微信如何上传wordpress/seo顾问什么职位
1.样本分类
假设一批患者使用同一种肿瘤药,一些人效果良好(response),而另一些人无明显疗效(not response)。故我们需要利用一些特征对患者进行分类(反应者 或 非反应者),使其接受针对性的接受治疗从而达到更好的疗效。基于实践,可能基因的表达特征有助于患者分类。
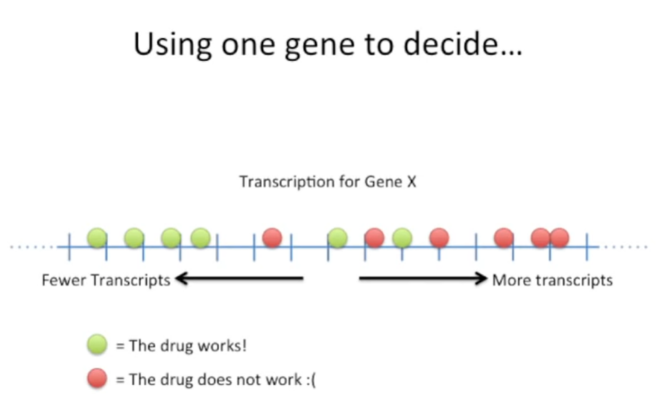
①仅使用一个基因的表达量对患者进行分类。该基因表达水平能较好地实现对肿瘤患者的分类,发现大部分反应者的该基因表达水平较低(左侧),大分部非反应者的该基因表达水平较高(右侧),但反应者与非反应者的该基于表达水平也有一定的重叠(中间)。
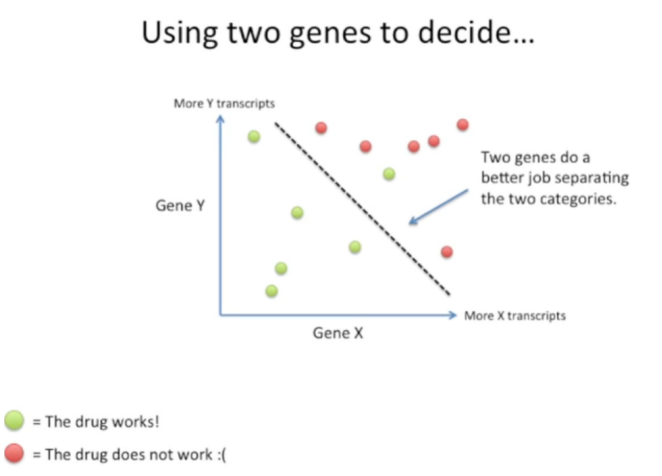
②使用两个基因的表达水平对患者进行分类。基于两个水平的分类能实现较好的肿瘤患者分类,大部分反应者对应gene X与Y的表达水平低,大分部非反应者对应的gene X与Y的表达水平较高,仅有绝少数患者的分类不准确。
③使用三个基因的表达水平对患者进行分类。在平面上很难辨认是否基于三个gene表达水平的分类能较好实现肿瘤患者分类。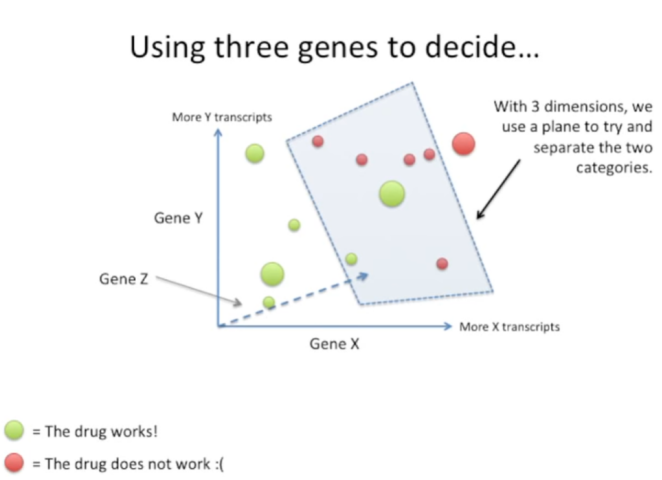
④基于4个或者4个及以上的基因表达水平对患者进行分类,常规的4维及4维以上的图形将会非常难辨别是否该方法能有效的实现患者分类。为了实现该目的,需要进行数据降维处理。但为了实现降维后,能够更加准确的进行数据分类,需要使用的方法是线性判别分析(Linear Discriminant Analysis,LDA)。
LDA: 同PCA一样,可以达到降低数据维度的效果。但其与PCA又有显著不同的区别,PCA主要是根据具有最大表达的基因寻找数据的主要成分,而LDA主要是基于如何能最大化不同类间的差异而进行数据降维,LDA的主要作用的实现数据分类。
2. LDA实现样本分类的原理
如下,将将2-D数据转换成1-D数据,从而实现数据降维和分类。
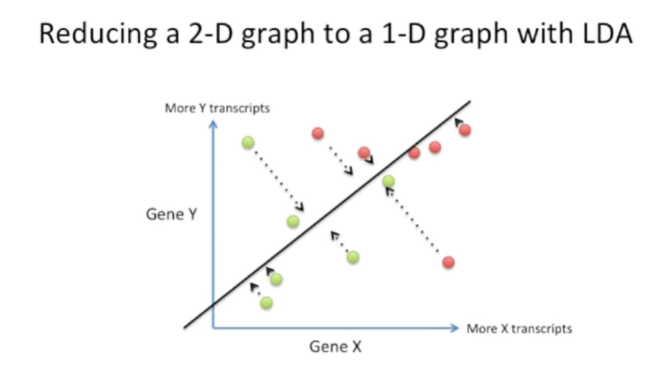
一个糟糕的做法是:忽略Y轴或X轴数据,将数据直接投射到X轴或Y轴。而LDA则提供了一个较好的思路,充分利用X轴与Y轴的数据,建立新的坐标轴(new axis),既实现数据维度的减少,又能实现对数据的良好分类。
2.1 LDA基于两个标准创建新坐标轴
2个类别的数据
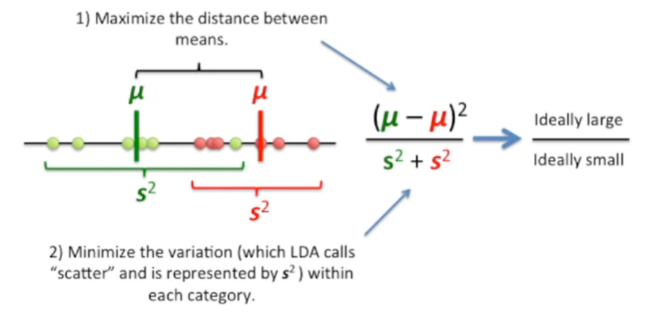
- 1.最大化不同类间的均值差异(μ1-μ2,用d表示不同类间的差异);
- 2.最小化同一类间的数据差异(scatter,用S2表示相同类间的分散情况)。
简单来说,就是不同类间的差异越大越好,相同类间的差异越小越好。 结合两个标准,用二者的比值进行量化,其值越大,说明分类的效果越好。
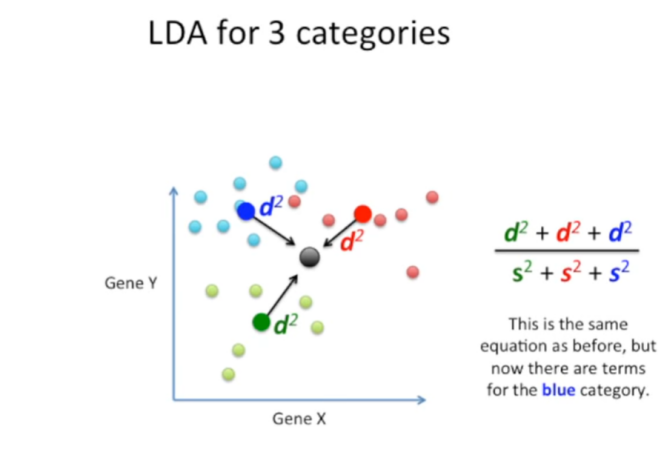
3个类别的数据
创建新坐标轴的2个标准是一致的,即均最大化不同类间的差异,最小化相同类间的差异。但是也有一些差别:
距离d的确定:不同类别数据至总数据质心的距离平方和为不同类间的距离。
数据的分类:因为需要将数据分为3类,故需要两条相互垂直的直线进行分类。
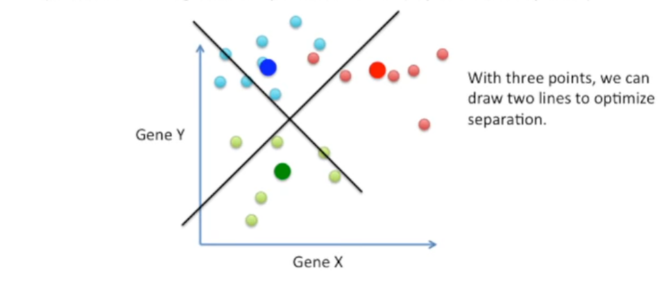
在仅有两个gene X与gene Y(两个变量的时候),新坐标轴上的数据未做降维处理,其与原数数据一致。
> 3个类别的数据
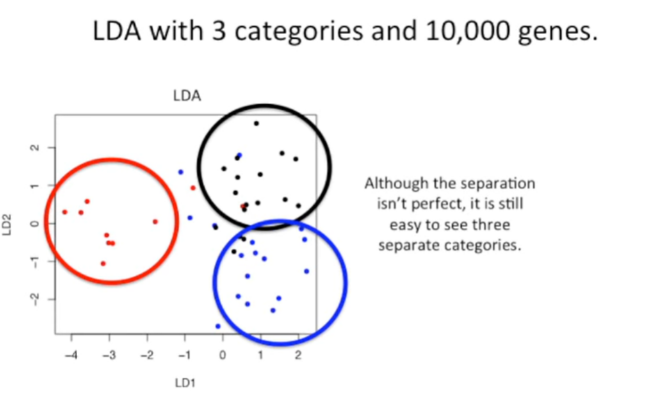
如果有10000个基因的表达数据,并基于这10000个基因的表达将样本分为3类。在这种情况下,就需要对数据进行降维处理。如下,利用LDA分析将10000个gene表达数据降至2维。尽管该分类的结果并不是十分完美,但是LDA也能较准确地将样本分为3类。
3. LDA与PCA的比较
3.1 LDA与PCA的差异
同前,仍利用10000个基因的表达数据进行LDA(左图)和PCA分析(右图)。因为PCA与LDA的主要目的不同,LDA的主要目的是实现降维和分类,故其能较好的实现数据分类;而PCA的主要目的是基于变化量最大的变量进行数据降维,故其在数据分类中的性能略差。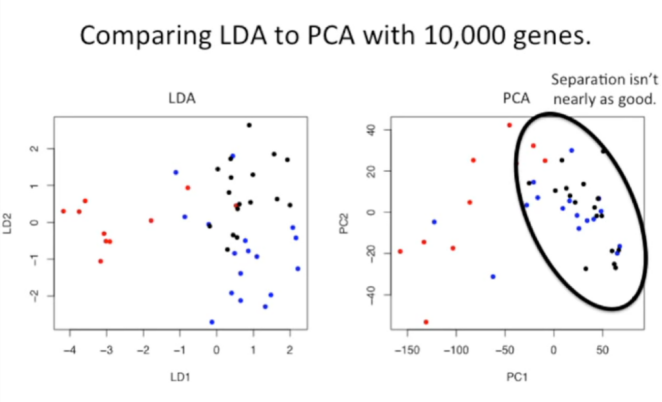
3.2 LDA与PCA的相似点
二者仅基于重要性对新坐标轴进行排序,均可基于原始数据创建新的坐标轴。
- LDA中(重点找不同类间的差异):LD1为解释不同分类间最大差异的坐标轴;LD1为解释不同分类间第二大差异的坐标轴...
- PCA中(重点找最大变异):PC1为解释数据最大变异的坐标轴;PC2为解释数据第二大变异的坐标轴...
二者均能实现多变量数据的降维。
- LDA: 目的是最优化不同类间的分类效果(实现对数据的最优分类)
- PCA:关注具有最大变异的变量(具有最大变异的某基因)
4. 总结
LDA与PCA均能实现数据降维,从而有利于后续的分析。虽然二者具有很多相似之处,但是二者实现不同的目的,故在选择数据降维时应结合自己的分析目的。本次笔记作为一个简单的介绍,如果想要更加深入的学习LDA,请参考更多的资源。
参考视频:https://www.youtube.com/watch?v=azXCzI57Yfc&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=29
编辑:吕琼
校审:罗鹏
