网站做系统叫什么软件/seo自动发布外链工具
写操作
写操作是LevelDB着重强调的性能提升点。一般的数据库采用B+树,当在没有随机写的情况下,B+树的性能还是令人满意的。但面对大量随机写时,B+树会分裂,插入的Key值跨度会非常大,导致需要大量磁盘I/O。而LevelDB采用LSM树的思想,将随机写变为顺序写从而提升性能。
LevelDB提供了三个和写操作相关的接口。
- DBImpl::Put: 增加或修改一个KV记录。
- DBImpl::Delete: 删除一条kv记录。
Put和Delete操作完全相同,只是在写入时record的类型不同。Put和Delete对应的Key-Value直接写入即可,后续compaction会进行处理。
默认情况下,为了保证性能,LevelDB采用异步写操作。当LevelDB把写操作提交给数据库后立刻返回,之后异步的将操作应用到数据库中,将其持久化。异步写通常比同步写速度快数百倍以上,但存在当及其宕机时丢失更新数据的问题。同时,LevelDB采用批量写方法,可以减少平均每次写入操作的磁盘开销。
我们从DBImpl的入口函数开始阅读LevelDB写入相关的代码。
http://db_impl.cc
对外接口
LevelDB对外的写操作接口为:
Status DBImpl::Put(const WriteOptions& o, const Slice& key, const Slice& val) {return DB::Put(o, key, val);
}Status DBImpl::Delete(const WriteOptions& options, const Slice& key) {return DB::Delete(options, key);
}
- DBImple中的成员函数直接通过调用父类的成员函数实现。
- WriteOptions为写操作参数,当前只有一个成员变量
sync,表示每次写操作是否需要立刻将数据同步到磁盘,默认为异步写入。
调用DB中的成员函数,二者都通过封装的 Write 函数是实现。
virtual Status Write(const WriteOptions& options, WriteBatch* updates) = 0;
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {WriteBatch batch;batch.Put(key, value); // 将Key-Value加入WriteBatch中return Write(opt, &batch); // 传入Batch,调用Write函数
}Status DB::Delete(const WriteOptions& opt, const Slice& key) {WriteBatch batch;batch.Delete(key);return Write(opt, &batch);
}
- LevelDB采用批量写的方法。WriteBatch包含多个Key-Value的写操作。
WriteBatch::Put,WriteBatch::Delete
DB::Put将Key-Value加入到WriteBatch。之后正式执行时,多个线程提交的Key-Vaule会封装到一个WriteBatch下。
void WriteBatch::Put(const Slice& key, const Slice& value) {// 计算加入后当前Batch有多少对Key-Value,修改存储的rep_字符串中Key-Value对的个数WriteBatchInternal::SetCount(this, WriteBatchInternal::Count(this) + 1);rep_.push_back(static_cast<char>(kTypeValue)); // put操作的type加入队尾PutLengthPrefixedSlice(&rep_, key);PutLengthPrefixedSlice(&rep_, value);
}void WriteBatch::Delete(const Slice& key) {WriteBatchInternal::SetCount(this, WriteBatchInternal::Count(this) + 1);rep_.push_back(static_cast<char>(kTypeDeletion)); // delete操作的type加入队尾PutLengthPrefixedSlice(&rep_, key);
}
rep_为WriteBatch中存储的字符串,结构如下:
WriteBatch::rep_ :=sequence: fixed64 // WriteBatch中起始Key-Value的序列号count: fixed32data: record[count]
record :=kTypeValue varstring varstring // Ox00 |kTypeDeletion varstring // Ox01
varstring :=len: varint32data: uint8[len] // 实际存储的Key或Vallue
完成WriteBatch的写入就可以引用Batch,调用DBImpl::Write。
DBImpl::Write
Writer结构体
struct DBImpl::Writer {explicit Writer(port::Mutex* mu) : batch(nullptr), sync(false), done(false), cv(mu) {}Status status;WriteBatch* batch; // WriteBatchbool sync; // 默认为异步写入bool done; // 用于唤醒port::CondVar cv; // 条件变量
};
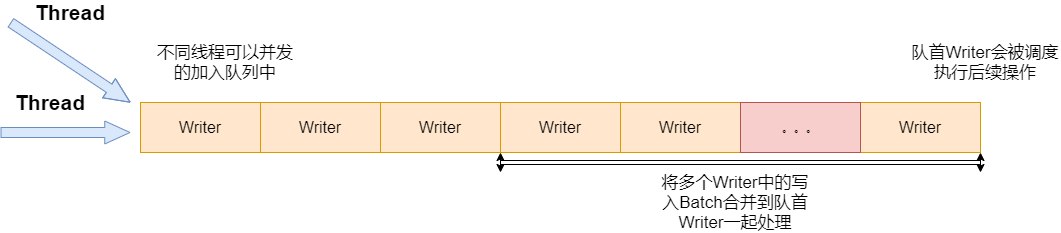
Write为写入操作的核心,需要用到一个双端队列:
std::deque<Writer*> writers_ GUARDED_BY(mutex_);
其形式如下图:

Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {Writer w(&mutex_);w.batch = updates; // 将Batch放入Writer结构体w.sync = options.sync;w.done = false;MutexLock l(&mutex_); // 原子操作,获得锁writers_.push_back(&w); // Writer结构体入队// 构造的Writer未被完成(可能被其它Writer执行)或者还未被调度,则等待while (!w.done && &w != writers_.front()) {w.cv.Wait();}if (w.done) { // writer在等待中被其它线程执行,则返回return w.status;}// LevelDB调度当前线程作为消费者,执行后续处理// 检查LevelDB当前的状态,执行相关逻辑,保证写操作正常执行,详细解释见后文Status status = MakeRoomForWrite(updates == nullptr);uint64_t last_sequence = versions_->LastSequence(); // DB已写入最大序列号Writer* last_writer = &w;if (status.ok() && updates != nullptr) { // nullptr batch表示进行compactionWriteBatch* write_batch = BuildBatchGroup(&last_writer); // 组合多个Writer,批量写入// WriteBatchInternal负责所有临时合并的batch中的所有操作,静态函数直接调用WriteBatchInternal::SetSequence(write_batch, last_sequence + 1); // 设置组合后的Batch的Writer header中的变量,设置大小为组合后的大小last_sequence += WriteBatchInternal::Count(write_batch); // 修改batch中当前最大序列号// 写日志 WAL Write Ahead Log{mutex_.Unlock(); // 解锁,保证其它线程可以向队列添加任务status = log_->AddRecord(WriteBatchInternal::Contents(write_batch)); // 写入日志bool sync_error = false;if (status.ok() && options.sync) {status = logfile_->Sync();if (!status.ok()) {sync_error = true;}}if (status.ok()) {status = WriteBatchInternal::InsertInto(write_batch, mem_); // 写入MemTable}mutex_.Lock();if (sync_error) {// 同步磁盘失败,后续的写入都失败RecordBackgroundError(status);}}if (write_batch == tmp_batch_) tmp_batch_->Clear(); // 清空临时batchversions_->SetLastSequence(last_sequence); // 写入成功,更新最后一个写入的kv序列号}// 将处理完的Writer设置为done,唤醒对应线程,离开队列while (true) {Writer* ready = writers_.front();writers_.pop_front();if (ready != &w) {ready->status = status;ready->done = true;ready->cv.Signal();}if (ready == last_writer) break;}// 通知新的队首Writer线程执行后续操作if (!writers_.empty()) {writers_.front()->cv.Signal();}return status;
}
- Writer可能被别的线程执行。此处为LevelDB的一个性能优化,根据一定规则将多个请求合并成一个请求,批量执行写入。
- DBImpl::MakeRoomForWrite()循环检查当前数据库状态:
- 如果当前LSM树的Level-0达到
kL0_SlowdownWritesTrigger阈值,延迟所有的Writer 1ms。交出CPU使得compaction线程可以被调度。 - 当前MemTable的大小未达到write_buffer_size,允许该次写。
- 如果MemTable达到阈值,且Immutabl MemTable仍然存在,挂牵当前线程等待
background_work_finished_signal_.Wait();,等到compaction结束,线程被唤醒。 - 如果当前LSM树的Level-0达到
kL0_StopWritesTrigger阈值,同样的线程被挂起,等地compaction后被唤醒。 - 上述条件都不满足,则MemTable已满,并且Immutable Table不存在,则将当前Memtable设未Immutable,删除过期的Log文件,生成新的MemTable和Log文件,同时触发compaction,允许写入。
c++ delete log_; delete logfile_; logfile_ = lfile; logfile_number_ = new_log_number; log_ = new log::Writer(lfile); imm_ = mem_; has_imm_.store(true, std::memory_order_release); // 使用写栅栏写入,当前存在immutable Table mem_ = new MemTable(internal_comparator_); WriteBatchInternal::InsertInto(write_batch, mem_);,向MemTable写入是不加锁的,不影响其它线程向队列添加任务。BuildBatchGroup会遍历所有队列中的Writer,将它们合并为一个Writer。合并的Batch会设置大小上限。但如果写入的为小文件,会降低Batch大小上限,避免延缓小文件的写入。当遍历队列的过程中,如果超过大小上限,则停止合并。
合并写入的数据大小,默认 max_size 是 1MB (1 << 20)。如果队首写请求的 size 比较小于128KB,则max_size 为 size + 128 KB。
- 以上操作通过多线程的写队列以及合并写的方法,简单高效的提升LevelDB性能。
WriteBatch::Iterate
该部分负责解码之前创建的临时batch,逐一写入MemTable中。
入口函数为 WriteBatchInternal::InsertInto(write_batch, mem_);。
继承WriteBatch下的Handler类,用于插入MemTable中。
class MemTableInserter : public WriteBatch::Handler {public:SequenceNumber sequence_;MemTable* mem_;void Put(const Slice& key, const Slice& value) override {mem_->Add(sequence_, kTypeValue, key, value); // 插入put操作sequence_++;}void Delete(const Slice& key) override {mem_->Add(sequence_, kTypeDeletion, key, Slice()); // 插入delete操作sequence_++;}
};Status WriteBatchInternal::InsertInto(const WriteBatch* b, MemTable* memtable) {MemTableInserter inserter;inserter.sequence_ = WriteBatchInternal::Sequence(b);inserter.mem_ = memtable;return b->Iterate(&inserter); // 调用Iterate逐一加入MemTable
}
Iterate逻辑如下,解码临时Batch。临时的Bach是由Writer队列的队首线程主导,之后的写入信息append到主导线程的Writer下,直接调用该线程WriteBatch下的Iterate就可以将所有Key-Value写入MemTable。
Status WriteBatch::Iterate(Handler* handler) const {Slice input(rep_); // 存储的插入信息在rep_中if (input.size() < kHeader) { // Batch大小异常return Status::Corruption("malformed WriteBatch (too small)");}input.remove_prefix(kHeader); // 移除Batch的header信息Slice key, value;int found = 0;while (!input.empty()) {found++;char tag = input[0]; // 获得当前Key-Value的操作类型input.remove_prefix(1);switch (tag) {case kTypeValue: // put操作if (GetLengthPrefixedSlice(&input, &key) &&GetLengthPrefixedSlice(&input, &value)) {handler->Put(key, value);} else {return Status::Corruption("bad WriteBatch Put");}break;case kTypeDeletion: // delete操作if (GetLengthPrefixedSlice(&input, &key)) {handler->Delete(key);} else {return Status::Corruption("bad WriteBatch Delete");}break;default:return Status::Corruption("unknown WriteBatch tag");}}if (found != WriteBatchInternal::Count(this)) {return Status::Corruption("WriteBatch has wrong count");} else {return Status::OK();}
}