2019独角兽企业重金招聘Python工程师标准>>> 
date: 2014-08-29 17:09
1.汇编指令格式
在windows领域386汇编都以intel定义的指令格式来编写,而在unix领域,采用的却是AT&T格式。先来看看这两种格式的简要区别。
-
AT&T格式中,寄存器名前要加“%”前缀;而在Iintel格式中则不带前缀
AT&T push %eax Intel push eax -
AT&T格式中,立即数要加“$”前缀,Intel格式中立即数不要加前缀
AT&T push $100 Intel push 100 -
AT&T格式中,指令的源操作在前,目的操作数在后;Intel格式刚好相反
;eax = eax + ebx AT&T add %ebx, %eax Intel add eax, ebx -
AT&T格式中,访存指令中操作数的宽度由指令的后缀表示,后缀“b”,“w”,“l”分别表示操作数为字节(byte, 8bits),字(word, 16bits)和长字(long, 32bits);而在Intel格式中,则在表示内存单元的操作数前加上“byte ptr”、“word ptr”、“dword ptr ”来表示。
;从addr所代表的内存中取出一个字节给al AT&T movb addr, %al Intel mov al, byte ptr addr -
AT&T格式中,跳转和调用指令jmp/call,其目的地址之前要加上“*”号前缀,而intel格式则不带。 以寄存器esi中的内容作为目的地址跳转
AT&T jmp *%esi Intel jmp esi -
远程跳转指令和调用指令,在AT&T格式中为ljmp和lcall;而在intel格式中为jmp far和call far。
;section和offset为立即数 AT&T ljmp $section, $offsetlcall $section $offsetlret Intel jmp far section:offsetcall far section:offsetret far -
内存间接寻址
;以寄存器esi中的内容作为目的地址跳转 AT&T section:disp(base, index, scale) Intel section:[base+index*scale+disp]
这种寻址方式常用于在结构体数组中访问特定元素中的一个字段,base为结构体数组的基址,scale为结构体的sizeof大小,index为元素的索引,disp为具体字段相对结构体的偏移。如下图: 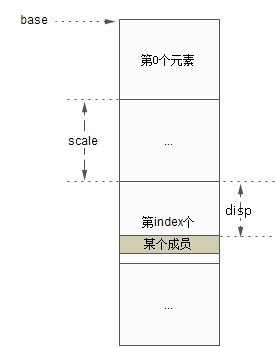
内核工作在保护模式下,使用Flat(平面)地址,段的基地设置为0(第2章有介绍),故在计算地址时可以不考虑段基址,内存地址的计算采用如下公式:
地址 = base + index*scale+disp。
下面是一些间接寻址的例子:
| AT&T | intel | AT&T指令说明 |
|---|---|---|
| -4(%ebp) | [ebp – 4] | 括号中只有base这一项,可以省略逗号 |
| foo(, %eax, 4) | [eax * 4 + foo] | 省略base,逗号不能省略 |
| offset(%ebx, %eax, 4) | [ebx + eax * 4 + offset] |
2 嵌入式汇编代码块的组成
这部分大多数内容抄书自《情景分析》,但“伪寄存器”是我自己的想法。
一般而言,在C中嵌入汇编比纯粹的汇编要复杂很多。看看如下代码。
<arch/x86/include/asm/atomic.h>41 /**42 * atomic_add - add integer to atomic variable43 * @i: integer value to add44 * @v: pointer of type atomic_t45 *46 * Atomically adds @i to @v.47 */48 static inline void atomic_add(int i, atomic_t *v)49 {50 asm volatile(LOCK_PREFIX "addl %1,%0"51 : "+m" (v->counter)52 : "ir" (i));53 }
嵌入到C中的汇编代码包含如下四个组成部分,各部分以冒号(“:”)分割,注意不要与代码中label后的冒号相混淆:
指令部:输出部:输入部:损坏部
第一部分是指令部,就是汇编代码本身,这部分是必须有的,而其他部分则可视情况省略。省略其他部分时,相应的冒号分隔符是否省略有下面两种情况:
如果该部之后的其余部都省略了,则该部之后的冒号分隔符可以省略。比如汇编代码只有指令部,则后面的部包括指令部后面的冒号都可以省略
如果该部之前有省略的部,则与之相分隔的冒号不能省,比如汇编代码只有指令部和损坏部,则格式如下:
指令部:::损坏部
将汇编代码嵌入到C语言中,读者应该能想到如下两个难题:
- C代码编译后也变成了汇编码,也会操作通用寄存器,那我们我们在写汇编代码时,用哪些寄存器才不会导致冲突呢?
- 汇编代码中操作数与C中变量结合的问题。编译器在编译C代码时,会将C中的变量放到寄存器或者栈中,我们写的汇编代码中如何引用这些变量呢,我们怎么能知道这些变量存在哪里?
解决这两个难题,要么编代码的人把难题全部推给编译器,让编译器去搞定;要么编译器把难题推给编代码的人,让代码的作者来搞定。可以想象,推给谁都是一项艰巨的任务。最后代码编写者与编译器各退一步,达成一个折中的方案:程序员只编写具体的指令,对寄存器的使用不再“指名道姓”地指定某个具体寄存器,而是通过“伪寄存器”这种中间量来引用,同时给这些“伪寄存器”加上约束条件,指定与C中的哪些变量结合。而具体使用哪个通用寄存器,则交给编译器和连接器来处理。
在指令部,数字加上前缀%,则表示使用哪个伪寄存器,如%0、%1表示使用伪寄存器R0、R1。而具体有多少个伪寄存器取决于CPU中通用寄存器的数量。为了与具体的寄存器区分,指令部中涉及到的具体的寄存器前加两个%号,如%%eax就是指eax寄存器。
那么怎样表达对变量结合的约束条件呢?这就是其余几个部分的作用。
输出部规定对输出部即目标操作上如何结合的约束条件。必要时输出部可以有多个约束,相互以“,”分割。每个约束以“=”或者“+”开始,后跟一个字母表示对操作数类型的说明,然后是与之结合的C中变量。如上面的代码中,输出部只有一个约束条件:
: "+m" (v->counter)
其中“+”号表示输出变量是可读可写的,m表示与输出操作数(指令部中的%0)结合的为存储于内存单元中的v->counter。
凡是分配给输出部的寄存器,在执行汇编代码之前均不备份寄存器之前的内容(当然执行完汇编码以后也不会恢复之前的内容),这就是代码编写者给编译器提供的信息,给GCC调度使用寄存器提供了依据。 输出部后面是输入部,输入部的约束条件与输出部一致,但不带前导的“=”或“+”号。上面的例子中输入部只有一个约束条件:
: "ir" (i)
表示输入操作数(指令部中的%1)可以是一个立即操作数(i表示immediate),来自C中的变量i。如果输入约束要求使用寄存器,则在gcc的预编译过程中,gcc会为之分配一个寄存器,并插入指令来将操作数即变量装入寄存器。同输出部一样,与输入部结合的寄存器,在执行汇编代码之前也不备份寄存器之前的内容。例如这里的输入约束要求使用寄存器,则在预编译时,gcc为之分配一个寄存器,并用mov指令将变量i装入该寄存器,如果该寄存器之前是空闲的,这没什么问题,可如果寄存器正在使用,则之前的内容被冲掉了。为了应对这种情况,gcc在将变量装入寄存器之前使用push指令将寄存器的内容入栈,汇编代码结束后,使用pop指令从栈中恢复寄存器之前的内容。
在有些操作中,除了用于输入操作数和输出操作数的寄存器外,还需要 将若干个寄存器用来暂存操作或计算的中间结果,这样这些寄存器之前的内容就被损坏了,所以要在损坏部对“副作用”加以说明,让gcc采取相应的措施,这就是损坏部的作用。在损坏部,常常会以“memory”为约束条件,比如gcc的barrier函数:
<include/linux/compiler-gcc.h>
13 /* Optimization barrier */
14 /* The "volatile" is due to gcc bugs */
15 #define barrier() __asm__ __volatile__("": : :"memory")
损坏部中的“memory”表示操作完成后,内存中的内容以及改变,如果某个寄存器的内容来自内存,则现在内容可能不一致了。
表示约束条件的字母主要有:
| 约束字符 | 含义 |
|---|---|
| m/v/o | 表示内存单元 |
| r | 表示任何寄存器 |
| q | 表示寄存器eax、ebx、ecx、edx之一 |
| i/h | 立即操作数 |
| E/F | 浮点操作数 |
| g | 表示任意 |
| a/b/c/d | 分别表示要求使用寄存器eax/ebx/ecx/edx |
| S/D | 分别表示要求使用寄存器esi/edi |
| I | 表示立即数(0 - 31) |
伪寄存器的编号从输出部的第一个约束(编号为0)算起,标号依次加1。指令部中引用这些伪寄存器时就在序号前加%号。如果某个操作数要求使用与前面某个约束相同的寄存器,那就在该操作数的约束条件中写上之前那个约束对应的伪寄存器编号。
3 三步法解析嵌入式汇编
下面我们用三步法来分析上面那个例子。
-
第一步,以伪寄存器代替伪寄存器编号,则得到如下代码:
LOCK_PREFIX "addl R1,R0" -
第二步,分析约束条件,确定伪寄存器来源。在上面的例子中:
伪寄存器 来源 x86寄存器 R0 来自C中的变量v->counter 未指定寄存器,假定为eax R1 来自C中的变量i 未指定寄存器,假定为ebx -
第三步,结合约束条件给x86寄存器赋值,并用X86寄存器代替伪寄存器,得到的伪代码如下:
;结合约束条件初始化寄存器(v->counter) --> eaxi --> ebx;指令部LOCK_PREFIX "addl ebx, eax"
注意,为了便于解析嵌入汇编代码,这里使用了伪代码并“人为”的指定了寄存器,实际编译后的代码可定与此不同,请大家不要混淆了。
由于AT&T格式源操作数在前目的操作数在后,所以这段代码的作用就是将i的值加到v->counter。addl指令的后缀l(long)表示这是一个32位的加法指令。与此类似,h表示半字即16位,b表示字节。addl指令前的LOCK_PREFIX,表示执行该加法指令时要锁住系统总线,不让别的cpu来打扰,从而实现“原子操作”。读者也许要问,不就是将i的值加到v->counter,一句C代码”v->counter += i;”就搞定了,为什么要用嵌入式汇编呢?原因就是这里要求整个操作由一条指令完成,并且要将总线锁住以保证操作的原子性,而C代码编译后有多少条指令是不确定的,在C代码中也无法要求对总线加锁。
再看一个复杂点的例子,来自string_32.h,大家想必用过c中的memcpy,这是内核中的实现,提供raw数据的拷贝。
<arch/x86/include/asm/string_32.h>32 static __always_inline void *__memcpy(void *to, const void *from, size_t n)33 {34 int d0, d1, d2;35 asm volatile("rep ; movsl\n\t"36 "movl %4,%%ecx\n\t"37 "andl $3,%%ecx\n\t"38 "jz 1f\n\t"39 "rep ; movsb\n\t"40 "1:"41 : "=&c" (d0), "=&D" (d1), "=&S" (d2)42 : "0" (n / 4), "g" (n), "1" ((long)to), "2" ((long)from)43 : "memory");44 return to;45 }
用三步法分析下:
-
第一步,指令部预处理:用伪寄存器代替伪寄存器编号,并用排版处理掉指令部中的换行(\n)以及tab(\t)符,并过滤掉其他符号,指令部如下:
rep movslmovl R4,ecxandl $3,ecxjz 1frep movsb 1: -
第二步,约束条件解析
约束 伪寄存器 来源 x86寄存器 "=&c" (d0) R0 来自C中的变量d0 要求使用ecx "=&D" (d1) R1 来自C中的变量d1 要求使用EDI "=&S" (d2) R2 来自C中的变量d2 要求使用ESI "0" (n / 4) R3 来自C中变量n除以4 要求与约束0使用同一个寄存器,即使用ecx "g" (n) R4 来自C中的变量n 使用任意的寄存器 "1" ((long)to) R5 to 要求与约束1使用同一个寄存器,即使用EDI "2" ((long)from) R6 from 要求与约束2使用同一个寄存器,即使用ESI -
第三步,根据约束条件插入预处理伪代码,并用x86寄存器替换伪寄存器
;预处理n / 4 --> ecxn --> 任意寄存器,这里仍然用R4指代to --> edifrom --> esi;汇编指令rep movsl ;从esi所代表的地址处复制一个长字(32bit)到edi所代表的地址处,重复执行,;每次执行后,ecx减一,esi和edi分别加4,直至ecx减为0。考虑到ecx的初始;值为n/4,这条指令是把所有的长字都复制到edi处,该指令结束后,所有长字;复制完毕,最多只剩3个字节。movl R4,ecx ;R4中存放的是n,这里将n赋给ecxandl $3,ecx ;n与立即数3做按位与操作,即取得n除以4的余数或者叫做模jz lf ;如果按位与的结果为0,则前跳到标号为1处,1后面的f表示forwardrep movsb ;如果按位与的结果不为0,则继续按字节(8bit复制,将剩余的内容复制到edi处 1: ;lable 1的内容为空,表示结束
可见拷贝的动作分两部分,先拷贝长字部分,拷贝的动作时按32位进行,再将“零头”按字节拷贝,拷贝的动作按8为进行。rep命令要求以ecx作为循环计数器,而movs指令要求以esi作为源,edi作为目的,这就是约束条件中要求使用ecx、esi、edi的原因。
为了熟练运用三步法,我们再看一个更复杂的例子:
<arch/x86/lib/string_32.c>
117 int strncmp(const char *cs, const char *ct, size_t count)
118 {
119 int res;
120 int d0, d1, d2;
121 asm volatile("1:\tdecl %3\n\t"
122 "js 2f\n\t"
123 "lodsb\n\t"
124 "scasb\n\t"
125 "jne 3f\n\t"
126 "testb %%al,%%al\n\t"
127 "jne 1b\n"
128 "2:\txorl %%eax,%%eax\n\t"
129 "jmp 4f\n"
130 "3:\tsbbl %%eax,%%eax\n\t"
131 "orb $1,%%al\n"
132 "4:"
133 : "=a" (res), "=&S" (d0), "=&D" (d1), "=&c" (d2)
134 : "1" (cs), "2" (ct), "3" (count)
135 : "memory");
136 return res;
137 }
-
第一步指令部预处理后如下:
1: decl R3js 2flodsbscasbjne 3ftestb al,aljne 1b 2: xorl eax, eaxjmp 4f 3: sbbl eax, eaxorb $1,al 4: -
第二步解析约束条件如下:
约束 伪寄存器 来源 x86寄存器 "=a" (res) R0 res 要求使用eax "=&S" (d0) R1 d0 要求使用esi "=&D" (d1) R2 d1 要求使用edi "=&c" (d2) R3 d2 要求使用ecx "1" (cs) R4 函数参数cs 要求与约束1使用同一个寄存器,即使用esi "2" (ct) R5 函数参数ct 要求与约束2使用同一个寄存器,即使用edi "3" (count) R6 函数参数count 要求与约束3使用同一个寄存器,即使用ecx -
第三步,根据约束条件插入预处理伪代码,并用x86寄存器替换伪寄存器,如下:
;预处理,寄存器装载初值count --> ecxcs --> esict --> edi1: decl ecx ;ecx减1js 2f ;如果ecx - 1 小于0,则前跳到标号1处。由于ecx赋值为入参count,所以这里对;count进行;减一操作,之后判断count是否<0,小于0,则表示比较结束,没有发现;不相同的字符,所以字符串相等lodsb ;从esi代表的地址处加载一个字节(8bit)到al,然后esi加1,由于esi指向cs,这里;是从入参cs指向的地址处取一个字节scasb ;计算al - [edi],然后edi加1,由于edi指向入参ct,而al指向入参cs中的某个字;符,;所以这里计算两个字符串同一位置的字符是否相同jne 3f ;如果两个字符不等,则说明两个字符串至此已经不相同了,前跳到标号3处testb al,al ;测试al是否为0,如果是0的话,表示遇到null,两个字符串都结束了,说明两个字;符串相等,则从标号2处开始执行jne 1b ;如果不为null,则回调到标号1处,继续进行比较,1后面的b表示backward,往回跳 2: xorl eax, eax ;注意,只有当比较字符串相等时,才会跳至此处。对eax进行异或操作,使得eax为0。;注意,eax是与输出部的第一个约束结合的寄存器,与之结合的c变量为函数返回值;res,所以,这里设置函数的返回值为0jmp 4f ;前跳到标号4处 3: sbbl eax, eax ;带借位的减法,注意只有当两个字符串同一位置的字符不相等时,才会跳至此处。;如果scasb的结果小于0,那么这里的结果为-1,否则,这里的结果为0orb $1,al ;al与立即数1执行按位或操作,如果上条指令的结果为-1,即eax=0xFFFFFFF,则这;条指令对eax值没有影响,如果上条指令的结果为0,则这条指令之后eax中的值为1。;经过这操作,确定了当比较结果不相等是的返回值,如果cs中字符>ct中的字符,则;返回1,否则返回-1 4: ;空语句,至此,执行结束可见函数对cs与ct中的字符依次比较,如果遇到第i个字符cs[i]与ct[i]不同,则两个比较结果为不相等,当cs[i]>ct[i]时,返回1,否则返回-1。如果比较完前count个字符都没发现不同的字符,或者两个字符串同时遇到了null字符,则比较结果为相等,返回0.