十堰的网站建设/网络推广专员是干什么的
接下来将会有系列博客介绍GAN网络。
生成模型与判别模型
首先,需要搞清楚什么是生成模型,什么是判别模型。
生成模型是指模型学习得到 给定数据集 上的一个联合分布。这里的随机变量是模型中所有可能的随机变量。举个例子来说,对于28x28的图片来说,生成模型会学习到28x28个像素组成的随机变量的联合分布。对于带标签的28x28的图片来说,生成模型会学习到28x28+1 个随机变量的联合分布。后续的推断过程都是基于这个联合分布来完成的,典型的生成模型有 受限玻尔兹曼机、概率图模型。
而判别模型则是指模型学习得到 给定数据集 上的一个条件分布。拿带标签的28x28的图片来说,判别模型会学习到 给定28x28个像素点的条件下10个标签的条件概率。这种模型一般是带着标注数据的。
GAN基本原理
GAN 起源于博弈论中的两人零和博弈,零和博弈是指博弈的双方必须分出胜负,不可以出现和棋平局的局面。在GAN的第一篇论文中,作者拿了假币制造和识别的博弈过程来介绍GAN的思想。
有一个假币制造团队,他们是生成模型,他们的任务是生成越来越多的让警察无法识别出来的假币已达到以假乱真的目的。
还有一个是警察团队,他们是判别模型,他们的任务是给定一张纸币能够分辨出来这张纸币是真的还是假的。换句话说,他们会给一张纸币打分,如果这张纸币出自假币制造团队之手,那么这个分就低。如果这张纸币是出自中央银行,那么这个分就给的高。满分是100分。
他们双方之间的竞争使得两个团队不断改进他们的方法直到警察再也分辨不出来假币和真币。这个时候,再给警察一张假币团结制造的纸币,他已经无法区分这张纸币到底是真的,还是假的,于是给了一个50分,表示他们分不出来。

GAN模型

GAN由两部分组成:生成模型、判别模型
生成模型
生成模型用于捕捉样本数据的分布,用服从某一分布的随机噪声zzz作为输入生成一个类似真实训练数据的样本。
- pz(z)p_z(z)pz(z) 表示输入噪声zzz的分布函数
- pg(x)p_g(x)pg(x) 表示生成模型学习到的,潜在的 样本xxx的分布,注意GAN不会给出一个显式的概率分布来表示pg(x)p_g(x)pg(x)是多少,它是通过给定噪声zzz 生成得到的假样本xxx 来体现的。显然,pg(x)p_g(x)pg(x) 值越大 通过噪声zzz 生成相应的xxx 就越可能。
- G(z,θg)G(z,\theta_g)G(z,θg) 表示生成模型,生成模型可以是MLP,也可是CNN,RNN等等。
判别模型
判别模型是一个二分类器,用于评价一个样本来自真实数据集的概率(其实这种说法是有些欠妥的,我们后面再讲)。
- D(x;θd)D(x;\theta_d)D(x;θd) 表示判别模型
- D(x)D(x)D(x) 表示样本xxx来自真实数据而不生成数据的概率。
目标函数
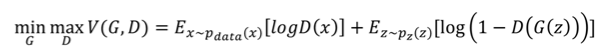
符号解释:
- zzz :生成模型输入的噪声。
- G(z)G(z)G(z):输入噪声,产生一个样本。即x^=G(z)\hat x=G(z)x^=G(z),xxx 可以是一个点,一个向量,一个矩阵,或者一张图片。xxx的含义随着数据集的变化而变化。可以认为x^∼pg(x)\hat x \sim p_g(x)x^∼pg(x)
- D(x)D(x)D(x) : 判别器,输入样本xxx,判断它是否来自真实数据集。
- pdata(x)p_{data}(x)pdata(x): 数据集的真实联合分布,这是我们想到去学习得到的,但是这个东西只有天知道到底是个啥。
- pz(z)p_z(z)pz(z) :噪声zzz的分布
- pg(x)p_g(x)pg(x): 生成器潜在学习到的样本的分布,生成器的目标就是让pg(x)p_g(x)pg(x)无限的接近真实分布 pdata(x)p_{data}(x)pdata(x)
D表示判别器,G表示生成器。
训练GAN模型的时候,判别模型希望目标函数越大越好。为什么呢?因为它希望logD(x)logD(x)logD(x)大,而log(D(x^))log(D(\hat x))log(D(x^))小,x^\hat xx^是G生成的假样本。于是它也就希望log(1−D(G(z))log(1- D(G(z))log(1−D(G(z)) 也大。
而对于生成模型来说,它想让目标函数越小越好。因为它追求 log(D(x^))log( D(\hat x))log(D(x^))越大越好,log(1−D(x^))log(1-D(\hat x))log(1−D(x^))越小越好,同时 log(D(x))log(D(x))log(D(x)) 越小越好。于是反映到目标函数就是前后两部分越小越好。
实际操作中,生成模型的目标函数是maxmaxmax Ez∼pz(z)[log(D(G(z))]E_{z\sim p_z(z)}[log(D(G(z))]Ez∼pz(z)[log(D(G(z))],因为一般生成模型不要去干扰log(D(x))log( D(x) )log(D(x))。
GAN训练
GAN的训练过程是个交替进行的过程,训练过程中先固定其中一方最优化另外一方,然后再固定另外一方来最优化自己。交替训练的过程中,两个模型会不断的优化,直到最后双方达到一个平衡。

GAN论文给出的训练方法如上。
其中超参数K表示 在训练G之前,先训练K轮的D。
先训练D,对于D的每一次训练:
- 首先先根据pz(z)p_z(z)pz(z) 采集m 个噪声点。
- 从训练数据集随机采集m个样本。
- 根据采样的噪声,生成m个假的样本 x^\hat xx^ ,然后固定住生成模型的所有参数。
- 把采集的训练集样本和生成的假样本同时输入到判别器网络里面,对判别器进行反向传播。
然后再固定D的所有参数,训练G。
- 首先采集m个噪声
- 通过噪声,生成样本,然后优化G的目标函数,更新参数。
此时生成模型的数据分布无限接近训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来真实数据和生成数据,准确率为 50%。
GAN的使用
为了可以生成一些新的样本,只需先生成噪声zzz,然后输入到生成器中进行前向传播,获取生成器的输出G(z)G(z)G(z) 就可以啦~~~~~~
下篇博客将用GAN生成一个圆周上的点。
参考文献
Generative Adversarial Nets
http://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf