济南做网站公司/北京seo排名厂家


十多年前,一个还在做量化交易研究的美国人Wes McKinney开始写下了第一行pandas代码。慢慢地,pandas成为了众多Python程序员做数据分析的首选工具:
它足够快,支持读写各种常用数据格式,语法灵活,又有丰富的生态。
如果你从事大数据工作,用Python的pandas库时会发现很多惊喜。pandas在数据科学和分析领域扮演越来越重要的角色,尤其是对于从Excel和VBA转向Python的用户。
所以,对于数据科学家,数据分析师,数据工程师,pandas是什么呢?
pandas文档里的对它的介绍是:
快速、灵活、和易于理解的数据结构,以此让处理关系型数据和带有标签的数据时更简单直观。
快速、灵活、简单和直观,这些都是很好的特性。当你构建复杂的数据模型时,不需要再花大量的开发时间在等待数据处理的任务上了。这样可以将更多的精力集中去理解数据。
今天我们将通过一个实例来学习使用pandas探索数据价值。
如下图所示,这是一份计算机专业同学的成绩单。其中包含30名同学和各科考试成绩,现根据班主任要求,分别统计各同学总成绩与平均成绩,每个科目的平均成绩,并将成绩分类为优、良、中、差4类。
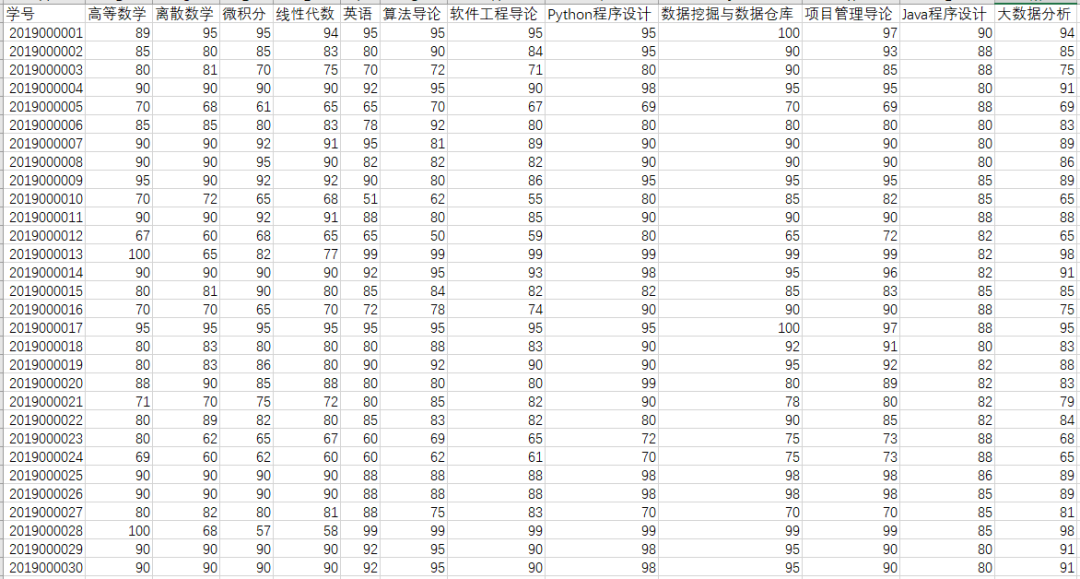
(点击可查看大图)
❶ 实现思路
首先基于成绩表创建数据帧,对数据帧行和列方向上分别进行汇总和求平均。利用scikit-learn机器学习框架中的k-means算法自动分类。
❷ 实现步骤
如以下代码所示,首先读取Excel数据创建数据帧对象。第6行,使用iloc方法选取所有的行,使用“1:13”可取得所有的列,设置参数“axis=1”按行取每一列的数据进行求和运算,最后使用“df["总成绩"]”可以给数据帧添加新列,同理,第7行按类似的方式选取数据求得平均值。在第8行,设置参数“axis=0”,则是按列取每一行的值进行求平均数,使用“df.loc["各科目平均成绩"]”方式给数据帧添加新行,用于放置列平均值。
1. # -*- coding: UTF-8 -*-
2.
3. import pandas as pd
4.
5. sns.set()
6. file = r"成绩明细表.xlsx"
7. df = pd.read_excel(file, sheet_name='成绩表')
8. df["总成绩"] = df.iloc[:, 1:13].apply(lambda x: x.sum(), axis=1)
9. df["平均成绩"] = df.iloc[:, 1:13].apply(lambda x: x.mean(), axis=1)
10. df.loc["各科目平均成绩"] = df.iloc[0:, 1:13].apply(lambda x: x.mean(), axis=0)
11. print(df.fillna(""))
执行结果下图所示。
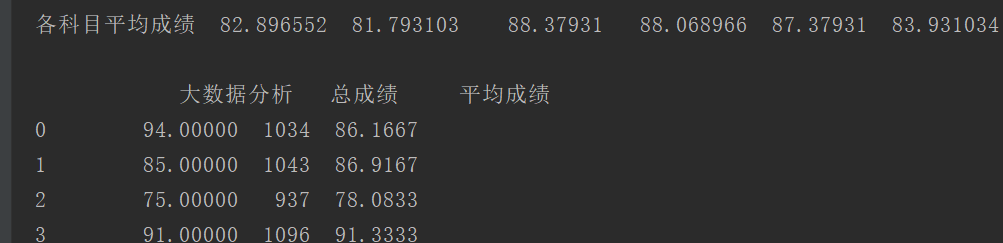
总成绩与平均成绩

各科目平均成绩
接下来使用scikit-learn工具对学生成绩进行分类。
scikit-learn是一个功能强大的机器学习库,实现了大多数数据挖掘算法。这里调用其中的k-means算法实现成绩分类,如以下diamante所示。首先在第4行,导入机器学习库,在第8行计算平均成绩,后续根据平均成绩来对同学进行分类。在第17行,调用cut方法将数据按不同范围划分多个区间,然后给每个区间按参数“labels”进行标记。
1. import pandas as pd
2. import numpy as np
3. # 导入机器学习库
4. from sklearn.cluster import KMeans
5.
6. file = "成绩明细表.xlsx"
7. df = pd.read_excel(file, sheet_name='成绩表')
8. df["平均成绩"] = df.iloc[:, 1:13].apply(lambda x: x.mean(), axis=1)
9.
10. def get_actegory(data, k):
11. means_model = KMeans(n_clusters=k)
12. train_data = data.values.reshape((len(data), 1))
13. means_model.fit(train_data)
14. center = pd.DataFrame(means_model.cluster_centers_).sort_values(0)
15. mean_data = center.rolling(2).mean().iloc[1:]
16. mean_data = [0] + list(mean_data[0]) + [data.max()]
17. data = pd.cut(data, mean_data, labels=["差", "中", "良", "优"])
18. return data
19.
20. result = get_actegory(df["平均成绩"], 4)
21. print(result.value_counts())
执行结果如下图所示,可以看到成绩类别分布情况,每一个类别中有多少个数据。

对于pandas工具的更多用法,大家也可以学习由北京大学出版社出版的《Python数据分析与大数据处理从入门到精通》一书。

---------------------------------------------------------------------
本文内容摘自
北京大学出版社
《Python数据分析与大数据处理从入门到精通》
▼

Python数据分析圣经!
(1)全面:数据分析与大数据处理所需的所有技术,包含基础理论、核心概念、实施流程,从编程语言准备、数据采集与清洗、数据分析与可视化,到大型数据的分布式存储与分布式计算等。
(2)深入:一本书讲透1种编程语言和14种数据分析与大处理工具,以及大数据分析技术及项目开发方法。
(3)丰富:包含45个“新手问答”、17个章节的“实训”、3个项目综合实战、50道Python面试题精选。教你轻松玩转数据分析与大数据处理。
购买地址:
 点击左下文末“
点击左下文末“