一、map数据类型
1.1 声明和定义
map类型是一个key-value的数据结构,又叫字典。(map也是可以扩容的,内部自动扩容)
声明:
var map1 map[keytype]valuetype
例子:
//var a map[key的类型]value类型 var a map[string]int var b map[int]string var c map[float32]string
注意:
1.声明是不会分配内存的,需要make初始化。
2.map必须初始化才能使用,否则panic。
3.map中声明value是什么类型,就存什么类型,混合类型自身不支持(Go是强类型语言),interfice支持存混合类型数据。
map类型的变量默认初始化为nil,所以需要使用make分配map内存,然后才能使用,不然会panic(异常)。
实例如下:
实例1-1
package mainimport ("fmt" )func main() {var a map[string]intif a == nil { //map未初始化,其初始默认为nilfmt.Println("map is nil. Going to make one.")a = make(map[string]int)} }
执行结果如下:

另外也验证一下不初始化跑出panic
实例如下:
实例1-2
package mainimport ("fmt" )func main() {var user map[string]intuser["abc"] = 38fmt.Println(user) }
执行结果如下:
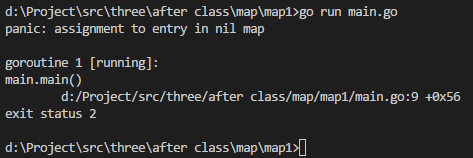
已经抛出了panic,所以必须要初始化。
1.2 插入操作
代码示例如下:
实例1-3
package mainimport ("fmt" )func main() {a := make(map[string]int)a["steve"] = 12000a["jamie"] = 15000a["mike"] = 9000fmt.Println("a map contents:", a) }
执行结果如下:

1.3 初始化
第一种:make
实例1-4
package mainimport ("fmt" )func main() {var user map[string]int = make(map[string]int, 5000) //初始化时可以指定容量也可以不指定,指定的话可以提升性能//user := make(map[string]int) //也可以写成这样,多种方式user["abc"] = 38fmt.Println(user) }
执行结果如下:

第二种:声明时进行初始化(借助常量)
实例1-5
package mainimport ("fmt" )func main() {a := map[string]int{"steve": 12000,"jamie": 15000,}a["mike"] = 9000fmt.Println("a map contents:", a) }
执行结果如下:

1.4 map扩容
map扩容实际上类似切片扩容就是:
map本来的容量是4,现在容量不够了,map内部自动扩容,比如说扩容到8,其在底层的机制就是将旧的内存地址中的4个元素拷贝到新到容量为8的内存地址中,然后再继续接收新元素并使用。
所以说:在初始化时,如果我们知道map大概有多少元素时,可以初始化时指定,这样可以在一定程度上提升性能(频繁扩容影响性能)
1.5如何访问map中元素?
通过key访问map中的元素
实例1-6
package mainimport "fmt"func main() {a := map[string]int{"steve": 12000,"jamie": 15000,}a["mike"] = 9000b := "jamie"fmt.Println("Salary of", b, "is", a[b]) }
执行结果如下:

1.6 如何判断map指定的key是否存在?
相当于做一个白名单,去判断map中指定key是否存在。
格式:value, ok := map[key]
注意:ok仅仅是个变量,可以随便命名
实例1-7 实例1:
package mainimport ("fmt" )func main() {a := map[string]int{"steve": 12000,"jamie": 15000,}a["mike"] = 9000b := "joe"value, ok := a[b] //ok仅仅是个变量,可以随便命名if ok == true {fmt.Println("Salary of", b, "is", value)} else {fmt.Println(b, "not found")} }
执行结果如下:

实例1-8 实例2 (用户白名单基础版)
package mainimport ("fmt" )var whiteUser map[int]bool = map[int]bool{32323: true,32011: true,10222: true, }func isWhiteUser(userId int) bool {_, ok := whiteUser[userId] //这里不需要返回value,所以直接_忽略 return ok }func main() {userId := 100021if isWhiteUser(userId) {fmt.Printf("is white user:%v\n", userId)} else {fmt.Printf("is normal user:%v\n", userId)} }
执行结果如下:

1.7 map遍历操作
其实就是用for range
range返回key value并赋值给变量,结合数组、切片遍历也是for range,其实数组及切片就是个特殊map。
代码示例如下:
实例1-9
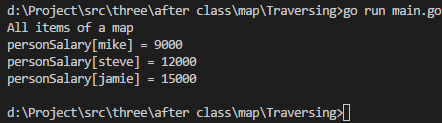
package mainimport ("fmt" )func main() {a := map[string]int{"steve": 12000,"jamie": 15000,}a["mike"] = 9000fmt.Println("All items of a map")for key, value := range a {fmt.Printf("personSalary[%s] = %d\n", key, value)} }
执行结果如下:
1.8 map删除元素
借助一个delete内置函数,delete指定map的key即可删除
代码示例如下:
实例1-10
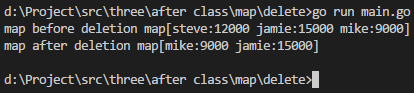
package mainimport ("fmt" )func main() {a := map[string]int{"steve": 12000,"jamie": 15000,}a["mike"] = 9000fmt.Println("map before deletion", a)delete(a, "steve")fmt.Println("map after deletion", a) }
执行结果如下:
1.9 map的长度
借助len函数
实例1-11
package mainimport ("fmt" )func main() {a := map[string]int{"steve": 12000,"jamie": 15000,}a["mike"] = 9000fmt.Println("length is", len(a)) }
执行结果如下:

1.10 map是引用类型
通过下面这个例子验证map是引用类型
实例1-12
package mainimport ("fmt" )func main() {a := map[string]int{"steve": 12000,"jamie": 15000,}a["mike"] = 9000fmt.Println("origin map", a)b := ab["mike"] = 18000fmt.Println("a map changed", a) }
执行结果如下:
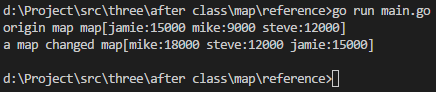
解释:
可以发现a为map,将a赋值给b,b也是map,map b做了修改,此时打印a,map a也发生了变化,这证明map是引用类型
1.11 map排序
默认情况下, map并不是按照key有序进行遍历的。
千万不要依赖map中的顺序,map是无序的(go1.6之前好像是有序的)
可见如下实例:
实例1-13
package mainimport ("fmt" )func main() {var a map[string]int = make(map[string]int, 10)for i := 0; i < 10; i++ {key := fmt.Sprintf("key%d", i)a[key] = i}for key, value := range a { fmt.Printf("key:%s = %d\n", key, value)} }
执行结果如下:
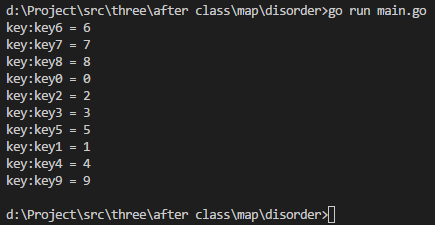
但是如何map如何按照key进行排序?
思路:先把key排序,然后再按照排序后的key去遍历map
代码示例如下:
实例1-14
package mainimport ("fmt""sort" )func main() {var a map[string]int = make(map[string]int, 10)for i := 0; i < 10; i++ {key := fmt.Sprintf("key%d", i)a[key] = i}var keys []string //将无序的map的key放入到切片中for key, _ := range a {keys = append(keys, key)}sort.Strings(keys) //借助sort进行排序for _, key := range keys { //将切片进行遍历fmt.Printf("key:%s=%d\n", key, a[key])} }
执行结果如下:
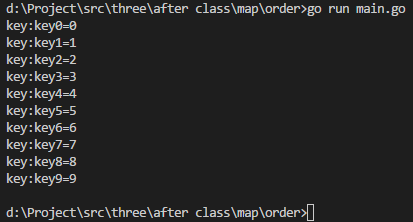
1.12 map类型切片
首先需要先将切片初始化,切片中的每一个元素又是一个map,所以要使用map时,又需要对每一个元素进行一次初始化(引用类型)
实例1-15 实例1
package mainimport ("fmt" )func mapSlince() {}func main() {var s []map[string]int //s是一个map类型的切片s = make([]map[string]int, 5) //切片初始化for k, v := range s {fmt.Printf("index:%d val:%v\n", k, v)}s[0] = make(map[string]int, 16) //map初始化s[0]["abc"] = 100for key, val := range s[0] {fmt.Printf("key:%s value:%v\n", key, val)} }
执行结果如下:
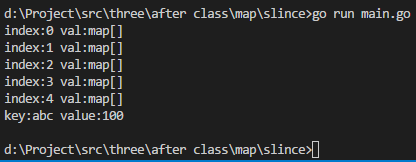
实例1-16 实例2
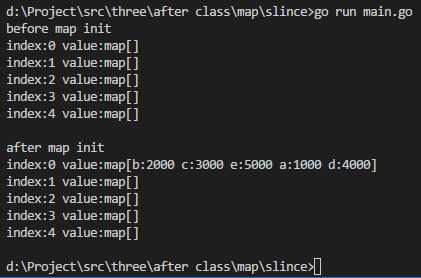
package mainimport ("fmt" )func main() {var mapSlice []map[string]intmapSlice = make([]map[string]int, 5) //此时是一个未初始化的map类型切片,所以需要先将切片初始化fmt.Println("before map init")for index, value := range mapSlice {fmt.Printf("index:%d value:%v\n", index, value)}fmt.Println()mapSlice[0] = make(map[string]int, 10) //要使用map,需要将map进行初始化。mapSlice[0]["a"] = 1000mapSlice[0]["b"] = 2000mapSlice[0]["c"] = 3000mapSlice[0]["d"] = 4000mapSlice[0]["e"] = 5000fmt.Println("after map init")for index, value := range mapSlice {fmt.Printf("index:%d value:%v\n", index, value)} }
执行结果如下: