擎型号、马力、轴距、宽度、长度、限重、储油量、用油功效共10个变量对152条有效记录进行自动聚类。
2.假设检验
变量独立性和连续变量服从正态分布检验这里不做赘述
3.SPSS操作
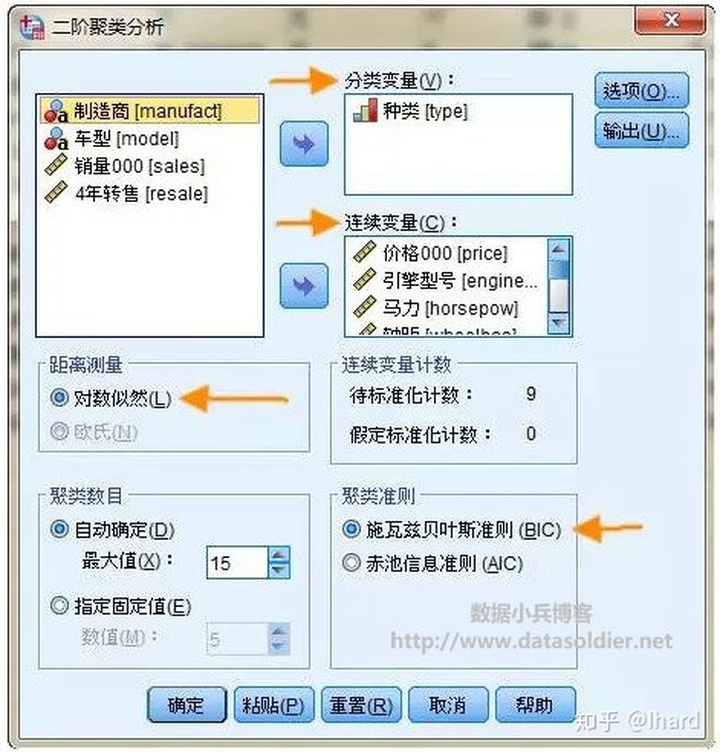
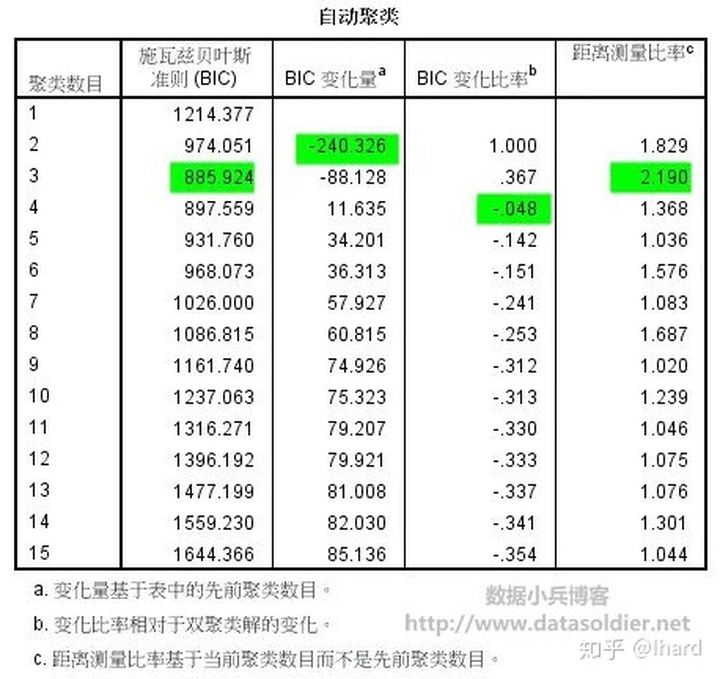
- 【距离测量】:确定计算两个变量之间的相似性,对数相似值系统使用对数似然距离计算,而欧式距离是以全体变量为连续性变量为前提的,由于我们的数据中存在分类型变量,因此这里选择对数相似值。
- 【聚类数量】:允许指定如何确定聚类数。如果自动确定将会使用聚类准则中指定的准则[BIC 或者 AIC],自动确定最佳的聚类数,或者设置最大值。也可以指定一个固定值,不过一般来说就自动确定OK了。
- 【连续变量计数】:对一个变量是否进行标准化的设置。系统自动计算。
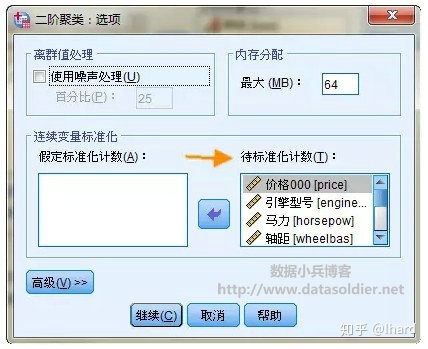
离群值处理:这里主要是针对CF填满后,如何对离群值的处理。
“如果选择噪声处理且 CF树填满,则在将稀疏叶子中的个案放到“噪声”叶子中后,树将重新生长。如果某个叶子包含的个案数占最大叶大小的百分比小于指定的百分比,则将该叶子视为稀疏的。树重新生长之后,如有可能,离群值将放置在 CF 树中。否则,将放弃离群值。如果不选择噪声处理且 CF树填满,则它将使用较大的距离更改阈值来重新生长。最终聚类之后,不能分配到聚类的变量标记为离群值。离群值聚类被赋予标识号–1,并且不包含在聚类数的计数中。”
关于噪声处理,此处默认不选即可。
内存分配:指定聚类算法应使用的最大的内存量。如果该过程超过了此最大值,则将使用磁盘存储内存中放不下的信息。此项默认就行了。
连续变量的标准化:聚类算法处理标准化连续变量。软件自动将9个连续型聚类变量纳入框内,表示软件将对这些变量自动进行标准化处理,以统一测量尺度。
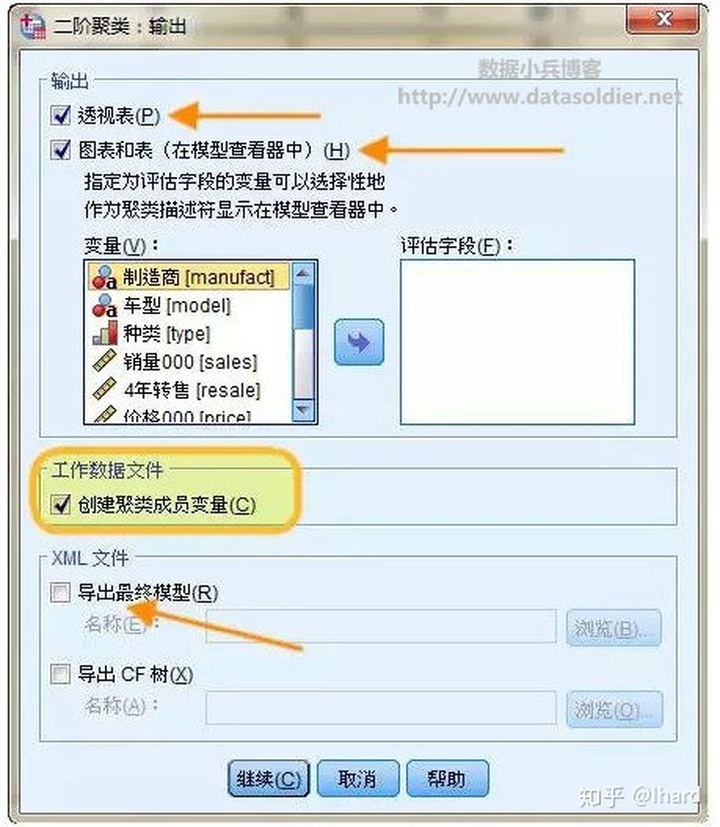
1.透视表。输出的结果主要出现在结果查看器(主要是表格形式);
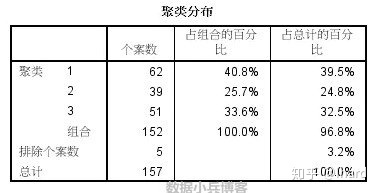
2.图表和表。显示模型相关的输出,包括表和图表。模型视图中的表包括模型摘要和聚类-特征网格。模型视图中的图形输出包括聚类质量图表、聚类大小、变量重要性、聚类比较网格和单元格信息。
重要。输出的结果出现在模型查看器(可视化程度高)
重要:勾选“创建聚类成员变量”,这是整个聚类的最终结果,要求软件为每一行记录输出对应的类;
3.评估字段。这可为未在聚类创建中使用的变量计算聚类数据。通过在子对话框中选择评估字段,可以在模型查看器中将其与输入特征一起显示。带有缺失值的字段将被忽略。可以不用理。
本案例暂不演示“XML模型导出”(便于模型更新,十分有用);
4.结果解读
模型查看器
“聚类浏览器”包含两个面板,主视图位于左侧,链接或辅助视图位于右侧。
1.有两个主视图:
- 模型摘要(默认视图)
- 分群。
2.有四个链接/辅助视图:
- 预测变量的重要性.
- 聚类大小(默认视图)
- 单元格分布。
- 聚类比较。
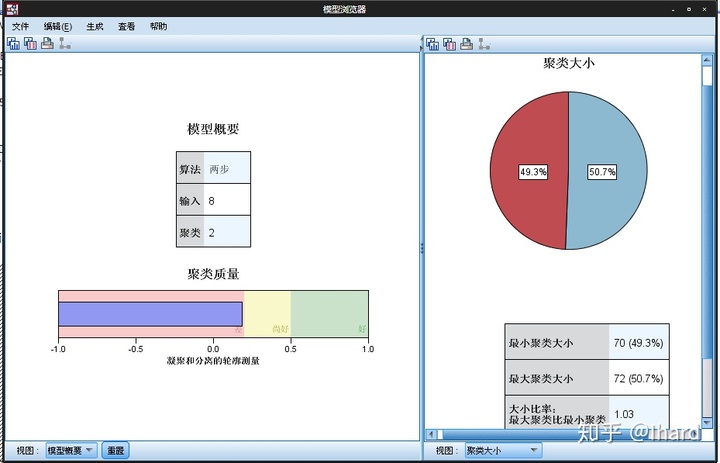
结果查看器中双击“模型摘要图”,打开模型浏览器,这一部分结果高度可视化,读取更直观。模型浏览器分为左右两个板块,左侧为主视图,右侧为辅助视图,主要结果解读如下
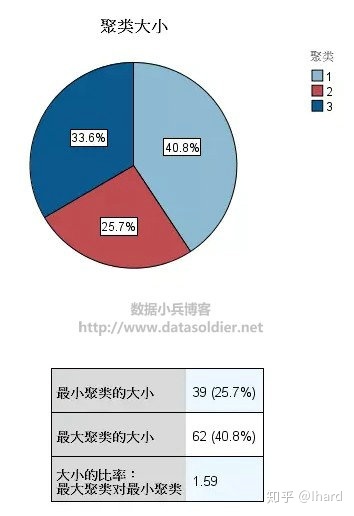
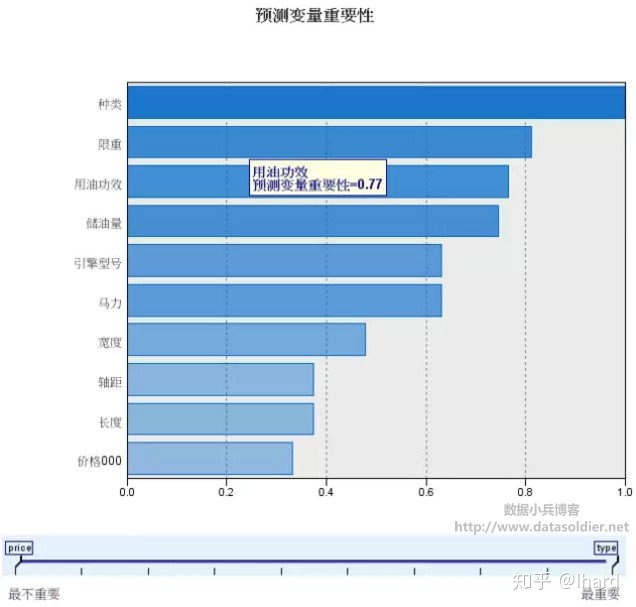
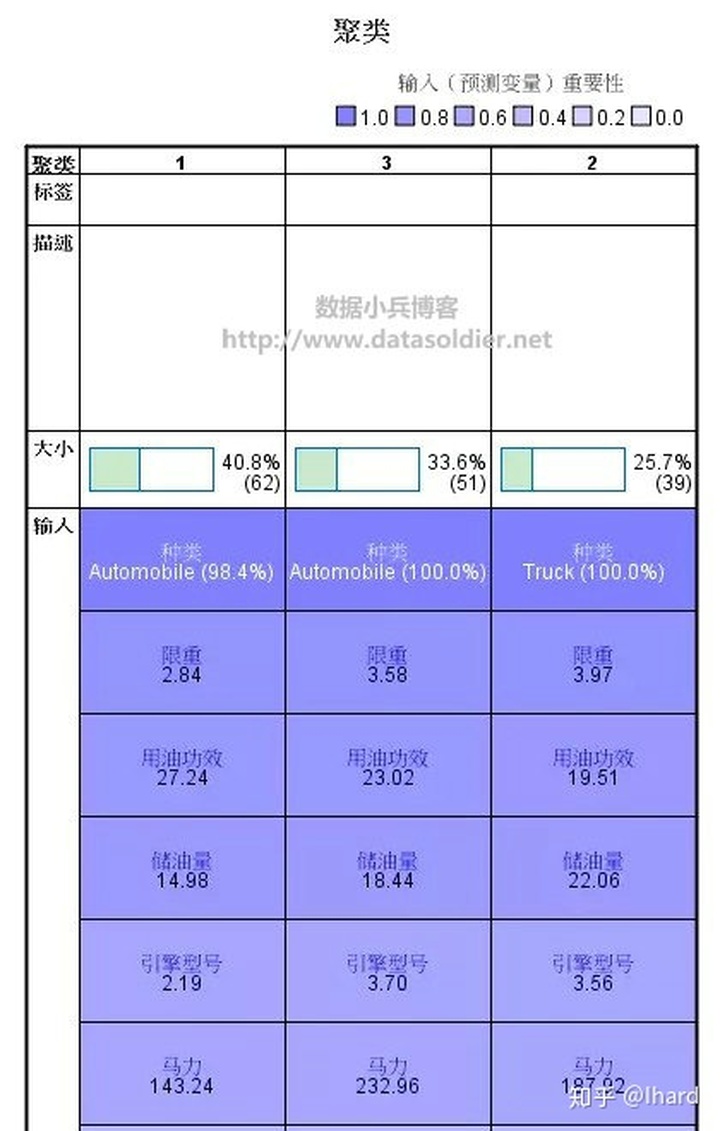
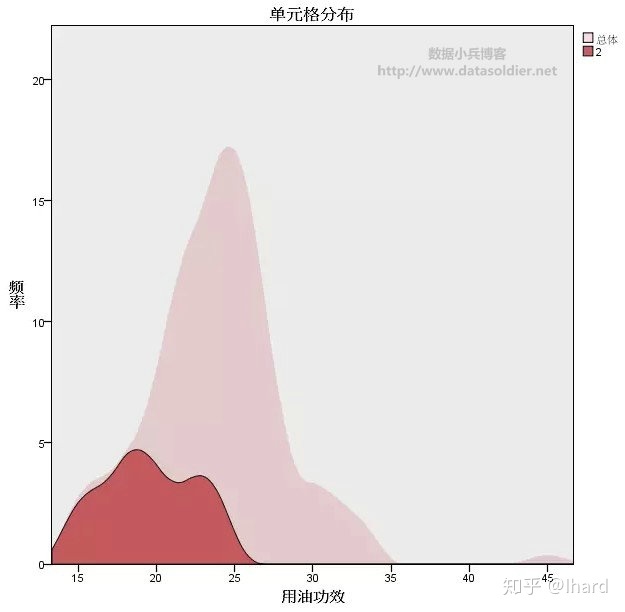
点击其中一个单元格,比如2类的“用油功效”单元格,在右侧软件将会输出辅助视图,如下
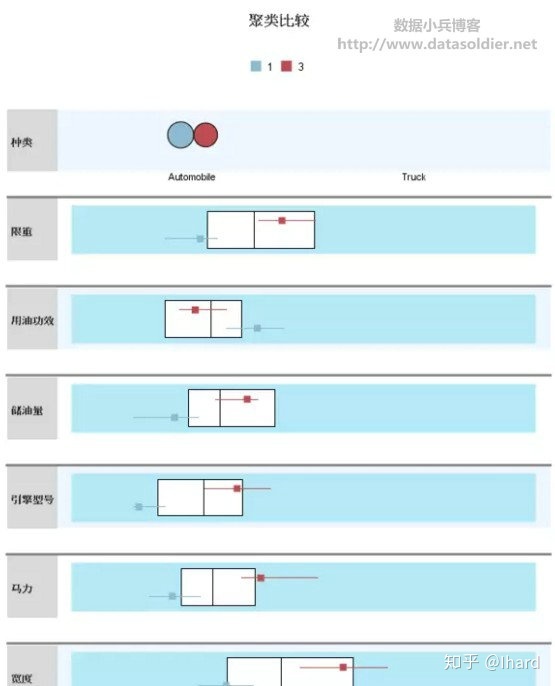
在模型浏览器左侧的主视图中按ctrl键,同时选定两个或以上类,在右侧辅助视图中将出现两个类或以上类的特征对比。
以第1类和第3类为例,两类在价格方面差异较大,第3类价格偏高,而第1类价格较低;车的长度上,第3类同样较长,此外还可以看到,第3类车型在轴距、宽度、马力、储油量、限重等方面较第1类都高很多。
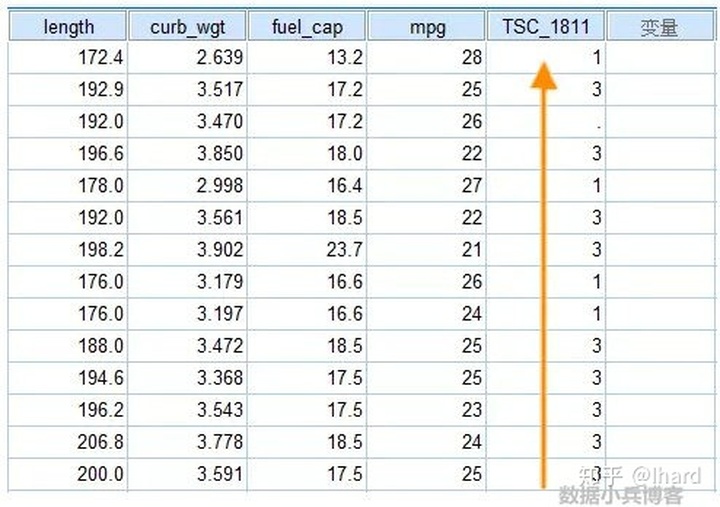
聚类之后,我们有必要就每一个记录对应的类有所了解,类成员变量(最终的聚类结果)非常重要,便于日后深入比对和分析。软件将其自动保存在数据视图最后一列,新生成变量“TSC_n”,其中TSC即表示二阶聚类,n是一个正整数,表示本次过程执行的内部运行顺序。
综合以上信息,3类车型可以描述如下:
- 第1类:价格便宜,体积、限重和马力较小,属于低端车型;
- 第2类:价格适中,体积、限重和马力较第1类明显提高,油耗低特征突出,属于实用车型;
- 第3类:价格较高,体积、限重和第2类相差较小,但马力在3类车中最高,油耗居中,属于高端车型;
补充:
在SPSS软件提供的三种聚类算法中,二阶聚类最为特殊,一是因为可以同时处理类别变量和连续变量,还有一点极为关键,二阶聚类可以自动确定最终的类的个数,算得上具备自动探索未知领域的能力,这是SPSS层次聚类和K均值聚类无法相比的。
能自动聚类、允许类别变量,再加上善于处理大数据集,二阶聚类的优势十分明显,可以在各行业方便有效的使用,值得推荐。
本文整合网上多名优秀博主(主要数据小兵)和百度资源关于聚类分析的资料,整理出的一份学习笔记,与大家共享