哪里能找到免费网站发布新闻最快的网站
1 多项式回归
1.1 介绍
多项式回归,用来对非线性数据集进行处理,例如二次函数。
1.2 代码
1)多项式回归和线性回归比较
例:y=0.5x2+x+2+noisey=0.5{ x }^{ 2 }+x+2+noisey=0.5x2+x+2+noise
import numpy as np
import matplotlib.pyplot as plt# 准备数据
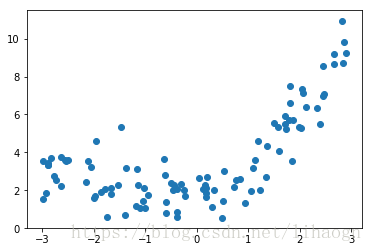
x=np.random.uniform(-3,3,size=100)
xx=x.reshape(-1,1)
y=0.5*x**2+x+2+np.random.normal(0,1,size=100)plt.scatter(x,y)
plt.show()
# 线性回归
from sklearn.linear_model import LinearRegressionlin_reg=LinearRegression()
lin_reg.fit(xx,y)
y_predict=lin_reg.predict(xx)plt.scatter(x,y)
plt.plot(x,y_predict,color='r')
plt.show()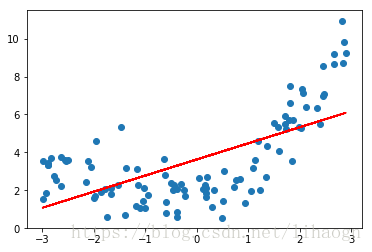
# 多项式回归,添加一个特征
xx2=np.hstack([xx,xx**2])lin_reg2=LinearRegression()
lin_reg2.fit(xx2,y)
y_predict2=lin_reg2.predict(xx2)plt.scatter(x,y)
plt.plot(np.sort(x),y_predict2[np.argsort(x)],color='r')
plt.show()
# 多项式的系数
lin_reg2.coef_ # array([0.95895082, 0.52687416])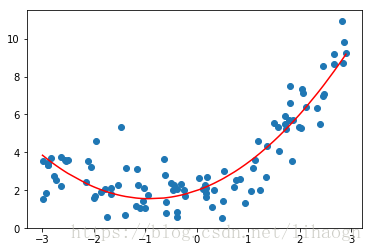
2 模型泛化相关
2.1 模型复杂度曲线
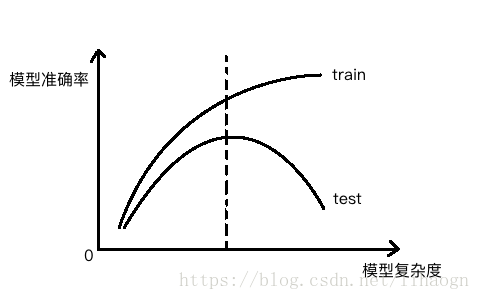
测试数据集的意义:寻找泛化能力最好的地方。
2.2 学习曲线
含义:随着训练样本的逐渐增多,算法训练出的模型的表现能力。
问题:特定的测试数据集出现过拟合的情况。
解决方案:将样本数据集分为:训练、验证、测试数据集。
- 训练数据集 -> 用来产生模型
- 验证数据集 -> 调整超参数使用的数据集
- 测试数据集 -> 衡量最终模型性能的数据集
代码演示:
import numpy as np
import matplotlib.pyplot as plt# 准备数据
x=np.random.uniform(-3,3,size=100)
X=x.reshape(-1,1)
y=0.5*x**2+x+2+np.random.normal(0,1,size=100)plt.scatter(x,y)
plt.show()

# 学习曲线
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_errorX_train,X_test,y_train,y_test=train_test_split(X,y,random_state=666)train_score=[]
test_score=[]
for i in range(1,76):lin_reg=LinearRegression()lin_reg.fit(X_train[:i],y_train[:i])# 训练集的预测值y_train_predict=lin_reg.predict(X_train[:i])train_score.append(mean_squared_error(y_train[:i],y_train_predict))# 测试集的预测值y_test_predict=lin_reg.predict(X_test)test_score.append(mean_squared_error(y_test,y_test_predict))plt.plot([i for i in range(1,76)],np.sqrt(train_score),label='train')
plt.plot([i for i in range(1,76)],np.sqrt(test_score),label='test')
plt.legend()
plt.show()

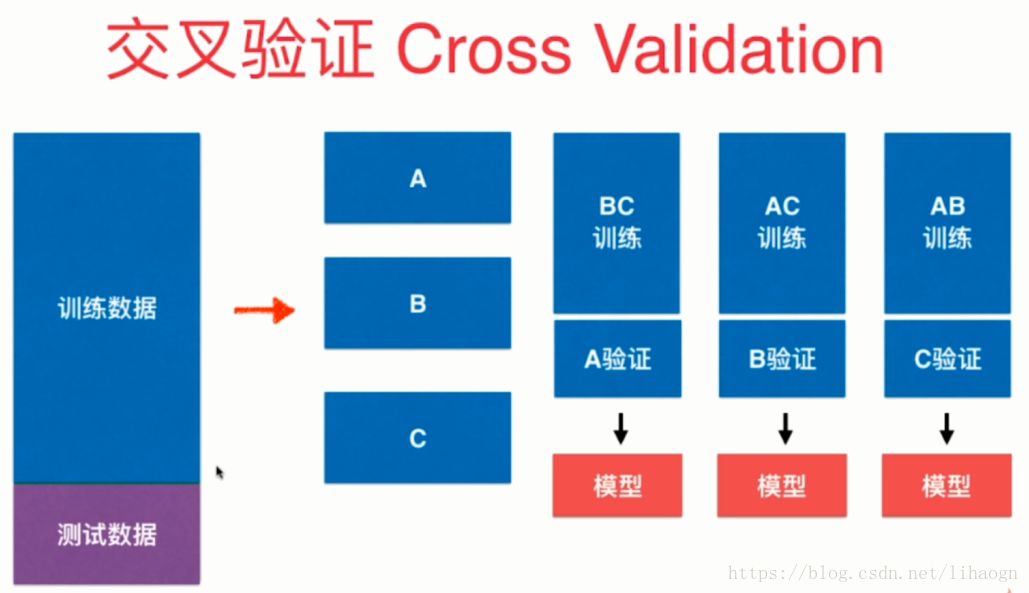
2.3 交叉验证 (应对验证数据集中有极端值出现的情况)
将下图中n个模型的均值作为结果调参。
代码演示:
import numpy as np
from sklearn import datasets# 加载数据集
digits=datasets.load_digits()
X=digits.data
y=digits.target# 测试 train_test_split
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifierX_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.4,random_state=666)
best_score,best_p,best_k=0,0,0
for k in range(2,11):for p in range(1,6):knn_clf=KNeighborsClassifier(weights='distance',n_neighbors=k,p=p)knn_clf.fit(X_train,y_train)score=knn_clf.score(X_test,y_test)if score>best_score:best_score,best_p,best_k=score,p,kprint("best k= ",best_k)
print("best p= ",best_p)
print("best score= ",best_score)
结果:
best k= 3
best p= 4
best score= 0.9860917941585535
# 使用交叉验证
from sklearn.model_selection import cross_val_scoreknn_clf=KNeighborsClassifier()
cross_val_score(knn_clf,X_train,y_train) # 生成了三个模型的评分
# > array([0.98895028, 0.97777778, 0.96629213])
best_score,best_p,best_k=0,0,0
for k in range(2,11):for p in range(1,6):knn_clf=KNeighborsClassifier(weights='distance',n_neighbors=k,p=p)# 交叉验证scores=cross_val_score(knn_clf,X_train,y_train)score=np.mean(scores)if score>best_score:best_score,best_p,best_k=score,p,kprint("best k= ",best_k)
print("best p= ",best_p)
print("best score= ",best_score)
'''
> best k= 2
> best p= 2
> best score= 0.9823599874006478
'''
# 获得最佳的knn分类器
best_knn_clf=KNeighborsClassifier(weights='distance',n_neighbors=2,p=2)
best_knn_clf.fit(X_train,y_train)
best_knn_clf.score(X_test,y_test)
# > 0.980528511821975
2.4 偏差与方差
模型误差=偏差+方差+不可避免误差
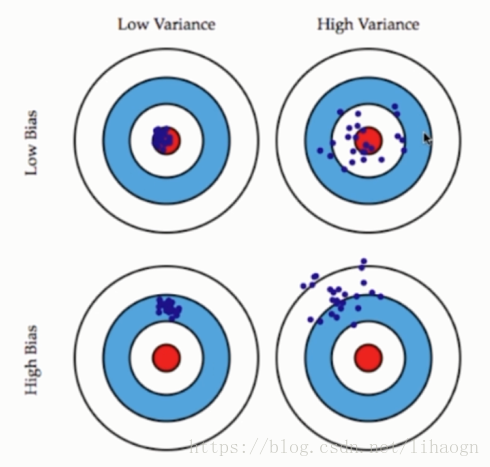
导致偏差的主要原因:(欠拟合)
- 对问题本身的假设不正确,如:非线性数据使用线性回归。
与方差相关:(过拟合)
- 数据的一点点扰动都会较大地影响模型。
- 通常原因,使用的模型太过复杂,如:高阶多项式回归。
注意:
- 有一些算法天生是高方差的算法,如kNN。非参数学习通常都是高方差算法,因为不对数据进行任何假设。
- 有一些算法天生是高偏差算法,如线性回归。参数学习通常都是高偏差算法,因为对数据具有极强的假设。
- 偏差和方差通常是矛盾的。降低偏差,会提高方差;降低方差,会提高偏差。
- 机器学习的主要挑战来自于方差。
解决高方差(过拟合)的通常手段:
- 降低模型复杂度
- 减少数据维度;降噪
- 增加样本数
- 使用验证集
- 模型正则化
2.5 模型正则化(Regularization):限制参数的大小
目标:使 ∑i−1m(y(i)−θ0−θ1x1(i)−θ2x2(i)−⋯−θnxn(i))2\sum _{ i-1 }^{ m }{ { ({ y }^{ (i) }-{ \theta }_{ 0 }-{ \theta }_{ 1 }{ x }_{ 1 }^{ (i) }-{ \theta }_{ 2 }{ x }_{ 2 }^{ (i) }-\cdots -{ \theta }_{ n }{ x }_{ n }^{ (i) }) }^{ 2 } }∑i−1m(y(i)−θ0−θ1x1(i)−θ2x2(i)−⋯−θnxn(i))2 尽肯能小
即,使 J(θ)=MSE(y,y^;θ)J(\theta )=MSE(y,\hat { y } ;\theta )J(θ)=MSE(y,y^;θ) 尽肯能小
1 岭回归(Ridge Regression)
目标:使 J(θ)=MSE(y,y^;θ)+α12∑i=1nθi2J(\theta )=MSE(y,\hat { y } ;\theta )+\alpha \frac { 1 }{ 2 } \sum _{ i=1 }^{ n }{ { \theta }_{ i }^{ 2 } }J(θ)=MSE(y,y^;θ)+α21∑i=1nθi2 尽肯能小
代码演示:
import numpy as np
import matplotlib.pyplot as plt# 准备数据
np.random.seed(42)
x=np.random.uniform(-3.0,3.0,size=100)
X=x.reshape(-1,1)
y=0.5*x+3+np.random.normal(0,1,size=100)plt.scatter(x,y)
plt.show()

from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errordef PolynomialRegression(degree):return Pipeline([("poly",PolynomialFeatures(degree=degree)),("std_scaler",StandardScaler()),("lin_reg",LinearRegression())])
# 分割数据集
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=666)
# 拟合
poly_reg=PolynomialRegression(degree=20)
poly_reg.fit(X_train,y_train)
# 预测
y_predict=poly_reg.predict(X_test)
# 使用多项式回归的均方误差
mean_squared_error(y_test,y_predict) # result:167.94010862165914# 封装绘图函数
def plot_model(model):x_plot=np.linspace(-3,3,100).reshape(100,1)y_plot=model.predict(x_plot)plt.scatter(x,y)plt.plot(x_plot[:,0],y_plot,color='r')plt.axis([-3,3,0,6])plt.show()plot_model(poly_reg)
'''
从图中可以看出模型过拟合了
'''

# 岭回归
from sklearn.linear_model import Ridgedef RidgeRegression(degree,alpha):return Pipeline([("poly",PolynomialFeatures(degree=degree)),("std_scaler",StandardScaler()),("ridge_reg",Ridge(alpha=alpha))])ridge1_reg=RidgeRegression(20,0.0001)
ridge1_reg.fit(X_train,y_train)y1_predict=ridge1_reg.predict(X_test)
mean_squared_error(y_test,y1_predict) # result:1.323349275417008plot_model(ridge1_reg)
'''
曲线比之前的要平滑一些
均方差也比之前小很多
'''

# 更改alpha值,再次拟合
ridge2_reg=RidgeRegression(20,1)
ridge2_reg.fit(X_train,y_train)y2_predict=ridge2_reg.predict(X_test)
mean_squared_error(y_test,y2_predict) # result:1.1888759304218446plot_model(ridge2_reg)
'''
曲线更加平滑
均方差更小
'''

2 LASSO Regression
- LASSO趋向于使得一部分theta值变为0,所以可作为特征选择用。
目标:使 J(θ)=MSE(y,y^;θ)+α∑i=1n∣θi∣J(\theta )=MSE(y,\hat { y } ;\theta )+\alpha \sum _{ i=1 }^{ n }{ \left| { \theta }_{ i }^{ } \right| }J(θ)=MSE(y,y^;θ)+α∑i=1n∣θi∣ 尽肯能小
代码示例:
from sklearn.linear_model import Lassodef LassoRegression(degree,alpha):return Pipeline([("poly",PolynomialFeatures(degree=degree)),("std_scaler",StandardScaler()),("lasso_reg",Lasso(alpha=alpha))])lasso1_reg=LassoRegression(20,0.01)
lasso1_reg.fit(X_train,y_train)y1_predict=lasso1_reg.predict(X_test)
mean_squared_error(y_test,y1_predict) # result:1.1496080843259966plot_model(lasso1_reg)

lasso2_reg=LassoRegression(20,0.1)
lasso2_reg.fit(X_train,y_train)y2_predict=lasso2_reg.predict(X_test)
mean_squared_error(y_test,y2_predict) # result:1.1213911351818648plot_model(lasso2_reg)

# 更改alpha值再拟合
lasso3_reg=LassoRegression(20,1)
lasso3_reg.fit(X_train,y_train)y3_predict=lasso3_reg.predict(X_test)
mean_squared_error(y_test,y3_predict) # result:1.8408939659515595plot_model(lasso3_reg) # 正则化过度

3 弹性网(Elastic Net)
J(θ)=MSE(y,y^;θ)+rα∑i=1n∣θi∣+1−r2α∑i=1nθi2J(\theta )=MSE(y,\hat { y } ;\theta )+r\alpha \sum _{ i=1 }^{ n }{ \left| { \theta }_{ i }^{ } \right| } +\frac { 1-r }{ 2 } \alpha \sum _{ i=1 }^{ n }{ { { \theta }_{ i }^{ 2 } } }J(θ)=MSE(y,y^;θ)+rα∑i=1n∣θi∣+21−rα∑i=1nθi2