四川建设行政主管部门官方网站/风云榜小说排行榜
前言: 在公司用到了hadoop,于是想搭建一个hadoop环境.从慕课网上找了门 Hadoop基础知识与电商网站日志数据分析课学了下,这是笔记,供本人复习之用.
目录
第一章 环境介绍
第二章 Hadoop的安装
2.1 jdk安装
2.2 配置ssh登陆
2.2.1 配置让服务器能自己登陆自己
2.2.2 让本地能通过ssh远程连接阿里云服务器
2.3 hadoop的安装
第三章 启动停止hadoop
3.1 格式化文件系统
3.2 启动集群
3.2.1 通过进程开启
3.2.2 通过网站验证开启
3.3 停止集群
3.4 start与stop与hadoop-daemons.sh的关系
第四章 HDFS 命令行操作
第五章 hadoop文件的存储机制
第七章 API编程开发HDFS
7.1 配置maven库
7.2 远程操作阿里云中的hadoop
7.2.1 上传文件副本数为3
第一章 环境介绍
服务器版本centos7.3 在阿里云上买的,网络1M,单核,硬盘40GB,内存2G.
Hadoop:hadoop-2.6.0-cdh5.15.1
下载地址:http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.15.1.tar.gz
Hadoop说明:http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.15.1/
装hadoop环境需要先配ssh与安装jdk.
jdk:1.8
第二章 Hadoop的安装
2.1 jdk安装
https://blog.csdn.net/q610376681/article/details/83902538
最终java安装目录
![]()
2.2 配置ssh登陆
提醒:因为本人也是第一次配,可能有一些冗余操作,具体还是根据自己情况来,下面步骤只作为参考.
附上几个常用的操作文件命令:
清空文件内容:cat /dev/null > file_name
查找文件内的内容: 在命令行下输入“/关键字”
重启ssh服务:service sshd restart
2.2.1 配置让服务器能自己登陆自己
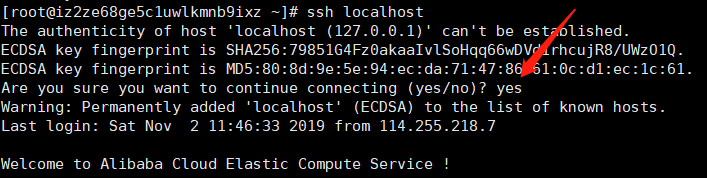
即ssh localhost能够成功.
可参考:https://blog.csdn.net/dongdong9223/article/details/81288378
值得注意的是,出现are you sure 的时候要输入yes,不是直接回车.
2.2.2 让本地能通过ssh远程连接阿里云服务器
1. 添加安全组规则:
https://help.aliyun.com/document_detail/25471.html?spm=a2c4g.11186623.2.14.d7837394Hhx40S#concept-sm5-2wz-xdb
2. 利用阿里云生成密钥对:
https://help.aliyun.com/document_detail/51793.html?spm=5176.2020520101.205.d51793.38cb4df5MgXi9M
3. 将密钥对放在ssh中,并在ssh规则中添加对应密钥:
https://blog.csdn.net/mier9042/article/details/82908774
我自己的环境:
my_computer2.pem阿里云生成的密钥
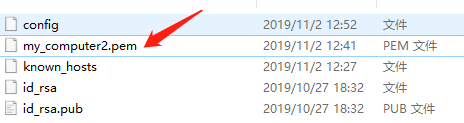
将密钥添加到ssh中

在~/.ssh/下配置config(这里没尝试之前的github还能否连上,网上说可能要在改点别的配置,因为网上教程一堆,就没写,有问题再搜就行.HostName是ip,Host是我的远程主机设置host名.

连接,注意连接的时候要加上用户名如root

2.3 hadoop的安装
1. 下载并解压到指定目录

解压后hadoop文件夹下目录说明:

2.将java配置写入/etc/hadoop/hadoop-env.sh,如果环境变量里配置了java_home,下图这样即可.

3. 配置默认的文件系统,切换到etc/hadoop/core-site.xml文件上,下面配置写入.
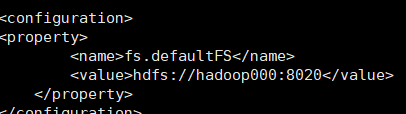
这里hadoop000要在host里进行配置
vi /etc/hosts
特别特别特别注意地址不能写127.0.0.1和云服务器的外网ip,这样都会导致导致等会儿不能在外网操作hadoop,要填写云服务器的内网地址.
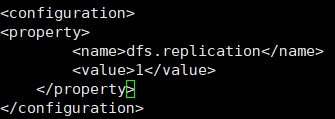
4. 配置副本系数.现在是单机,所以是1.切换到etc/hadoop/hdfs-site.xml文件上,下面配置写入.
5.修改临时文件夹位置,此参数不改可能不影响使用,但是机器重启以后可能有问题.此目录下存放hdfs将文件切成的块,重启时tmp目录会被清空,容易造成数据丢失.
![]()
所以我们将文件放在:
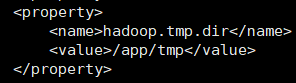
6. 配置dataNode,hadoop的结构是主从结构,一个nameNode带几个dataNode,所以我们要配置dataNode,打开/etc/hadoop中的slaves,修改其中的localhost为hadoop000,效果是一样的,但是有利于我们后期修改为多节点.
第三章 启动停止hadoop
3.1 格式化文件系统
注意:第一次执行的时候一定要格式化文件系统,不要重复执行
将hadoop配置到环境变量中以方便使用
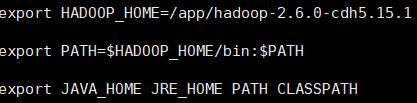
source /etc/profile 使其生效.
格式化文件系统
hdfs namenode -format如下显示说明格式化成功.

3.2 启动集群
切换到sbin中启动下图所示文件并启动

启动记录:

3.2.1 通过进程开启
验证,当出现下图所示(除jps)即为成功,数字可以不一样,那是pid.
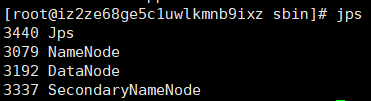
如果发现哪个进程不存在,去logs文件夹中找其中log文件.

3.2.2 通过网站验证开启
访问ip:50070也可以校验是否成功,如果连接不上,考虑防火墙的问题,我这里用的是阿里云,打开下面的防火墙,即访问成功.
![]()

3.3 停止集群
在sbin目录下输入如下命令停止
./stop-dfs.sh
3.4 start与stop与hadoop-daemons.sh的关系

第四章 HDFS 命令行操作
输入hadoop,会出现提示

看到fs是对文件系统进行操作,输入hadoop fs,看到一堆对文件的操作.将尝试较为常用的.

首先查看hdfs中现存的文件
hadoop fs -ls /发现空空如野,因为刚创建.
具体的命令实践:https://www.jianshu.com/p/ba8e047a2216
第五章 hadoop文件的存储机制
当我们将大于block的文件放入hdfs中去时,其会被拆成多个块.比如我们将jdk放入hdfs中.
![]()
因为一个block是128M,我们的jdk是182M,可以看到jdk被分成了两块存储到hdfs中.大小加起来刚好为182M.
![]()


我们去之前配置的/app/tmp下找,经过很多级目录可以找到这两个块.
并且cat之后也可以进行使用(这是视频上的块,我嫌麻烦没自己敲).

第七章 API编程开发HDFS
建立maven项目.
在本地中配置hosts地址如下,我本地是windows,路径为C盘 - > Windows - > System32 - > drivers-> etc - > hosts文件

7.1 配置maven库
<!--有些包要到这个库去下-->
<repositories><repository><id>cloudera</id><url>https://repository.cloudera.com/artifactory/cloudera-repos</url></repository></repositories>
<!--引入的包-->
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.0-cdh5.15.1</version></dependency>7.2 远程操作阿里云中的hadoop
列举了几个常用的,其它的api可以网上搜搜,大同小异.
public class HDFSApp {public static final String HDFS_PATH = "hdfs://59.110.164.62:8020";FileSystem fileSystem = null;Configuration configuration = null;@Beforepublic void setUp() throws URISyntaxException, IOException, InterruptedException {System.out.println("---setUp---");configuration = new Configuration();//设置true表示让它返回的是host名字,而不是地址,如果不设置//会返回内网地址导致失败.configuration.set("dfs.client.use.datanode.hostname", "true");fileSystem = FileSystem.get(new URI(HDFS_PATH),configuration,"root");}/*** 创建hdfs文件夹* * @param * @return **/@Testpublic void mkdir() throws IOException {fileSystem.mkdirs(new Path("/hdfsapi/test"));}/*** 从hadoop中下载文件* * @param * @return **/@Testpublic void text() throws IOException {FSDataInputStream in = fileSystem.open(new Path("/README.txt"));System.out.println("成功获取输入流");IOUtils.copyBytes(in,System.out,1024);}/*** 向hadoop中上传文件.* * @param * @return **/@Testpublic void create() throws IOException {FSDataOutputStream out = fileSystem.create(new Path("/hdfsapi/test/a.txt"));out.writeUTF("hello zhangchen");out.flush();out.close();}/*** 关闭连接* * @param * @return **/@Afterpublic void tearDown(){configuration = null;fileSystem = null;System.out.println("---tearDown---");}
}7.2.1 上传文件副本数为3
同时值得注意的是我们上传的文件副本数为3,和我们在本地配置的1的副本数不一样,因为它上传时读取的是默认配置,可以在dependency下的hdfs依赖中的xml文件中找到.
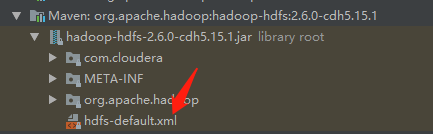
可以看到副本数为3
