如何构建电子商务网站/免费发帖推广的平台
之前用LDA的方法进行文本聚类,需要指定topic的数量,但是现在如果用HDP的方法,可以自动训练出topic个数。这得益于HDP的构造过程。下面介绍一个比较简单的过程。(构造的过程也就是聚类的过程)
中国餐馆过程
假设有很多个一样的中国餐馆,每个餐馆内有无数张桌子,每张桌子上可以坐无数个人,第一个人进来可以随意选择一张桌子,并点菜;第二个人进来以一定概率选择前者的桌子并与其共享菜,以一定概率选择新桌子,假设他选择了新桌子;第三个人进来以一定概率选择第一个人的桌子,以一定概率选择第二个人的桌子,以一定概率选择新桌子,以此类推……
上面的例子中,一个中国餐馆代表一个document,一张桌子就代表一个类别,第一个人点的菜,就代表他为这个类选择的parameter,其他人再选择这个类别,就与第一个人共享这个类别的参数。这样当所有顾客都落座后,类别的个数也就确定了。
它的实际过程是:(为了方便表示,数组从1开始)
def Chinese_Restaurant_Process(num_of_customers, alpha):table_assignments[1] = table[1] #the first customer sits on the first tablenext_open_table = 1 #index of the next empty tablefor i in num_of_customers:if rand < alpha / (alpha + i)#customer sits at a new tabletable_assignments[i] = next_open_tablenext_open_table += 1else# Customer sits at an existing table.# He chooses which table to sit at by giving equal weight to eachtable_assighments[i] = table_assignments[rand(table_assiments.size)]return table_assiments实际上,顾客被分到已有桌子的概率并不是一样的。
设,目前已经落座的总人数为 ,第 张桌子上的人数记为
,第
个顾客被分到:
existing桌子的概率是: 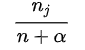
new桌子的概率是: ![]()
所以从上式也可以看出:
- 决定了聚类的密度,当
越大时,聚类越稀疏,有越多的类别,而且类别中的单词会很少;反之,聚类越密集,类别越少,类别中的单词更密集。
- 类别中的单词数越多,下一个单词被分到该类别的概率越大。
一个customer就代表document中的一个word。这样到最后,每篇document中的word都会被分类。